Chapter 12
From Pilot to Production – Implementing Data Science Projects
"In the commercial use of AI, the ‘rocket science’ has turned out to be the easy part. The challenge is getting it launched." — Eric Siegel
Data science initiatives often shine in controlled pilot projects but stumble when scaling to real-world production. This chapter examines why so many promising proofs of concept never achieve broad deployment, and how organizations can bridge that “last mile” from pilot to production. We explore the common business, technical, and organizational hurdles that hinder scaling, and outline strategies to overcome them. Through insights and examples from finance, healthcare, manufacturing, supply chain, distribution, and logistics, readers will learn how to align projects with business goals, build a strong data foundation, manage change, and institute ongoing model governance. The key takeaway is that success in enterprise AI requires not just building a good model, but integrating it into people, processes, and strategy to deliver lasting business value.
12.1. Data Science Implementation Challenges
Data science today has evolved beyond the myth of a lone genius in a corner office building fancy algorithms that magically solve business problems. While the “rocket science” of constructing models can be impressive, it often proves to be the simplest part of a much larger and more complex equation (Machine Learning Times). Many organizations produce elegant prototypes in controlled environments—pilot systems that forecast demand, spot fraud, or triage customer tickets with uncanny accuracy—only to watch these efforts sputter when they attempt to scale across the enterprise. This phenomenon is known colloquially as the “last mile” problem. It describes that painful gap between having a flashy proof-of-concept and realizing sustained, measurable impact in everyday business operations (RAND).
Much like how launching a spacecraft requires more than just a brilliant design on paper, successful data science initiatives demand more than just high model accuracy. They require practical integration with legacy systems, cultural acceptance among end-users, consistent data pipelines, and buy-in from executives who control the purse strings. The sobering truth is that while data science has grown more sophisticated—incorporating machine learning, deep learning, and even real-time analytics—the majority of commercial projects still fail to achieve tangible returns on investment (RAND). In fact, multiple industry analyses estimate that 75–85% of AI projects never reach full production or meaningful scale (Harvard Business School; Everyday AI).
Understanding why these failures occur is the first step toward reversing the trend. It is also an essential topic for executives striving to harness data science for strategic advantage. From data collection and cleaning to enterprise-wide deployment and maintenance, each stage carries its own risks, technical complexities, and cultural barriers. When these challenges remain unaddressed, they can nullify even the most promising AI breakthroughs.
Studies across finance, healthcare, and manufacturing reveal a stark pattern: prototypes that look great in a lab setting end up languishing on a shelf, never adopted broadly (RAND). As a leader, you might wonder: “Aren’t we investing millions in data science talent and state-of-the-art infrastructure? How are we still not seeing results?” The reasons are multifaceted. Some revolve around poor alignment with business needs, some stem from technical gaps, and others reflect deep-seated organizational inertia.
On the business side, one of the most common roadblocks is misalignment between the AI solution and real commercial objectives (RAND). Perhaps a data science team becomes enamored with an advanced model architecture that optimizes an obscure metric. Meanwhile, executives remain unimpressed because it fails to address the pressing issues of customer churn or slow inventory turnover. Alternatively, leadership might not have established clear success criteria at the project’s outset, leading to confusion when the pilot ends and the time arrives to invest in large-scale rollout. Without a credible forecast of ROI or a direct tie to corporate goals, many AI projects die quietly under the weight of indecision.
Technical hurdles are equally disruptive. The larger and more diverse the data, the more complicated it can be to maintain consistent quality or to manage data pipelines in real time. A machine learning model that runs smoothly on a data scientist’s laptop can choke once it encounters high-volume, high-velocity production environments that demand near-zero latency (RAND). Legacy systems often make matters worse, lacking the APIs, storage capacity, or computational power to integrate advanced analytics in a user-friendly way. Enterprises may discover too late that scaling the model means rewriting significant portions of their backend infrastructure—a time-consuming, resource-intensive process that was never budgeted for.
Finally, the organizational dimension often proves the biggest hurdle. Technology might be the shiny surface of AI, but culture, politics, and processes determine whether solutions will take root. Resistance can arise from employees who worry about job security or who distrust “black box” models. There may be insufficient collaboration among data scientists, IT staff, and domain experts, each speaking different jargon and protective of their own priorities. Surveys of senior executives repeatedly confirm that cultural and organizational barriers, rather than raw technical limits, dominate the list of obstacles to becoming truly data-driven (Why Culture Is the Greatest Barrier to Data Success).
The term “last mile” originally described challenges in industries like telecommunications and logistics, where the infrastructure can get a product (electricity, internet, or a package) most of the way but fails in the final delivery step to the end user. In data science, this is precisely what happens when a strong prototype cannot transition into a live environment in which decision-makers, front-line employees, or customers interact with it daily. It may look fantastic in offline tests, but somewhere between the lab and everyday operations, it stalls.
A typical example involves the healthcare sector, where even clinically accurate diagnostic algorithms face skepticism or confusion among medical professionals (PMC). If the workflows or incentives of the hospital do not support or reward the use of these new AI tools, doctors may sideline them. The root cause is rarely the algorithm’s accuracy alone. Instead, it is the broader ecosystem: how the tool integrates with medical record systems, how quickly it can deliver results, how staff trust or perceive it, and whether it genuinely streamlines or complicates the physician’s day. Without addressing these pragmatic factors, the model remains a technical triumph that no one uses.
In another illustration, consider a multinational bank that invests in an advanced fraud detection model but provides no training to branch employees. The staff lacks understanding of the model’s output and sees it as yet another system generating cryptic alerts. Faced with unfamiliar technology, employees ignore or override these warnings, and fraudulent transactions slip by. When top management checks the system’s adoption rate, they discover abysmal usage. The bank ends up paying for advanced analytics that gather digital dust, offering no return on the initial investment.
Many data science enthusiasts joke that the real challenge is not the modeling but “getting it across the finish line without the wheels falling off.” This sentiment captures the sobering realization that building a functional algorithm is only a fraction of the work. Operationalizing AI requires embedding the model into workflows, connecting it to relevant data sources, ensuring real-time performance (if needed), training users, and establishing accountability for outcomes. These tasks demand the specialized skill sets of data engineers, software developers, QA testers, project managers, and sometimes compliance officers.
Where a pilot program might rely on manual data extraction and a single data scientist controlling the environment, an enterprise deployment necessitates robust MLOps—a discipline paralleling DevOps but tailored to machine learning. MLOps covers automated data pipelines, continuous integration and deployment of models, monitoring for data drift, and version control to enable easy rollbacks when things go wrong (Machine Learning Times). Companies that fail to invest in these foundational elements discover they cannot scale their prototypes effectively, regardless of how promising the pilot results looked.
Moreover, the actual mechanics of change management can be sorely underestimated. A sudden pivot to an AI-driven approach can alter job roles, performance metrics, and even the corporate structure. For instance, if your AI system automates credit decisions, the role of loan officers shifts from a decision-maker to a reviewer, potentially causing role confusion or resentment. Without a well-defined plan for training, role redefinition, and incentive alignment, the odds are high that your AI model will gather dust instead of driving better lending outcomes.
Consider a hypothetical consumer goods company that invests heavily in a real-time analytics system to optimize inventory replenishment across its retail chain. The data science team builds a complex demand-forecasting model, touting 95% accuracy in lab tests. The pilot in one region confirms savings on supply chain costs. Emboldened, leadership instructs the entire chain to adopt the model.
Implementation soon unravels. Some regional warehouses lack the bandwidth to process data updates quickly, leading to sporadic coverage. Store managers, used to a manual ordering process, continue ordering the old way because they find the new interface confusing. Meanwhile, the model’s predictions degrade as new data sources—never included in the pilot—introduce unforeseen anomalies. Halfway through the rollout, the company realizes it lacks a standardized training program or an adequate feedback mechanism to refine forecasts. Accuracy plummets, inventory mismatch surges, and the CFO halts the project, labeling it a “waste of budget.”
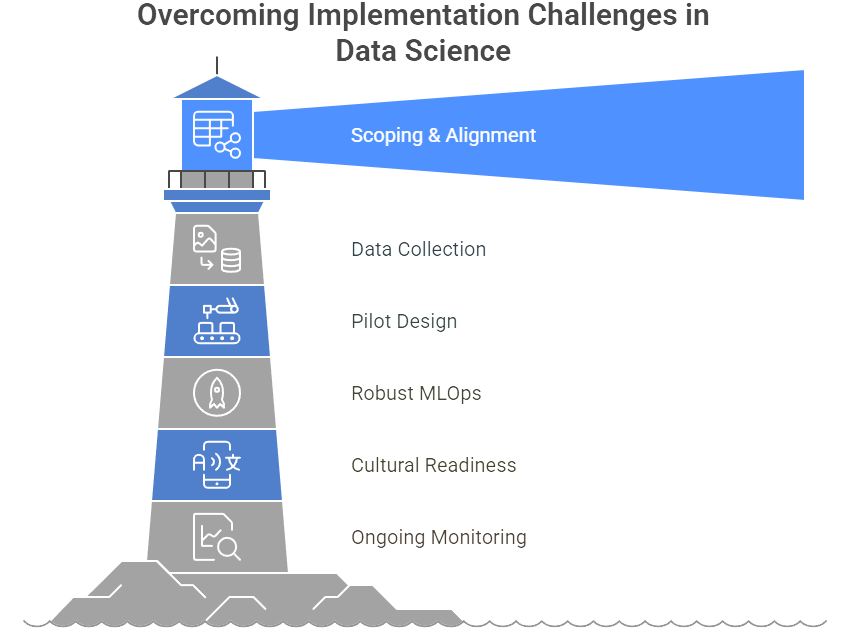
Figure 1: Illustration of he path through data science implementation challenges, guiding the projects through potential pitfalls by emphasizing key areas like robust MLOps and ongoing monitoring. (Image by Napkin).
When analysts examine this fiasco, they see not a failure of the algorithm itself (which was presumably well-designed) but a breakdown in cross-functional coordination, platform readiness, and end-user adoption. The company’s oversight body never set up performance metrics beyond the pilot, so it could not systematically track or fix issues as they emerged. This is a textbook example of the last mile problem: the pilot was fine, but the enterprise-wide execution was an afterthought.
Recognizing these implementation challenges is the first step to overcoming them. Successful organizations approach data science not as a series of one-off experiments but as a strategic, multi-stage process involving:
Proper scoping and alignment with critical business objectives.
High-quality data collection, cleaning, and integration early in the project timeline.
Pilot designs that incorporate production-like conditions rather than artificially controlled labs.
Robust MLOps or engineering frameworks that enable smooth deployment.
Cultural readiness, including training and role definition so that AI complements rather than disrupts employees.
Ongoing monitoring and refinement to keep the model aligned with evolving market realities.
Cultivating a culture where data scientists, domain experts, IT staff, and executives collaborate routinely is a potent antidote to many typical failure points. When leadership demands accountability, sets realistic goals, invests in the necessary infrastructure, and fosters trust among end-users, the probability of scaling a successful prototype skyrockets (Machine Learning Times).
Data science in commercial settings offers extraordinary potential: from real-time fraud detection to personalized medical recommendations and just-in-time supply chain optimization. Yet the track record of AI implementations remains sobering, with a majority of projects failing to cross the threshold into enterprise-wide adoption and tangible ROI (Harvard Business School). The underlying causes typically revolve around mismatched goals, technical integration headaches, and, perhaps most crucially, organizational inertia.
Executives determined to break the cycle must plan for more than just the next fancy deep learning model. They need to orchestrate the entire environment in which that model will operate, ensuring that data pipelines, user training, business processes, and cultural acceptance all align. This is not rocket science—ironically, the “rocket science” can be the easy part—but it does require an honest recognition that advanced analytics thrive in an ecosystem prepared to embrace them. The next sections delve deeper into structuring these ecosystems, addressing everything from stakeholder collaboration to maintenance protocols, so that data science can deliver lasting commercial impact rather than fleeting pilot success.
12.2. Building The Right Foundations for Success
Achieving real commercial impact with data science requires considerably more than throwing algorithms at a problem and hoping for the best. Too often, teams create impressive prototypes with modern techniques like neural networks or gradient boosting, only to watch those efforts buckle under the weight of insufficient data, poor organizational alignment, or an absence of clear business goals (Digital CxO). It is like building a sleek sports car without an engine: it might look good on the showroom floor, but it will not take anyone anywhere. The groundwork for a data science initiative should be as deliberate and robust as the analytics itself. When organizations skimp on these fundamentals, they risk adding their project to the long—and rather embarrassing—list of AI ventures that stall after promising pilots.
Organizations love to dream big with artificial intelligence: detecting fraud, predicting customer churn, or optimizing supply chains. Yet many projects fail before they even begin simply because no one bothered to define why they are doing it. A data science team might chase fancy metrics or build cutting-edge natural language models without tying the effort back to any pressing business need (RAND). This approach usually ends with executives wondering why they funded yet another vanity project that solves no real pain point. It is crucial, therefore, to start with a sharply defined objective.
The objective must be specific and measurable. For instance, a retail giant might aim to reduce out-of-stock events by 30% within six months by leveraging predictive analytics in its inventory system. A hospital might pursue a 20% reduction in emergency room wait times by implementing a triage model that flags critical patients more efficiently. Establishing these targets forces everyone—from data scientists to frontline staff—to focus on an outcome that matters to the broader organization (RAND). Clarity also helps avoid the dreaded “pilot purgatory,” where teams build endless proofs of concept but never see actual ROI (Advice on how to avoid pilot purgatory with AI rollout).
This clarity in objective-setting often requires translating business language into model-related metrics. If the aim is to “reduce machine downtime,” then the data science project might target an early fault-detection model with 90% precision in identifying failures before they happen. If the goal is “cutting customer churn,” then the team might set a recall threshold so that at least 90% of customers at risk of leaving receive an intervention. In short, an upfront focus on business context helps everyone resist the temptation of chasing shiny new AI trends that do not address real-world challenges.
Even the most elegant deep learning model is just a curiosity if it never leaves the data scientist’s Jupyter notebook. Successful data science deployments emerge from collaborative efforts spanning IT, data engineers, domain experts, operations, compliance, and more (Digital CxO). Each group offers insights that can make or break a project’s viability. IT pros know the quirks of legacy systems and can spot potential integration nightmares early. Domain experts clarify the nuances of real-world workflows, preventing wild misinterpretations of the data. Compliance teams ensure that sensitive data usage aligns with regulations, so the final model does not ignite a legal bonfire.
Strong collaboration goes beyond a few handoff meetings. It may involve forming an interdisciplinary AI working group or “Center of Excellence” that meets regularly to align goals and solve emerging problems. It also demands a degree of humility on all sides. Data scientists must respect the practical constraints of production systems and the importance of domain-specific expertise. Meanwhile, business stakeholders need to understand the time and complexity inherent in building and refining robust models. This cross-pollination of perspectives often reveals hidden synergies or bottlenecks, allowing the initiative to evolve in a direction that is both technically feasible and strategically valuable.
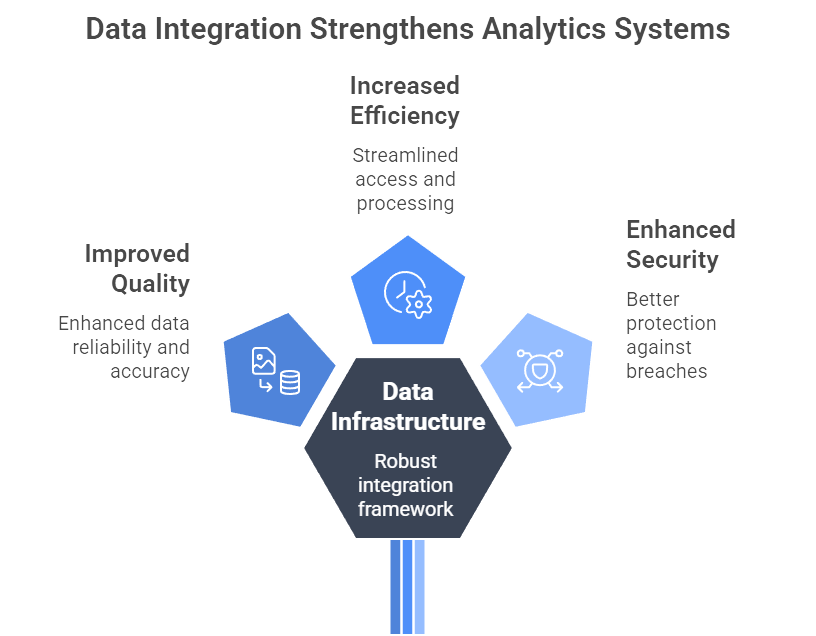
Figure 2: Illustration of how a robust data infrastructure, powered by effective integration, elevates analytics systems with improved quality, efficiency, and fortified security. (Image by Napkin).
Even the world’s best data scientists will struggle if the underlying data infrastructure resembles a house of cards. In many organizations, data is fragmented across dozens of silos, each with its own format, governance policy, or access restrictions (Why Big Data Science & Data Analytics Projects Fail). Without a robust plan for data integration, quality checks, and security measures, a pilot that looks glorious in a controlled sandbox could stumble when confronted with real-time production demands.
Data readiness often begins with an honest inventory of what data the company has, its quality, and any regulatory constraints. Is the data labeled consistently, or full of duplicates and missing values? Are there processes in place to regularly update the dataset? How will personally identifiable information be handled to comply with privacy laws such as GDPR or HIPAA? A startling number of AI projects stall out upon discovering that data has not been collected in a manner suitable for modeling, or that it requires months of cleaning and transformation to be even halfway usable (IBM).
To tackle these issues, organizations increasingly adopt cloud-based data architectures and scalable pipelines that can handle large volumes and varied data types. They also build in automated data quality checks, ensuring that a model does not break silently when an upstream system changes a data format. Data governance, meanwhile, is not just a buzzword but a necessity to ensure that data ownership, lineage, and security are well-defined (IBM). These foundational elements might not grab headlines like machine learning breakthroughs, but they form the indispensable bedrock on which any AI system must stand.
Many AI projects fail to progress from pilot to production because they lack strong executive sponsorship or broader strategic alignment (RAND). When top leadership views data science as a side experiment, it becomes the first item to land on the chopping block when resources tighten or new fads emerge. By contrast, initiatives that enjoy sustained executive endorsement and clear connections to corporate strategy tend to survive the inevitable road bumps. This buy-in is not merely about writing a big check. It is also about articulating a coherent vision: why the organization is investing in data science, how it fits into competitive positioning, and what success looks like beyond just the next quarter.
Leaders who successfully integrate AI into the business often create a multi-year roadmap that links pilot projects to overarching objectives, whether that means improving customer experience, lowering operational costs, or expanding into new markets. They also ensure that departmental incentives support AI adoption, rather than sabotage it. For instance, a sales team might need performance metrics that encourage them to use AI-driven lead-scoring tools. In the absence of such incentives, the shiny new model might be ignored, even if it performs well.
Tying AI to a broader strategic narrative also helps address cultural resistance. If employees understand that AI aims to augment their roles—perhaps by automating tedious tasks and freeing them to focus on higher-value work—they are less likely to fear displacement. Likewise, clear endorsement from the top can quell the “why should I bother?” syndrome that arises when staff sense that these new systems could be shelved at a moment’s notice.
A well-orchestrated data science initiative does not begin with algorithms. It starts with meticulously laying the groundwork: identifying a real business problem, forming a cross-functional team that unites technical and domain expertise, establishing solid data pipelines, and securing genuine executive support. This preparatory phase might feel less glamorous than training fancy neural nets, but it is a necessary insurance policy against wasted time and sunk costs.
For example, a bank aiming to deploy an AI-driven credit risk model would begin by unifying compliance teams, IT architects, and data scientists to define performance requirements, risk thresholds, and user adoption plans. They would then set up a secure environment that respects customer privacy, invests in data labeling for any credit application anomalies, and tests integrations with existing underwriting systems. Throughout this process, senior executives would articulate the importance of an AI-powered risk strategy for staying competitive. By the time the pilot yields promising results, the path to scaling is already paved with well-established data pipelines, enthusiastic cross-team collaboration, and a business sponsor ready to champion further investment.
In sum, building the right foundations for success is a painstaking but vital undertaking. It does not grab headlines, yet it is the surest way to avoid the tragic fate of so many AI projects that languish in the gap between “cool prototype” and “game-changing commercial solution.” The next chapters will delve into the specifics of turning these strong foundations into tangible deployment strategies and organizational transformations that ensure data science flourishes well beyond the lab.
12.3. Developing and Testing Prototypes
Building a robust foundation is only the start. At some point, the organization needs to move beyond theoretical potential and show that a proposed AI solution actually works in the real world. This is where pilot projects and prototypes enter the picture. While the pilot phase can be exhilarating—finally seeing a model in action—it is also fraught with risk. Many companies stall out at this stage, running small but endless proofs of concept that never deliver tangible commercial returns (Advice on how to avoid pilot purgatory with AI rollout). This section explores how to develop prototypes efficiently, measure their success, and avoid the dreaded “pilot purgatory” that dooms so many AI initiatives.
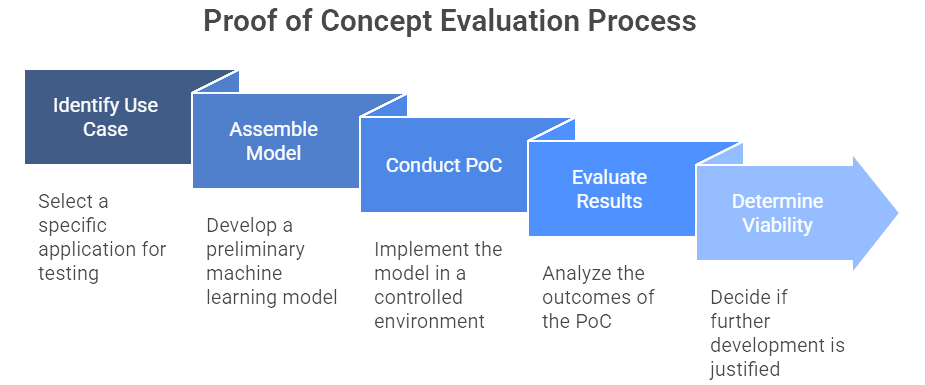
Figure 3: Illustration of the progressive stages of a PoC evaluation, showcasing how a concept evolves from initial idea to a decision on further development. (Image by Napkin).
To demonstrate viability without committing to a full-scale rollout, organizations often begin with a Proof of Concept (PoC). The PoC is typically a contained experiment that asks, “Can this approach even work?” For instance, a data scientist might quickly assemble a machine learning model to predict potential equipment failures in a single manufacturing line. If results look promising—such as an early detection rate above some baseline—this PoC signals that further development is worth pursuing (RAND).
Yet a PoC is rarely ready for prime time. It may be held together with hastily written scripts, partial datasets, or a single data scientist’s “weekend hack.” Once the concept is validated, the next step is creating a Minimum Viable Product (MVP), an intermediate stage that goes beyond rough experimentation. An MVP might include core user-facing elements, limited automation, and basic data pipelines. Think of it as a lightweight yet operational version of the system, allowing a small group of users—say, supply chain planners or claims adjusters—to interact with the AI in a semi-real environment (Digital CxO).
This MVP approach is not just about “looking polished.” It forces the team to solve early-stage engineering and deployment challenges. If there is no plan to handle errors or to secure sensitive data, you will discover that quickly when real users start tinkering with the MVP. Adopting an iterative, agile mindset—where each cycle adds or refines essential features—ensures that the pilot does not languish indefinitely while the project team chases perfection. As one industry veteran notes, “You don’t want to invest a fortune only to learn the user won’t touch your fancy new system” (Digital CxO). Better to discover that user feedback demands a major pivot now, not after a year of heads-down development.
Prototypes can be thrilling to build, but without clear success criteria, they can easily become science fair projects. You need to articulate unambiguous metrics before the pilot launches, so everyone knows what “success” means (RAND). These metrics should blend technical performance (for instance, 85% accuracy in detecting defective parts) with business impact (reducing warranty claims by 10% or improving on-time maintenance schedules).
Well-defined KPIs also provide guardrails for the pilot phase. If your objective is to flag fraud in financial transactions, you might define a target precision and recall rate, plus a business outcome like reducing false positives by 20% to minimize overhead in manual reviews. Additionally, track user adoption if the AI is meant for front-line staff or customers. A pilot might look fantastic on paper but fail if nobody uses the system in practice. Are your sales teams ignoring the new lead-scoring app? Are compliance officers bypassing the AI’s recommended checks?
Capturing baseline data is critical. If you cannot show the existing metrics for, say, defect rates or lead conversion, then you cannot prove how much the prototype has actually improved them. Often, organizations run the new model side by side with the existing process (champion-challenger testing) for a trial period. This arrangement offers a clean comparison: did the AI-based approach beat the old status quo or not?
Equally important is documenting what goes wrong. A pilot is a safe place to encounter errors in data ingestion, discover new edge cases, or realize your model’s drift in real-time conditions. Rather than concealing these blemishes, treat them as gold nuggets of learning. By the end of the pilot, you should have a roadmap for what must be fixed, refined, or upscaled before wider deployment.
Executives often bemoan the fact that they have five or six AI pilots running simultaneously, yet none seems close to enterprise-scale rollout. This phenomenon—“pilot purgatory”—occurs when organizations stay stuck in perpetual experimentation without ever capitalizing on real business gains (Advice on how to avoid pilot purgatory with AI rollout). The reasons vary, but common culprits include:
Lack of a Transition Plan. If the pilot is conceived in isolation—an intriguing side project with no forward path—it is no surprise it never moves beyond the lab. Smart teams design their pilot as though it will be deployed, even if scaled-down. That means addressing basic engineering concerns, data pipelines, and user interface elements. It also means having an upfront plan for scaling if key metrics are met.
Insufficient Business Sponsorship. Technically brilliant prototypes often gather dust if no business leader is championing them. If the pilot does not align with a pressing strategic priority or lacks an influential executive sponsor, it can get lost in the shuffle. Ongoing communication with senior management throughout the pilot ensures that the initiative stays on the radar and receives the green light if it proves valuable.
Unclear (or Underwhelming) Results. Some pilots end with ambiguous findings: “We improved X, but we are not sure by how much,” or “We found interesting patterns, but can’t link them to actual ROI.” Without compelling evidence of a meaningful business upside, the pilot stalls. This is why measuring the right KPIs from day one is so critical. If you can show a 5% boost in cross-selling for your test group, or a 15% decrease in production downtime, stakeholders are more apt to fund a full rollout.
Paralysis by Overreach. In some organizations, the pilot is so ambitious—aiming to revolutionize entire business processes—that it becomes a monstrosity. Implementation complexities, risk concerns, and data issues spiral out of control, resulting in indefinite delays. A narrower, well-defined pilot with achievable objectives is less likely to collapse under its own weight.
Pivot or Kill Early If Needed. A pilot that fails to achieve its metrics is not necessarily a tragedy. In fact, it may be an invaluable lesson—better to discover that your churn model is ineffective than to roll it out across the entire customer base. The key is having the discipline to either pivot to a new approach or terminate the pilot and move on. Keeping failing pilots on life support “just because” bleeds resources and demoralizes the team.
When a pilot succeeds, the path to production should not be an afterthought. Now is the time to plan for robust data pipelines, governance frameworks, user training, and performance monitoring that can sustain the model at full scale. This includes a realistic budget and timeline for engineering tasks—such as integrating with enterprise IT systems, adding logging or auditing capabilities, or ensuring compliance with industry regulations. The final pilot report should clearly outline these requirements, offering a blueprint for the next phase. It is also wise to define a “phased rollout” plan, where you gradually extend usage from a single department or product line to the broader enterprise. This approach mitigates risk and allows you to refine any rough edges discovered in the pilot environment.
Ensuring user buy-in at this juncture is critical. If the pilot has proven that the AI tool saves time or increases accuracy, show those results to end-users and leaders in other divisions. Offer training sessions and highlight early success stories. This momentum can help counter residual skepticism and accelerate adoption. By the end of this pilot-to-production transition, you want a solution that is not only technically sound but also culturally accepted—part of the organization’s operational DNA.
Prototypes and pilots can feel like the most exciting stage of an AI project: after all, this is where concepts become tangible, and early wins often emerge. Yet it is also a precarious moment, with many organizations falling into the trap of endless tinkering (RAND). By adopting a disciplined approach—rapidly building MVPs, defining clear success metrics, and proactively planning for possible scale-up—companies can unlock valuable business insights and lay the groundwork for broader deployments. The best pilots do more than prove a technical concept: they forge the operational and cultural pathways that allow AI to become a genuine engine of commercial value. With the pilot stage navigated, the next challenge is scaling up the system, a journey often fraught with its own set of technical, organizational, and cultural barriers. The following section will explore those hurdles and provide strategies for ensuring AI deployments become a sustained competitive advantage rather than another abandoned experiment.
12.4. Scaling from Pilot to Full Deployment
A successful pilot proves the technical viability and business promise of a data science solution, but it is only the beginning. Moving from a localized proof of concept to enterprise-wide adoption can be a bumpy road—one that requires robust engineering, thoughtful change management, and a solid financial case. This phase often determines whether an AI initiative yields transformative outcomes or fades away as a cautionary tale of untapped potential. The following sections guide you through overcoming technical barriers, fostering organizational buy-in, and securing the necessary resources to turn a pilot into a true game-changer.
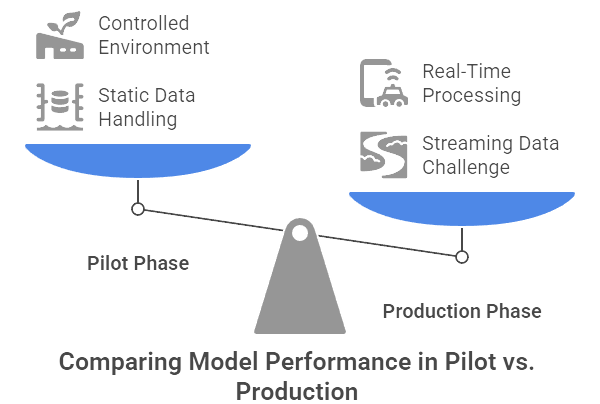
Figure 4: Illustration of the transition from a structured pilot phase to the real-world, streaming data driven challenges of production. (Image by Napkin).
A model that dazzles in a pilot can falter when pushed into real-world production. The reasons are numerous. Often, the pilot ran on small batches of static data, whereas enterprise deployment demands near real-time ingestion and processing. Consider a fraud detection model initially tested on historical transaction logs in a controlled environment. In production, it may need to handle streaming data at scale with millisecond latency—an altogether different challenge.
Refactoring code for efficiency and reliability is crucial. Data science scripts, which may have been “just good enough” for a limited pilot, must be rewritten to handle production workloads. This may involve more optimal data structures, parallel processing, or distributed computing frameworks. Integration also becomes a headache if your pilot only consumed CSV files dropped into a folder, while the production system needs robust APIs to communicate with existing CRM, ERP, or IoT platforms.
MLOps—a set of practices applying DevOps principles to machine learning—addresses these pain points. It includes automated testing of models, continuous integration/continuous deployment (CI/CD) pipelines, and version control for data and code (Digital CxO). Using containerization tools such as Docker and orchestration systems like Kubernetes can simplify scaling up across multiple servers and environments. By automating the deployment process, you reduce the risk of human error and ensure consistency between the development lab and production.
Testing at scale is equally important. Load tests can reveal bottlenecks or concurrency issues, while failover tests verify that your AI-driven service can recover gracefully if a node goes offline. Regulated sectors such as banking or healthcare add another layer of scrutiny. Before a credit risk model can go into a bank’s lending flow, it might need extensive validation and auditing to meet model risk management standards. The aim is to produce a hardened system that is not only accurate but also secure, resilient, and ready to function in the unpredictable wilds of production.
The best-engineered AI solution will not move the needle if nobody uses it. Ensuring widespread adoption is as much a people challenge as a technical one. It starts with clear communication. Leaders need to explain what is changing and why, highlighting how the new system will benefit employees—whether by saving time, reducing errors, or expanding their impact. Without this transparency, frontline staff may default to distrusting or ignoring the new tool.
Training can make or break adoption. Medical professionals may need hands-on sessions to understand an AI-assisted diagnosis system, while sales teams might require guidance on interpreting lead-scoring outputs. Employees are more likely to embrace a model if they can see how it augments their expertise rather than renders them obsolete. When UPS rolled out an AI-based route optimization platform, it dedicated substantial resources to involving drivers in the design and pilot phases (Machine Learning Times). By showcasing early successes and respecting drivers’ on-the-ground knowledge, UPS turned potential skepticism into buy-in.
Actively soliciting feedback in the first weeks or months of deployment is also critical. If a user finds the AI’s recommendations unhelpful, or a nurse struggles to integrate new alerts into existing workflows, address these pain points swiftly. This early responsiveness builds trust and sets the stage for ongoing collaboration between data teams and end-users. Some organizations even designate “AI champions” within each department to facilitate communication, troubleshoot minor issues, and share success stories.
Scaling an AI project beyond a pilot stage typically comes with a hefty price tag. It might involve upgrading hardware, migrating to scalable cloud services, hiring MLOps engineers, or integrating new software tools. Executives will want a robust, data-driven case for why it is worth the cost. The best financial models blend bottom-line improvements (such as reduced labor costs, increased revenue) with potential strategic benefits (better customer loyalty, risk mitigation, faster product innovation).
Quantifying these advantages is often easier if the pilot already provided a glimpse of potential ROI. If your pilot in one region reduced defects by 10%, how might that extrapolate across all manufacturing plants, even if you lower the assumption to 5% to be conservative? Tie each percentage point of improvement to a dollar amount saved or earned, factoring in variations across regions or product lines.
Equally important is providing a complete picture of costs. Beyond the initial deployment, the model will require ongoing maintenance—data monitoring, retraining, cloud computing resources, and possibly a dedicated support team. In heavily regulated industries, compliance checks can add further operational expenses. By offering a phased funding approach—where each stage of the rollout has defined milestones for ROI or performance targets—you can reassure budget holders that the project will remain under close scrutiny and can be halted or pivoted if it underperforms.
“How much are we losing by doing nothing?” can be a potent argument as well. If your pilot showed that the model significantly reduces supply chain delays or predicts equipment failures before they occur, the costs of inaction could be wasted inventory, production downtime, or client dissatisfaction. Industry surveys indicate that firms that allocate a meaningful portion of their budget to data science and AI often see better outcomes (CFO Dive). In other words, half-baked investment typically leads to half-baked results—and executives should recognize that commitment at scale is key to unlocking AI’s full promise.
Scaling from pilot to full deployment is the crucible where promising AI concepts either gain momentum to transform an organization or fade into obscurity. The transition demands strong engineering practices, rigorous validation, and MLOps frameworks to ensure the solution can handle real-world demands. It also requires a concerted focus on human factors—guiding employees through the shift in workflows and addressing legitimate fears about “new technology” intruding on old routines.
On top of these challenges, financial scrutiny intensifies at this stage. Leaders expect clear ROI projections and want confidence that the pilot’s success will hold across the enterprise. Tackling all these dimensions in tandem—technical, cultural, and economic—positions a data science project for genuine impact. When executed well, a scaled AI deployment can reshape how a company operates, giving it a strategic edge that is difficult for competitors to replicate. It is not easy, but as data-driven leaders increasingly discover, the rewards can far outweigh the costs if you are willing to invest in doing it right.
12.5. Monitoring, Maintaining, and Improving Models in Production
The launch of a data science solution into live operations might feel like the finish line, but it is closer to the starting gate of an entirely new race. In production, machine learning models face a fast-changing world, evolving business conditions, and heightened regulatory scrutiny. The critical question becomes: how do you ensure that yesterday’s accurate algorithm remains robust and relevant tomorrow? This section explores the ongoing cycle of monitoring, maintenance, and enhancement required to keep AI deployments on track—technically, operationally, and ethically.
Machine learning systems excel when patterns in training data resemble real-world conditions. Once deployed, however, the world keeps shifting, and a model trained on last year’s patterns can gradually—or suddenly—lose its edge (VIANOPS_Whitepaper_NG_VO2). This phenomenon of performance erosion is commonly labeled drift: data drift when the input distributions change, and model drift when the predictions themselves degrade as a result. Imagine a demand-forecasting model built on historical purchasing trends. A new competitor enters the market, or a viral social media campaign reshapes consumer behavior overnight, and the old assumptions begin to fail.
A 15-point drop in accuracy might sound like an academic statistic. In practice, it can translate into severe business pain, such as missed fraud alerts or poorly allocated inventory. Early detection is paramount. Many companies track real-world outcomes and compare them to the model’s predicted values, sending alerts if deviations exceed a preset threshold. Others implement statistical tests like the population stability index to spot shifts in feature distributions (a favorite in finance for credit-scoring models).
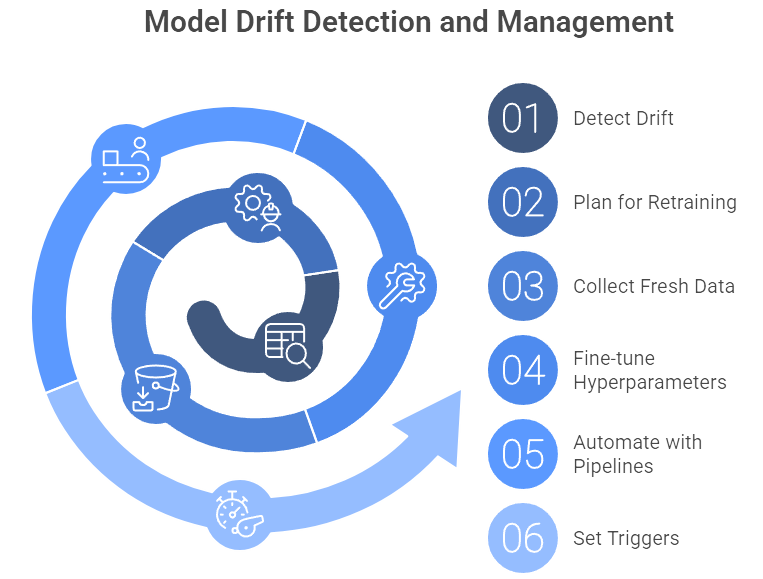
Figure 5: Illustration of the proactive approach to model drift management, guiding users from initial drift detection to automated pipeline adjustments. (Image by Napkin).
Detecting drift is only half the battle. You need a plan for retraining or recalibrating the model. This might mean collecting fresh data, fine-tuning hyperparameters, or going back to the drawing board with a new feature set. Some organizations automate these steps through “continuous training” pipelines: the system retrains at regular intervals or whenever performance dips below a target level. Of course, retraining too often can chase random noise and create unwanted volatility. Most teams set moderate triggers—for instance, a 3% drop in accuracy or a 10% rise in false positives—before updating the model.
Maintaining fallback mechanisms is another good practice, especially for mission-critical applications. In fraud detection, you might keep a simpler rules-based system as a backup if the main model malfunctions or yields uncertain results. Modern MLOps frameworks support these champion-challenger approaches, running a new model in shadow mode until it proves reliable enough to dethrone the current champion.
An effective AI solution does not just react to data drift; it adapts and improves over time through closed-loop feedback. Each prediction produces a real outcome—whether that is a correctly identified defect on a production line or a misclassified insurance claim—and those outcomes can be fed back into the training process (C3 AI Glossary). This iterative cycle mirrors how human expertise evolves: mistakes turn into lessons, and successes confirm best practices.
Achieving this requires disciplined logging and governance. If a model flags a transaction as fraudulent but a subsequent investigation proves it legitimate, that data point must be captured as training material for the next iteration. The loop can be partially automated or involve human review. For instance, a healthcare system might require doctors to confirm AI-driven diagnoses, generating corrections that inform future retraining.
Continuous learning can become a critical differentiator. Organizations that refine their models in near-real time can respond faster to shifting market dynamics or new threats. However, caution is warranted in sensitive domains: fully automating these updates can lead to abrupt changes in behavior. A measured approach might use monthly or quarterly retraining windows, with domain experts scrutinizing anomalies. Whichever cadence you choose, the guiding principle is to treat your AI like a living product, rather than a set-and-forget installation.
As AI migrates from experimental curiosity to mainstream decision-maker, regulators, customers, and the media all start asking tough questions: Is it fair? Is it transparent? How do we know it is not making hidden mistakes that harm innocent individuals? The last thing a company wants is to discover a critical flaw only after it has led to lawsuits, regulatory fines, or a PR fiasco.
Compliance is the baseline. In banking, credit-scoring models must meet rigorous model risk management requirements, including traceability of how the model was developed, tested, and validated. Healthcare organizations deploying AI-driven diagnostics must adhere to patient privacy laws and often need regulatory approval for medical devices if the algorithm directly impacts treatment. Documentation is key. Creating a “model dossier” that records the training methodology, performance metrics, and any bias tests is not only prudent but increasingly expected (European AI Act proposals and similar regulations).
Ethical AI goes a step beyond legal compliance, addressing broader concerns like systemic bias or the potential for unintentional discrimination. Many companies form AI ethics committees to review high-stakes models before launch and periodically audit them post-deployment. Tools like SHAP or LIME provide local explanations for individual model decisions, which can be crucial for user trust and regulatory requirements to “explain” automated decisions (e.g., loan approvals or rejections). Bias can creep in stealthily if your training data reflects historical inequities, so ongoing monitoring should include performance breakdowns by demographic groups or other relevant segments.
Security is another frequently overlooked aspect of production AI. Models can leak sensitive information, especially if they were trained on private data that inadvertently surfaces in predictions. Adversarial attacks—where malicious actors manipulate inputs to trick the system—pose a growing threat for vision, speech, or other ML applications. Organizations should integrate model threat assessments and “red team” exercises into their AI governance programs, testing resilience against cunning hacks.
Finally, do not let obsolete models linger in your environment. Large enterprises often have a sprawling inventory of models, some of which nobody remembers to maintain or retire. A robust lifecycle management process ensures that every model has a named owner, scheduled performance reviews, and an eventual path to decommissioning if it no longer adds value.
If initial deployment felt like scaling a mountain, post-deployment management can feel like maintaining a complex factory line that never stops running. The upside? This is where the real benefits of data science kick in. Continual monitoring can reveal hidden patterns, leading to second-generation improvements that dwarf the pilot’s gains. Users, emboldened by early success, might propose new applications for the model or suggest additional data sources.
These cycles of refinement and expansion often drive the biggest breakthroughs. By the time an organization has a year of production usage under its belt, it might incorporate additional datasets (like third-party market indicators) or advanced techniques (like reinforcement learning). The model transitions from a one-off solution to a strategic asset, deeply woven into the company’s operational fabric.
The moment a data science system goes live is not a celebratory ending—it is a call to arms for ongoing vigilance, iteration, and control. Models drift, business contexts shift, and regulatory landscapes can evolve overnight. Executives must budget not just for building AI solutions but also for sustaining and refining them in a dynamic environment. Cultivating closed-loop feedback systems, robust compliance oversight, and an ethical grounding ensures that the AI adds lasting value rather than sporadic bursts of short-lived success.
The best-performing organizations understand that “going live” is merely the first step in a continuous dance with real-world data and user feedback. Through disciplined monitoring, timely maintenance, and conscientious governance, data science can grow from a promising prototype to a transformative, enduring capability that drives competitive advantage. In the final analysis, it is the day-to-day care and feeding of models—far more than the initial launch—that determines whether an AI initiative truly reshapes your enterprise for the better.
12.6. Strategic Takeaways for Business Leaders
Leading an AI project from inception to enterprise-scale impact may look straightforward on a whiteboard but becomes far more complex in real life. Data pipelines break, users resist changes, and initial ROI projections can get lost amid shifting priorities. Yet many organizations are finding a way forward, delivering genuine value through data science. What separates these successes from the cautionary tales? The following considerations offer a distilled roadmap for executives who want to ensure that data science investments go beyond flashy pilots and become a sustained engine of business growth.
Not every innovative algorithm has a place in your organization’s strategic plan. The best projects solve a known pain point or unlock a clear commercial opportunity, with measurable outcomes if the model works (RAND). Before greenlighting an AI initiative, insist on a crisp explanation: how will this pilot, if successful, cut costs, boost revenue, or improve a core KPI? If the champion of the project cannot articulate a one-sentence “value hypothesis” tied to tangible results, the project risks becoming an academic curiosity rather than a high-impact solution.
Aligning with genuine business needs does not mean ignoring technical details, but it ensures that model selection and performance metrics always point toward ROI. If the team’s excitement seems directed more at testing a new deep learning framework than addressing churn or forecast accuracy, take a step back. Keeping the conversation anchored in business value helps avoid the classic pitfall of “fancy models that do not move the needle.”
Executives sometimes assume they can rapidly build sophisticated AI capabilities on top of subpar data and improvised infrastructure. That is akin to trying to construct a skyscraper on quicksand. A robust data foundation—complete with clean, well-organized, and governable pipelines—is your bedrock for success (RAND). Building that foundation can be expensive and time-consuming, which is precisely why many companies try to cut corners. In truth, these cost-saving shortcuts often doom otherwise promising pilots.
A balanced approach recognizes that you do not need perfect enterprise data governance to start. You can indeed run pilots in parallel with ongoing infrastructure improvements. However, core elements such as consistent data storage, basic quality checks, and secure access controls should be prioritized. Without them, even a great pilot will struggle to scale. Moreover, this groundwork is not a one-time investment. Organizations that succeed with AI typically keep evolving their data and MLOps platforms to accommodate new use cases and greater volumes of data.
Data science initiatives often fail due to organizational silos, not technical issues. You can have brilliant data scientists, but if they never interact with the operations team—or if the IT department blocks them at every turn—progress stalls. Leaders should champion a culture of shared ownership, where data scientists, domain experts, engineers, compliance officers, and business stakeholders work in tandem rather than in isolation.
This cultural shift may include co-locating project teams, embedding data scientists within business units, or appointing “analytics translators” who have enough technical knowledge to communicate effectively with both data experts and frontline managers. The goal is to have continuous feedback from all angles, ensuring that the AI solution is both technically sound and operationally relevant. Investing in cross-training and upskilling staff pays dividends too. When your business analysts and sales managers appreciate the power and limitations of machine learning, they become active contributors rather than skeptical observers.
Picture an AI solution that perfectly forecasts inventory or detects fraudulent transactions—but that nobody bothers to use. This scenario is not as far-fetched as it seems. Many well-engineered tools languish on the shelf because employees are unconvinced, untrained, or simply overwhelmed by the new technology. Strong change management should not be an afterthought. It is at least half the battle in realizing ROI.
Senior leadership must demonstrate visible support, publicly celebrating early wins and framing the AI system as a catalyst for better performance rather than a threat to employees’ jobs. Solicit real feedback from the pilot phase and respond quickly to concerns. Consider establishing an “AI council” that meets regularly to coordinate adoption, address friction points, and highlight best practices. Over time, this governance layer also becomes an engine for scaling AI across multiple domains in the company. Ultimately, if the people on the ground do not embrace the tool, no level of executive mandate can salvage the rollout.
A data science model is not a one-off deliverable. It is more like a living organism that needs ongoing monitoring, routine checkups, and occasional surgery to remove what no longer serves. Leaders who treat AI deployments as “set it and forget it” typically wake up months later to discover that performance has dropped or compliance risks have multiplied. Building a governance framework ensures that models continue to deliver at or above the performance thresholds that justified their rollout.
Such governance might include periodic audits for fairness or bias, especially in high-stakes use cases like credit lending or healthcare. In finance, formal model risk management policies offer a blueprint: each model has an owner responsible for performance oversight, and changes to the model undergo rigorous review (as they would in software patch cycles). Even in less regulated industries, it is prudent to maintain an internal review board that tracks the results, ethical considerations, and stability of production AI systems. If something goes awry, you want to catch it quickly and have a clear protocol for mitigating damage.
No matter how carefully you plan, some AI projects will flop. Perhaps the data was less predictive than hoped, or the organization was not ready for the level of change required. Instead of burying these disappointments, treat them as opportunities to strengthen your playbook (The Root Causes of Failure for Artificial Intelligence Projects and How They Can Succeed: Avoiding the Anti-Patterns of AI). Conduct honest post-mortems to identify the root causes and feed those lessons back into future projects. A measured tolerance for failure, coupled with structured learning, is a hallmark of truly data-driven organizations.
Teams that fear blame for missed goals may hide problems until it is too late. Conversely, when leaders treat each failed experiment as part of a broader innovation cycle, staff become more open about challenges and more willing to pivot early if needed. Over time, a culture of continuous improvement emerges, leading to more refined processes for scoping projects, selecting the right metrics, and engaging end-users.
AI success does not happen in a vacuum. The most powerful transformations occur when the entire organization starts treating data as a core strategic asset. Rather than relying on gut feeling, leaders consistently ask, “What does the data say?” or “How might we test this hypothesis with a quick A/B experiment?” This mindset shift radiates through the company, making it easier for each new AI pilot to gain traction and graduate to production. It also encourages a steady flow of fresh ideas for new models and analytics, sustaining a virtuous cycle of innovation.
This data-driven ethos should show up in decision-making forums: board meetings, quarterly planning sessions, and day-to-day operational discussions. When employees see that leadership weighs data-driven analysis heavily, they become more inclined to seek insights from existing models or propose new ones. The end state is an organization where data science is not an occasional add-on but a fundamental part of how strategy is conceived, operations are run, and success is measured (HBS Online).
Data science initiatives can feel like juggling flaming torches: demanding technical rigor, cross-functional teamwork, cultural adoption, and regulatory diligence. Yet the payoff can be transformative—a competitive edge that reshapes market dynamics and radically improves operational efficiency. From clarifying how AI solutions tie to genuine business needs, to building lasting data infrastructure, to managing post-deployment drift, leadership involvement and endorsement remain vital at every juncture.
Ultimately, moving AI from interesting lab project to true enterprise capability is a journey, not a simple checklist. Leaders who maintain focus on business value, invest in the right infrastructure, build cross-functional bridges, and sustain a culture of experimentation are more likely to see real returns. These strategic takeaways might not guarantee a flawless path, but they significantly reduce the odds of your data science dreams ending in a dusty folder labeled “pilot.” If you are prepared to balance ambition with discipline and vision with execution, data science can evolve from buzzword territory into a potent driver of long-term corporate success.
12.7. Conclusion and Further Learning
In commercial data science, the real challenge isn’t building a clever model – it’s delivering lasting business impact. That journey from pilot to production is the crucible where strategy, technology, and organization must come together. We began this chapter by examining why so many AI projects struggle to scale, from the infamous “last mile” problem to issues of data and culture. We then explored how to lay the groundwork for success with clear goals, teamwork, and solid data infrastructure, before diving into the pilot phase, where ideas are tested and validated. We discussed the critical transition to production, highlighting that both engineering excellence and change management are required to roll out AI solutions enterprise-wide. Finally, we stressed the importance of ongoing model maintenance and governance, as deploying AI is not a one-off event but a continuous process of learning and improvement. The key insight tying all this together is that implementing AI is a multidisciplinary effort – it demands not just data scientists, but engaged executives, domain experts, engineers, and end-users working in concert. For business leaders, championing this collaboration and keeping the focus on business value are perhaps the most important roles you can play. When done right, moving a data science project from pilot to production can unlock significant value – whether it’s millions in cost savings, new revenue streams, or improved customer experiences. And beyond the individual project, building this organizational muscle sets you up to execute future AI initiatives faster and more effectively than the competition. In a world where AI capabilities are increasingly a differentiator, mastering the art of deployment is what will separate the leaders from the laggards. As you apply the concepts from this chapter, remember that each industry and organization may have its nuances – but the overarching principles of alignment, iteration, and governance will guide you to adapt and succeed. With strategy and perseverance, you can ensure your company’s AI innovations don’t just remain proofs of concept, but become powerful engines of transformation in production.
Implementing data science projects in real business environments is a rich topic. The following prompts are designed to help readers explore and apply the chapter’s concepts more deeply. They encourage reflection on challenges, application of best practices, and critical thinking about how to drive successful AI adoption. Use these prompts to spark discussion, guide self-study, or as starting points for research into specific areas of interest. Each question invites you to connect the principles learned with practical scenarios or broader implications of data science in industry.
Identifying Failure Points: Think of a data science project (real or hypothetical) that failed to move from pilot to production. What were the likely failure points in terms of strategy, data, technology, or organization? How could those have been addressed proactively?
Business Case Articulation: Select a use case in finance (e.g., algorithmic trading, fraud detection) and outline a clear business objective for an AI project in that area. How would you quantify success for this project, and what key metrics would you monitor during a pilot?
Stakeholder Alignment Exercise: In a healthcare AI scenario (say, a model to assist in radiology diagnoses), list the various stakeholders (executives, doctors, IT, patients, regulators). What concerns or objectives would each have, and how would you align them during the project’s planning phase?
Data Readiness Audit: Consider a manufacturing company starting an AI predictive maintenance project. What steps would you include in a data readiness audit for them? Identify potential data sources, quality issues, and governance policies that need to be in place before modeling.
PoC vs. MVP Debate: Debate the merits of doing a quick proof-of-concept versus investing time in an MVP. Under what circumstances is a throwaway PoC sufficient, and when is it crucial to develop an MVP that’s closer to production? Provide examples from different industries.
Pilot Design: Design a pilot for an AI-powered supply chain optimization tool. What is the scope of the pilot (which part of the supply chain, what data, how long)? What hypotheses are you testing, and how will you measure if the pilot is successful?
Avoiding Pilot Purgatory: Imagine a scenario where a logistics company has 5 different AI pilots running (for routing, demand forecasting, warehouse automation, etc.) but none scaled up. Propose a plan to review these pilots and decide which one(s) to scale, which to drop – what criteria would you use?
Technical Scaling Challenges: List three technical challenges you might encounter when scaling a machine learning model from a single-machine pilot to a cloud-based production environment. How would you address each challenge?
MLOps Implementation: Describe what an ideal MLOps pipeline looks like for an e-commerce recommendation system that’s updated frequently. What tools or processes would you put in place for version control, CI/CD, monitoring, and retraining?
Change Management Plan: Create a brief change management plan for deploying an AI analytics dashboard to a sales team. How will you train the team, encourage adoption, and handle resistance from veteran salespeople who trust their intuition over “a model”?
ROI Calculation: Take the role of a CFO evaluating a proposal to invest $2 million in scaling an AI system company-wide. What information would you need to see in the proposal’s financial model? How would you approach calculating the ROI or payback period for this investment?
Risk Mitigation: Identify potential risks in deploying an AI model for automated loan approvals in a bank. Consider risks like bias, model error, security breaches, etc. For each risk, suggest a mitigation strategy (e.g., human-in-the-loop, bias audits, fallback processes).
Drift Detection Scenario: You deployed a model for retail inventory optimization last year. Lately, it’s not performing as well. How would you determine if data drift or concept drift is the issue? Describe the process and metrics/tools you would use for drift detection.
Continuous Improvement Loop: Provide an example of a feedback loop for a predictive maintenance model used in an oil refinery. What data comes back after model predictions, and how is that used to improve the model? What challenges might arise in maintaining this loop?
Ethical Considerations: Discuss the ethical implications of deploying AI in healthcare diagnostics. How do we ensure such a model is fair, transparent, and accountable? What steps would you recommend before and after deployment to uphold ethical standards?
Regulatory Compliance Check: In a financial services firm, an AI model is used for credit scoring. What regulatory compliance steps should be taken before full deployment? Consider guidelines like model validation, documentation, explainability, and customer communication.
Scale vs. Scope Decision: If a pilot succeeds in one business unit of a global company, how do you decide whether to scale it to other units as is versus tailoring or extending the scope first? What factors influence whether a one-size-fits-all deployment will work or not?
Culture Building: Propose three initiatives a CEO can undertake to build a more data-driven culture in a traditional manufacturing firm. How would these initiatives help future AI project implementations?
Learning from Failure Case Study: Research a known case where an AI project failed (for example, IBM Watson’s foray into healthcare). Analyze what went wrong and present key lessons that another company can learn to avoid a similar fate.
Vision for AI in Your Industry: Envision your organization (or an organization of your choice) five years from now with successful AI implementations across multiple functions. What does that look like in practice? How are decisions made differently? Use insights from this chapter to describe the journey to that future state.
These prompts cover a spectrum of issues from the tactical (designing pilots, calculating ROI) to the strategic (culture change, ethical AI). Engaging with them will deepen your understanding of what it takes to make AI initiatives work in the real world. They encourage applying the concepts to concrete situations, thereby reinforcing the learning.
In exploring these questions, there are no single “right” answers – much depends on context. Discussing them with colleagues or writing out responses can reveal how you might handle the nuances of implementing data science in your own environment. Through this deeper inquiry, you will be better prepared to lead and support AI projects that truly bridge the gap from promising pilot to productive deployment.
To solidify your understanding of moving data science projects from pilot to production, here are five practical assignments. These exercises are designed to reinforce key learning objectives by putting them into action. They range from case study analysis to planning tasks. Detailed guidance is provided for each to help you structure your approach. Completing these assignments will give you hands-on experience with the concepts discussed in the chapter and prepare you to apply them in real-world projects.
🛠️ Assignments
📝 Assignment 1: Case Study Analysis – Pilot to Production Failure
🎯 Objective:
Identify reasons why AI projects fail to scale and propose remedies.
📋 Tasks:
| Aspect | Details |
|---|---|
| Analyze Failure & Propose Fixes: | Research a real case (or use a detailed hypothetical scenario) where a company’s AI project succeeded in pilot but failed to reach full production deployment. Write a brief case study (1-2 pages) describing the project, its goals, and outcomes. Then analyze at least three reasons that impeded scaling (e.g., lack of executive support, data issues, user pushback). For each reason, provide specific evidence or quotes from the case. Finally, propose what the company could have done differently to avoid “pilot purgatory.” |
💡 Guidance:
Choose a case from an industry you’re interested in (finance, healthcare, etc.). If details are scant, make reasonable assumptions to flesh out the scenario. In your analysis, tie reasons to concepts from the chapter (for instance, if the issue was no clear ROI, relate it to the importance of business objectives). When proposing remedies, be concrete: e.g., “implement a cross-functional steering committee after pilot to oversee scaling, which might have caught issue X early.” Ensure your case study has a clear narrative: what was tried, what happened, why it failed, and lessons learned.
📝 Assignment 2: Project Planning Workshop
🎯 Objective:
Practice planning an AI project with alignment and deployment in mind.
📋 Tasks:
| Aspect | Details |
|---|---|
| Deliverable: | Create a presentation (4-5 slides or a written plan) covering the following points for a new AI personalized marketing initiative at a retailer. |
| 1. Project Objective & Scope: | Define the business goal, specify which data sources will be used, and outline the marketing channels involved. |
| 2. Stakeholders Involved: | List the key departments and roles (e.g., Marketing, IT, Data Science, Legal) and outline their respective interests and contributions. |
| 3. Data Requirements & Assessment: | Specify the data needed for personalization and perform an initial assessment regarding its availability, quality, and any associated privacy concerns. |
| 4. Pilot Design: | Outline how the concept will be tested – describe the pilot's scope (e.g., customer segment, duration), methodology (e.g., A/B test), and success metrics (e.g., conversion lift). |
| 5. Deployment Considerations: | Describe the necessary steps for a full implementation if the pilot is successful, including system integrations, team capabilities, and potential rollout challenges. |
💡 Guidance:
This is about simulating upfront planning. Ensure each section is informed by best practices: for example, in stakeholders, mention aligning IT and marketing teams; in data, note governance steps for customer data privacy (very relevant for personalized marketing). For success metrics, consider both model performance (click-through rate prediction accuracy) and business outcome (increase in sales from targeted campaigns). In deployment, mention needing a marketing automation system integration. The goal is to show you can plan not just the data science part but the whole lifecycle. Your presentation/plan should be concise but specific, as if proposing the project to an executive committee for approval.
📝 Assignment 3: Develop a Monitoring & Maintenance Playbook
🎯 Objective:
Learn to create a plan for post-deployment model management (MLOps).
📋 Tasks:
| Aspect | Details |
|---|---|
| Deliverable: | Create a “Model Monitoring and Maintenance Playbook” (approximately 1 page or flow diagram) for an AI dynamic pricing model deployed by an airline. |
| 1. Monitor Performance: | Define key metrics to track (e.g., revenue vs. forecast, booking conversion rates, model prediction error, price volatility). |
| 2. Detect & Handle Drift: | Describe a drift detection technique (e.g., monitoring input data distribution or output prediction distribution) and the threshold that would trigger investigation or action. |
| 3. Retrain/Update Model: | Specify the retraining frequency (e.g., monthly), the data to be used (e.g., latest 3 months), and whether retraining is automated or requires manual approval. |
| 4. Govern Changes: | Outline who reviews and approves model updates, how model versions are documented, and the process for rolling back if an update causes issues. |
| 5. Ensure Compliance & Fairness: | Include necessary audit checks to ensure pricing does not become discriminatory or violate regulations. |
💡 Guidance:
This playbook can be in bullet form but should cover the lifecycle after initial deployment. Use airline context specifics: for instance, sudden events like a pandemic drastically change travel demand – your drift detection should catch that (e.g., model’s error spikes beyond X% for Y days). For retraining, maybe plan monthly retraining using the latest 3 months of data, but also have a procedure for emergency retraining if drift is detected. Include roles (data science team, pricing managers, IT ops) in the governance part. The playbook should read like a SOP (standard operating procedure) for keeping the pricing model healthy and aligned with business strategy continuously.
📝 Assignment 4: ROI and Scaling Justification Memo
🎯 Objective:
Practice financial justification and scaling strategy for an AI project.
📋 Tasks:
| Aspect | Details |
|---|---|
| Deliverable: | Write a professional memo (approx. 500 words) to the CFO and CIO advocating for budget to scale a successful pilot AI project (e.g., route optimization showing 8% fuel savings) company-wide. |
| 1. Summary of Pilot Results: | Detail the benefits achieved during the pilot phase and specify the costs incurred. |
| 2. Projected Scaling Benefits: | Extrapolate the pilot results to estimate company-wide benefits (e.g., total annual savings or revenue increase), stating assumptions clearly. |
| 3. Required Investment: | List the necessary investments for scaling, including equipment, software, hiring, training, and provide rough cost estimates. |
| 4. ROI Calculation: | Calculate the expected ROI or NPV over a 3-year horizon, demonstrating positive returns and showing the payback period. Use tables/graphs if helpful. |
| 5. Risk Analysis: | Identify potential risks that could affect outcomes during scaling (e.g., lower performance in different regions) and outline mitigation plans (e.g., phased rollout). |
💡 Guidance:
Write in a persuasive, concise business style. The memo should hit the key points a CFO/CIO cares about: value, cost, time frame, and risks. Use numbers wherever possible. You might say “Pilot in Region A saved $500k in fuel in 6 months. Scaling to 5 regions, we conservatively estimate $3M savings/year. Required one-time investment is $1M in IT infrastructure and $200k in training, plus $100k incremental operating costs annually. Thus, net first-year benefit ~$1.7M, growing as optimization improves.” Include a simple table if needed to clarify the math. Addressing risk, you might note e.g., “If actual savings are only half of pilot rate, ROI would drop, but even at 4% savings, we break even in 18 months.” End with a clear recommendation to fund the project, highlighting strategic benefits (e.g., sustainability gains from fuel efficiency, competitive edge, etc., in addition to pure cost savings).
📝 Assignment 5: Simulation of Cross-Functional Project Kickoff
🎯 Objective:
Apply interdisciplinary coordination skills for AI projects.
📋 Tasks:
| Aspect | Details |
|---|---|
| Scenario & Deliverable: | Conduct (or script out) a mock kickoff meeting for a cross-functional team starting an AI project (e.g., AI-driven quality control in manufacturing). Include participants from data science, IT, business unit, and compliance. Choose one format: (a) written dialogue/script (1-2 pages) OR (b) meeting agenda with detailed notes/minutes. |
| Key Points to Cover: | Ensure the discussion covers: clarifying the project’s objective and success criteria (led by business); discussing data availability and issues (led by data engineer); identifying implementation challenges (led by IT); addressing regulatory/ethical concerns (led by compliance); and agreeing on next steps and responsibilities for all participants. |
💡 Guidance:
This is to simulate the early alignment process. If doing a script, try to make the voices realistic (e.g., the compliance officer might say “Have we considered how we’ll audit the decisions? We need logging.” The operations manager might say “Operators on the line need a simple interface, or they won’t use this.”). If doing an agenda+notes, list topics like “1. Objectives (presented by …) – Decision: agreed target is to reduce defect rate by 15% in pilot)” etc. The outcome should show a comprehensive view of planning: each function raises relevant questions (data, tech, process, compliance, ROI) and the team aligns on how to handle them. The exercise forces you to think from multiple perspectives, reinforcing the importance of cross-functional collaboration.
Each of these assignments targets a different facet of implementing data science projects commercially: diagnosing failures, planning projects, managing models, making a business case, and coordinating teams. While completing them, use resources and references from the chapter to inform your work. For instance, recall the statistics or quotes (like culture being 90% of the problem, or the need for CI/CD in MLOps) to strengthen your points. The detailed guidance is there to help, but feel free to inject creativity and additional considerations.
By engaging with these practical tasks, you’ll translate theoretical knowledge into applied skills. Whether you are a business executive overseeing AI initiatives or a practitioner executing them, these exercises provide a safe sandbox to practice critical thinking and decision-making. After completing the assignments, you should feel more confident in your ability to champion a data science project from its conceptual start through to its successful, value-generating finish in production.
Comments