Chapter 15
Scaling Up and Sustaining Data Science Initiatives
"The biggest challenge for CDOs is not data science, technology, or analysis, but driving cultural change across the organization to become more data-driven." — Asha Saxena
Scaling up and sustaining data science initiatives is a multidimensional challenge that goes beyond algorithms – it requires strategic vision, cultural change, and operational excellence. This chapter has outlined how businesses can elevate analytics from isolated experiments to an enterprise-wide capability. Key ideas include securing leadership commitment and aligning data science with core business goals, building a strong data foundation and technology infrastructure, and nurturing the right talent and team structures. A recurring theme is the importance of culture: organizations must foster a data-driven mindset and overcome resistance through engagement, training, and incentives. We also discussed the need for robust governance to manage data, ethics, and risk as analytics deployments grow. Finally, measuring value and iterating continuously are crucial to keep data science efforts on track and delivering impact. In sum, successful scaling of data science is a strategic, organizational, and managerial journey – one that, when done right, can transform a company’s performance and innovation trajectory.
15.1. Strategic Alignment and Leadership Commitment
Data science, at its core, is about extracting meaningful insights from data to drive informed decision-making. That sounds obvious, yet many organizations still treat analytics as a magical black box where you toss in a pile of numbers and hope a million-dollar idea pops out. In reality, data science requires a careful blend of domain expertise, rigorous methodology, and unrelenting executive sponsorship. Leadership commitment to analytics is not a “nice-to-have.” It is the bedrock that enables organizations to move from random pilots to enterprise-wide transformation. Without a clear vision and determined leadership team, even the flashiest algorithms will fail to deliver more than a handful of superficial wins.
Data science encompasses a broad range of activities, from the initial collection and cleaning of data to exploratory analyses, predictive modeling, deployment, and ongoing maintenance of models in production. For business leaders, the goal is to ensure each step aligns with the organization’s commercial strategy. For instance, a retailer might accumulate vast amounts of customer transaction data, but if they neglect to clean or structure that data properly, the resulting churn model will be about as reliable as a dart thrown in the dark. On the other hand, systematically capturing high-quality data on customer behavior sets the stage for advanced machine learning methods—such as random forests or neural networks—to identify lucrative cross-selling opportunities (Russell and Norvig, 2010).
Machine learning and deep learning techniques are especially important for executives to grasp beyond just the buzzwords. Traditional machine learning methods, like linear regression or decision trees, help solve a wide range of prediction and classification problems, while deep learning—popularized by neural networks—shines in scenarios involving large, complex datasets such as image recognition or natural language processing (Goodfellow, Bengio and Courville, 2016). Although these techniques can deliver jaw-dropping results, leaders must stay rooted in the “why.” If a deep learning model that predicts inventory needs does not tie directly to cost reduction or improved service levels, it risks becoming another unfulfilled “project.” True commercial impact emerges when the chosen data science methods directly address recognized business pain points and strategic objectives.
Real-time analytics can serve as another game-changer when it is actually needed. For example, a financial services company tracking fraudulent transactions can use streaming data and online algorithms to flag anomalies as they occur, cutting losses before they balloon. Yet not every use case requires the adrenaline rush of streaming analytics. Executives should be wary of over-engineering solutions that end up more expensive than the problem they are trying to solve. In other words, if you are building a 24/7 real-time system to optimize next month’s marketing campaign, you may be wasting time and money better spent on simpler, more pragmatic solutions (Dhar, 2013).
In the rush to adopt advanced algorithms, organizations often ignore—or pay mere lip service to—ethical considerations. It can be all too easy for models to inadvertently discriminate against certain groups or fail to respect individual privacy, triggering not only moral and reputational risks but also regulatory backlash (Chen and Lin, 2020). Business leaders must actively demand transparency in how models are trained, validated, and deployed. When data scientists operate under a cloak of secrecy—“Just trust the algorithm!”—they do a disservice to the organization and society at large. Clear guidelines for responsible AI should be integrated into company policy, ensuring the drive for commercial gains remains consistent with fair and ethical practices.
While data scientists might handle the technical heavy lifting, the success of any analytics initiative hinges on collaboration with a range of experts—from domain specialists who provide context for the data to IT teams who ensure the necessary infrastructure and robust data pipelines are in place. Senior executives play a decisive role in shaping a culture where these cross-functional partnerships thrive instead of being stifled by bureaucratic turf wars. A breakdown in communication between data scientists and frontline teams is a surefire way to end up with models that are both misunderstood and misapplied.
Unfortunately, too many organizations still operate on the assumption that the “tech people” alone can wave a wand and turn every dataset into gold. Fostering an enterprise-wide analytics culture involves demystifying data science, setting expectations, and encouraging experimentation—while also establishing guardrails to prevent chaos. When all these elements are in sync, data science shifts from a siloed side project to a core discipline woven into the corporate DNA (Provost and Fawcett, 2013).

Figure 1: Illustration of the strategic framework for maximizing data science impact, highlighting the progression from broad vision alignment to targeted resource optimization. (Image by Napkin).
Achieving impact at scale starts with a clear data science vision tied directly to the broader business strategy. Organizations worldwide are investing heavily to integrate analytics in pursuit of trillions of dollars in potential value across industries (McKinsey). Yet many companies eke out only modest returns because they fail to embed analytics across multiple functions. A coordinated, top-down strategy is needed to move beyond scattered experiments toward pervasive use of data science. This journey demands more than just a one-off pilot that produces a feel-good success story. Leaders must set concrete targets—such as reducing churn by ten percent in the next fiscal year or improving operational efficiency by a specific margin—and then aggressively align analytics resources to those objectives.
Strong, unified leadership commitment is critical. Top-performing firms are often twice as likely to have their senior leadership team fully aligned on the analytics vision, setting the tone for integrating data science in all operations (McKinsey). Senior executives must champion data initiatives, establish measurable goals (like “achieve X% improvement in supply chain efficiency”), and ensure every level of management embraces the mandate. Companies with thoroughly aligned leadership are significantly more likely to apply analytics in multiple business functions, weaving data science into daily decision-making rather than confining it to a single department (McKinsey). Without this unwavering support, even the most sophisticated data science team will end up tinkering on the fringes, unable to drive real change.
Data science projects should be selected and scoped with explicit links to the organization’s core objectives. Best-practice organizations align initial analytics work with existing business strategies, such as improving customer retention or boosting profitability (Communications of the ACM). Prioritizing high-impact use cases builds credibility and, frankly, pacifies the skeptics who would otherwise claim data science is a distraction. Early wins that connect analytics to clear operational improvements shift the internal narrative from “Why bother?” to “What else can we improve?” Cross-functional teams involving domain experts from the start help ensure solutions address actual operational bottlenecks rather than abstract data puzzles. Documenting pilot results, challenges, and lessons learned further cements the business case for broader adoption (Communications of the ACM).
Budget priorities must reflect a commitment to operationalizing analytics, not just dabbling. Leading organizations commit significant resources to data science and have plans to expand these investments, whereas laggards chronically underinvest (McKinsey). One study found that two-thirds of “breakaway” companies spent over 25% of their IT budget on analytics (compared to only 5% among those lagging behind) (McKinsey). However, top performers also devote a large portion of their analytics spend to implementing and adopting solutions—the so-called “last mile”—rather than obsessing solely over model development. Nearly 90% of analytics leaders allocate more than half their analytics budget to embedding insights into workflows, which includes training end-users, integrating models into core applications, and managing the cultural changes that come with data-driven decision-making (McKinsey). This focus on the “last mile” accelerates the translation of data science outputs into quantifiable business value.
A strategic vision for scaling data science must extend across the entire organization. Instead of confining analytics to a single department or brand-new lab on the other side of campus, companies should plan for a multi-functional rollout (McKinsey). One major retailer famously reshaped its entire business around analytics, deploying advanced capabilities in all its business units and functions, reportedly reaching tens of millions of customers. This holistic approach produced personalized marketing at scale, data-driven site selection, and a cascade of other enterprise-wide benefits (McKinsey). These results were not achieved by the analytics team working in isolation; they arose because senior leaders articulated a compelling vision, flattened silos, and promoted a data-driven mindset from the C-suite down to store managers.
Bridging the gap between ambition and results requires both strategic alignment and a relentless leadership focus on executing the vision. It is tempting to assume that investing in a handful of trendy analytics tools will unlock unlimited value. That illusion usually shatters when the C-suite realizes no single piece of software can save a poorly defined strategy or a dysfunctional culture. Data science success is as much about change management as it is about algorithms. Leaders who fail to appreciate this reality will keep throwing money at proofs of concept that never deliver commercial returns.
In contrast, an organization that invests for scale, aligns projects to core objectives, and builds a strong analytics culture will be poised to reap substantial gains. These are the companies that consistently outpace competitors who remain stuck in perpetual pilot mode. The difference boils down to leadership and strategic alignment. When top executives provide the necessary resources, articulate clear goals, and foster cross-functional collaboration, data science becomes an integral part of the corporate strategy, driving both immediate and long-term commercial benefits.
15.2. Data and Technology Foundations for Scale
A solid data foundation underpins every successful data science initiative. Contrary to popular wishful thinking, there is no shortcut: you cannot skip the “boring” parts like data governance, standardization, and architecture design if you expect your advanced analytics to hold up under real business demands. Leading organizations develop a well-defined enterprise data strategy before racing ahead with glamorous algorithms (McKinsey, 2017). This strategy identifies critical data assets and outlines how they should be captured, managed, and secured. It also defines standards for data formats, taxonomies, and ontologies so that a “sales region” in one dataset does not become “market territory” in another.

Figure 2: Illustration of the symbiotic relationship between a master data model, data catalog, and strategic data management, illustrating how they build a robust data governance framework. (Image by Napkin).
A crucial element in this foundational work is establishing a single source of truth for core business entities such as customers, products, and suppliers. Without a reliable master data model and a robust data catalog, different teams can inadvertently operate on conflicting definitions or inconsistent records, leading to fiascos like mismatched inventory systems or contradictory reporting. When data is treated as a strategic asset—governed, validated, and broadly accessible—analytics initiatives have a fighting chance of scaling enterprise-wide rather than remaining trapped in departmental silos (McKinsey, 2017).
Many organizations make the mistake of viewing data science as an artisanal craft, with each data scientist developing their own bespoke solutions in isolation. This approach might be fine for a handful of pilot projects, but it quickly crumbles once you try to deploy dozens—if not hundreds—of analytical models across multiple business units (Smith, 2020). To achieve scale, organizations must pivot to an industrialized approach.
Industrialization involves structuring the analytics lifecycle so that tasks can be repeated efficiently, reliably, and in parallel. For example, you might have dedicated data engineers focusing on ingestion, cleaning, and transformation, while modelers concentrate on creating robust predictive or prescriptive analytics solutions. ML Ops specialists then ensure that models are deployed, monitored, and updated seamlessly in production environments. This assembly-line mentality fosters collaboration, reduces duplication of effort, and allows a single data science solution to be rolled out, maintained, and improved consistently.
A key ingredient in this shift is adopting mature software development practices for data science: version control, automated testing, and continuous integration. Instead of letting data scientists keep models on personal laptops, forward-thinking companies implement shared repositories, standardized code reviews, and robust QA processes. This might feel like an administrative headache at first, but in practice it dramatically increases the consistency and reliability of results. Plus, it helps rein in the “wild west” of disconnected data science experiments that often lead to confusion and wasted budget (Smith, 2020).
Scalable data science requires more than heroic data scientists and a lofty corporate vision. It demands a technological backbone capable of handling large volumes, varieties, and velocities of data. Many organizations discover that their legacy databases—along with a tangle of manual processes—collapse under the weight of advanced analytics workloads (Brown, 2021). This realization typically drives investments in cloud-based big data platforms, data lakes or warehouses, and real-time pipelines.
These modern platforms do more than just collect data in one place; they incorporate robust data engineering pipelines to ensure quality, lineage, and compliance. Without such pipelines, a small handful of data errors or unrecognized duplicates can wreak havoc on entire models. Additionally, feature stores are increasingly used to standardize commonly used model inputs—like “average spend per customer in the last 30 days”—so that different teams do not waste time reinventing the wheel or inadvertently using slightly different definitions.
Equally important is adopting ML Ops (Machine Learning Operations) practices, which bring discipline and efficiency to model deployment and maintenance (Brown, 2021). By using model registries, CI/CD pipelines, and containerization technologies, organizations can move prototypes from data scientists’ notebooks into real-world production systems quickly and consistently. These practices also enforce monitoring and feedback loops, ensuring that models remain accurate as business conditions evolve. Nothing torpedoes the credibility of a data science team faster than a production model that fails silently and spews bad predictions for weeks before anyone notices.
Data scientists often joke that their biggest challenge is not building models but getting them deployed in a secure, scalable manner. That is where IT comes in. In a well-functioning enterprise, IT provides the infrastructure, platform services, and security layers, while data scientists supply advanced modeling capabilities to solve real business problems. However, in many organizations, the two groups exist in parallel universes, occasionally lobbing requests and complaints at each other (Smith, 2020).
The antidote is forging a genuine partnership. Some firms create “analytics pods” composed of data scientists, data engineers, business analysts, and IT developers all working together on a dedicated initiative. By involving IT from the start, data science projects can be designed with deployment considerations in mind. For instance, if your model for predicting customer churn requires near real-time updates, that has implications for how data is ingested, stored, and accessed. If that conversation happens too late, the model may never make it out of the proof-of-concept stage—or it might deploy with critical flaws.
In the best cases, this alignment leads to synergy: data science solutions are robust, maintainable, and can be scaled to thousands of users. Rather than data scientists complaining that IT is “too bureaucratic” and IT complaining that data scientists are “rogue operators,” both sides see themselves as partners delivering business value. They share responsibility for success, measure outcomes in terms of the business impact, and collectively keep solutions healthy in production. This cross-functional model is where data science truly flourishes (Smith, 2020).
As data science initiatives expand, they inevitably face increased scrutiny regarding data privacy, security, and regulatory compliance (Brown, 2021). This can come as a harsh wake-up call for organizations that initially treat advanced analytics as a skunkworks effort. The reality is that sensitive data—whether it is financial transactions, patient records, or personal identifiers—must be handled according to strict legal and ethical standards.
Adopting a robust security model from day one is thus essential. This includes access controls to limit who can see or modify data, encryption protocols to protect data at rest and in transit, and audit trails to document how information is used. In industries like finance and healthcare, regulations such as GDPR or HIPAA add extra layers of complexity. Failing to handle data responsibly is not just a blow to your brand; it can lead to substantial legal penalties.
To mitigate these risks, best-practice companies bake compliance into their data platforms and processes. They may use anonymization or tokenization techniques, implement consent management systems, and adopt explainable AI tools that shed light on how models arrive at certain decisions. These measures help organizations scale confidently, without fearing that a single compliance slip will derail all the good work done by the analytics teams.
15.3. Talent, Teams, and Organizational Structure
Data science may seem like a magical black box where algorithms solve everything, but in reality, it relies on actual humans who know how to wrangle data, interpret insights, and persuade decision-makers to act. Leading organizations recognize that scaling data science requires more than a single rock-star data scientist—it requires a broad network of specialized professionals, from data engineers to model developers and analytics translators (McKinsey, 2017). These companies invest in growing deep expertise across multiple domains, rather than hoping one “jack-of-all-trades” wizard can handle everything from data cleansing to front-end reporting.
Practical experience shows that the best results come when you put experts in roles that match their strengths. A data engineer can tackle the joys of pipeline construction and data cleaning, while a data scientist focuses on advanced statistical modeling or deep learning. Meanwhile, a data translator collaborates with business stakeholders to ensure the models address real problems—like churn prediction or fraud detection—rather than chasing academic curiosities. By scaling up this cross-functional expertise, organizations can tackle more complex projects and drive measurable commercial outcomes.
Equally important is strong executive sponsorship. It is not enough to have data scientists working in the basement on pet projects. Leading companies elevate data science to the C-suite or near it. Today, more than 70% of large enterprises have established a Chief Data Officer (CDO) or Chief Analytics Officer (CAO) role (NewVantage Partners, 2022). These executives secure budgets, champion data initiatives among senior leaders, and shape the broader corporate vision so that data science does not remain a side hobby. When data is treated as a strategic asset from the top, the entire organization is more likely to follow suit.
One of the biggest structural decisions organizations face is whether to centralize data science in a single hub or decentralize it across various business units. Many top performers opt for a hybrid: a central analytics Center of Excellence (CoE) provides governance, common tools, and shared best practices, while smaller teams embedded in each business domain deliver solutions tailored to local needs (McKinsey, 2017). The CoE, often led by a Chief Analytics Officer, serves as the nerve center for advanced techniques—such as neural networks, real-time analytics, or AI ethics reviews—and ensures the entire enterprise benefits from cutting-edge knowledge.
Meanwhile, cross-functional, agile teams in the business units handle day-to-day model building and deployment. These teams typically include data scientists, data engineers, frontline managers, and analytics translators working together in sprints. For instance, a retailer might form a squad to improve inventory forecasting. The data engineer sets up real-time data feeds from point-of-sale systems, the data scientist refines a machine learning model for demand prediction, the domain expert provides insights into seasonal patterns (like back-to-school surges), and the translator ensures the final solution is embedded seamlessly in store managers’ workflows. This interplay prevents analytics from becoming a distant technical function and instead makes it an integral part of commercial operations.
Figure 3: Illustration of data talent engagement, highlighting the importance of clear career pathways, addressing workplace challenges like monotony, and implementing effective organizational strategies such as ongoing development. (Image by Napkin).
Securing top-tier data talent is hard enough; keeping them engaged and motivated can be even trickier. Data professionals often thrive on variety and challenge. If they find themselves repeatedly building the same regression models for months on end, they will likely polish their résumés and head for a more stimulating environment. Leading organizations preempt this by structuring career pathways that encourage ongoing development (McKinsey, 2017). Rather than pushing data scientists to follow the conventional IT hierarchy, these firms offer dual tracks: a technical track for those who want to become subject-matter experts and a managerial track for those who prefer leading teams.
Some companies have also introduced rotational programs where data scientists cycle through different departments—such as marketing analytics, supply chain optimization, and customer experience—before settling into a specialization. This approach keeps the work fresh, fosters cross-pollination of ideas, and helps build a company-wide analytics community. It also ensures that each business unit eventually benefits from individuals who have gleaned best practices elsewhere.
Retention is further boosted by providing robust training and educational opportunities. With artificial intelligence evolving rapidly, skilled professionals often demand access to the latest tools and techniques, whether that is deep learning frameworks or advanced ML Ops platforms. Firms that invest in these learning experiences demonstrate that they value staying at the forefront of innovation, which in turn fosters loyalty and a sense of shared mission.
It is easy to assume that data scientists are the only ones who need quantitative proficiency. In truth, building a data-driven enterprise requires elevating the data literacy of everyone, from the interns to the board of directors (MIT Sloan, 2021). For instance, a marketing manager might not need to code in Python, but they do need enough comfort with data to interpret model outputs and detect potential biases. Similarly, a frontline sales rep should know how to read performance dashboards and glean actionable insights about customer segments.
Executives who ignore these upskilling efforts often see their carefully crafted models gather dust. When managers are ill-equipped to leverage analytics, they fall back on gut instincts, effectively undermining the entire data-driven transformation. In contrast, companies that introduce broad data literacy programs—through e-learning modules, in-person workshops, or internal “data academies”—discover that employees gradually adopt a more analytical mind-set. Over time, mid-level managers can hold their own in discussions about model performance metrics or weigh in thoughtfully on trade-offs between precision and recall in a fraud detection system.
One global bank reportedly made analytics expertise a prerequisite for managerial promotions. Candidates were required to demonstrate their ability to interpret data outputs and use them to drive decisions. This policy shift resulted in a cadre of mid-level managers who eagerly embraced analytics and actively collaborated with data scientists (McKinsey, 2017). By tying career advancement to data fluency, organizations align individual incentives with the broader analytics strategy.
There is no “one-size-fits-all” solution for structuring an analytics organization. Smaller firms often find that a single, centralized data science team, reporting directly to an executive sponsor, works best. Larger enterprises, however, may need a more nuanced approach. They might start with a centralized hub to build critical mass, then spin off domain-specific units as data science gains traction. Over time, a “hub-and-spoke” model often emerges, with a central CoE handling overarching governance, platform management, and advanced research while smaller satellite teams focus on applying analytics within their particular functions (Smith, 2021).
Regardless of the model, clear communication channels are essential. Shared knowledge reduces redundancy—nobody likes discovering that a neighboring department has already built the predictive churn model you have been laboring over for six months. Many leading companies establish internal data science councils or communities of practice where teams present case studies, swap lessons learned, and debate best practices. This cross-pollination prevents silos from reemerging and helps unify the organization around common data standards and norms.
As an analytics capability grows, it is wise to periodically review the organizational structure. Early-stage solutions may require a small, nimble team of generalists. Once the company matures, you may need specialized squads for advanced AI research, ML Ops infrastructure, or ethical compliance to handle regulated industries. What worked well at 10 data professionals might not scale at 100 or 1,000.
15.4. Data-Driven Culture and Change Management
Most organizations talk about “becoming data-driven” as though installing the latest AI platform will magically fix their decision-making. The truth is far simpler—and more painful: technology alone cannot force people to change long-held habits, biases, and corporate norms. Executive surveys consistently identify culture, rather than tools, as the chief roadblock to data-driven transformation (NewVantage Partners, 2022). An astonishing 91.9% of firms surveyed pointed to culture (such as mindsets and organizational inertia) as the factor impeding analytics adoption. Only 8.1% blamed technology. Despite massive investments in analytics, fewer than 26% of firms reported having created truly data-driven organizations, and a meager 19% had achieved a data-centric culture (NewVantage Partners, 2022).
Figure 4: Illustrationo of a successful shift to data-driven decision-making requires not only technical changes but also addressing the human element, such as emotional resistance and fear of redundancy. (Image by Napkin).
The bottom line is that simply installing a new predictive analytics tool or recruiting an elite data science team will not magically convert a company to data-based thinking. Shifting culture requires deliberate, persistent effort to instill values of evidence-based decision-making and encourage employees at all levels to let go of the “we’ve always done it this way” mentality (Communications of the ACM, 2019). This usually means that data initiatives must tackle emotional resistance, organizational silos, and the fear of obsolescence lurking behind the scenes. After all, it is not merely about adopting fancy dashboards; it is about adopting a new mindset: experiments trump assumptions, data can contradict gut feelings, and yes, you might need to stop trusting the instincts that once made you successful.
Practical Example: Consider a traditional manufacturing firm that has run its supply chain on the judgment of a few seasoned planners for decades. When the company introduced a predictive model to forecast demand, those planners quietly ignored the model’s recommendations—after all, they had “been doing this for thirty years.” It took a cultural shift, championed by a new operations VP, to insist on data-informed decisions. Over time, regular reviews of forecast accuracy and visible successes—like reducing stockouts and cutting inventory costs—helped even the most skeptical employees recognize the value of analytics. This transformation would not have happened if the new system had simply been dropped into place without addressing the planners’ concerns and ingrained habits.
Deep down, most employees worry that automation and analytics might undermine their contributions or, worse, replace them altogether. This fear can lead to subtle sabotage or outright rejection of new tools. The best remedy is to involve stakeholders early, ensuring they understand that data science augments their expertise rather than overshadowing it (Communications of the ACM, 2019).
Engagement starts by pulling domain experts and frontline managers into the problem-formulation stage. If an analytics solution is supposed to help store managers optimize staff scheduling, for instance, then those managers should be co-designers of the solution. Their input on variables that matter—seasonal trends, local events, or even staff preferences—makes the model more accurate, and they feel a sense of ownership from day one. By contrast, if the analytics team develops a scheduling model in isolation, managers may not trust the output or may find it too rigid.
Equally important is communicating success stories. Highlight how a small pilot team used data to beat sales targets or reduce downtime on the factory floor. Award them internal recognition, make their wins visible, and show that data-driven decisions are not just some fleeting initiative but a new way of working (Communications of the ACM, 2019). These “champions” become beacons of what is possible, calming the nerves of others who fear analytics is just the latest in a parade of corporate fads.
One of the biggest mysteries of data science is why good models fail to gain traction. The short answer: People do not use them. They remain a technical curiosity, collecting digital dust in the corner of an internal portal. The “last mile” challenge—actually embedding insights into everyday operations—is where data science initiatives often stumble (McKinsey, 2017).
In practice, embedding analytics means integrating it directly into the tools and workflows that employees already use. A store manager typically manages staff, orders, and customer service through a specific system or dashboard. That is exactly where your predictive insights should appear. Perhaps there is a simple screen highlighting projected foot traffic for the next week and recommending an optimal staffing ratio. If you expect the manager to open a separate advanced analytics app that looks alien and demands half a day of training, do not be surprised if adoption lags.
Successful “last mile” efforts tailor insights to each user group, presenting only the metrics and visualizations relevant to their role. Some companies offer natural language query tools so managers can type “How many units should I order next week?” and see a quick answer. Others deliver real-time alerts to employees’ mobile devices. The key is frictionless integration. An employee should not have to wrestle with a labyrinth of drop-down menus to find something as basic as yesterday’s sales by product category. When analytics are quick, accessible, and actionable, people rely on them more readily—and the culture shifts as data-driven decision-making becomes second nature (McKinsey, 2017).
While user-friendly interfaces help, organizations must also invest in raising overall data literacy. Even the best dashboards fall flat if the managers and staff reading them cannot interpret what they see or do not understand the underlying statistical principles (Communications of the ACM, 2019).
Many companies now launch “data academies,” where employees at every level learn core data concepts. A frontline employee may receive training on reading basic charts, while a mid-level manager learns about common analytical pitfalls like correlation vs. causation. More advanced roles might explore machine learning methodologies and best practices for validating models. This layered approach helps each group gain the right level of competence.
Beyond formal training, culture changes when leaders openly reference data in meetings. A CFO who starts quarterly reviews by saying, “Let’s look at the numbers,” rather than “Here’s my gut feeling,” sends a powerful signal. Similarly, awarding promotions or bonuses to those who champion data-driven solutions is more than a carrot; it shows the organization values hard evidence over personal hunches. Over time, employees begin to see that using data is not just a chore but an integral part of how the company conducts business.
Unlike a one-and-done software launch, shifting to a data-driven culture requires an ongoing change management strategy. A formal plan might identify specific milestones—such as training completion rates, usage metrics for newly deployed dashboards, or the rollout of analytics “ambassadors” within each department (Communications of the ACM, 2019). It should also include a timetable for communication events, like company-wide updates and departmental Q&A sessions, to keep analytics top of mind.
Realigning incentives is crucial. If managers are only measured on short-term revenue gains, they might be reluctant to spend time exploring new analytical tools. In contrast, if part of their performance review includes a metric on data adoption—such as the percentage of decisions informed by a specific analytics platform—they will be more inclined to engage. A balanced approach ties data usage to tangible outcomes while also recognizing that some data-driven experiments will fail. Organizations that embrace the occasional failure as a necessary step in innovation are more likely to see analytics flourish in the long run.
Above all, executive leaders must practice what they preach. If the CEO herself consistently references data in decisions, welcomes contradictory evidence, and encourages managers to use analytics, that attitude permeates the organization. Cultural transformations rarely survive when top leaders say one thing—“We are all about the data!”—but behave in ways that prioritize politics or gut feelings. Over time, if the workforce sees that data is not optional and is integral to success, the organization can achieve the elusive goal of becoming genuinely data-driven, not just in mission statements, but in everyday practice.
15.5. Governance, Ethics, and Risk Management
At first glance, the notion of data governance might sound like a dull administrative chore—a bunch of policies and committees designed to slow everything down. The reality is that effective data governance is what keeps a fast-growing analytics operation from collapsing under its own weight. When organizations scale data science, they inevitably multiply the number of data sources, models, and stakeholders. Without clearly defined roles, policies, and standards, the result is a messy tangle of inconsistent reports, unverified data sets, and inevitable compliance nightmares (McKinsey, 2017).
A robust data governance program starts by establishing clear accountability. Leading firms appoint owners for critical data domains such as customer records or financial transactions, making them responsible for data accuracy, consistency, and access. This does not mean they have a personal monopoly on that data; it means they coordinate policies, definitions, and quality standards so that every business unit refers to “customer lifetime value” in the same way. Well-run governance councils or committees can orchestrate decision-making across multiple teams, ensuring that the product data used by marketing is compatible with the product data used by finance, rather than existing as warring versions of the truth.
Figure 5: Illustration of a strategic approach to data governance involves stratifying data into levels of sensitivity, ensuring that high-risk data is rigorously protected, while lower-risk data is managed with appropriate flexibility. (Image by Napkin).
Another crucial dimension is stratification: not all data is created equal. Some data—like personal health information or core customer profiles—is simply too sensitive or mission-critical to be stored and processed without rigorous controls. Other data sets—like certain website clickstream logs—might carry fewer compliance risks and can be handled with lighter governance. This tiered approach, where the highest security and quality requirements apply only to the most critical data, helps companies channel their governance resources effectively instead of smothering every dataset with maximum bureaucracy (McKinsey, 2017).
Organizations that take governance seriously also invest in data catalogs, dictionaries, and quality monitoring tools to keep data “fit for purpose.” A well-maintained data catalog is like a library index that shows who owns the data, where it is stored, what format it uses, and who is allowed to access it. This might seem tedious initially, but when cross-functional teams start building machine learning models, they do not have to waste weeks chasing down the definition of “revenue” across multiple spreadsheets or verifying the lineage of untagged datasets. In short, governance is not just about compliance—it is the invisible scaffolding that lets data science scale without devolving into chaos.
Data science can do remarkable things: it can recommend the ideal product to your customers, identify potential fraud before it happens, and optimize your supply chain with uncanny precision. It can also wreck your brand if deployed irresponsibly. A single public scandal—like an AI system that inadvertently discriminates against certain demographics or a data breach that exposes millions of customer records—can undermine all the progress your analytics team has made (NewVantage Partners, 2022).
Many organizations are now grappling with ethical questions around bias and fairness. Models are not immune to prejudice if they are trained on historical data riddled with societal inequalities or incomplete demographics. For instance, a loan-approval model that disproportionately rejects applicants from certain neighborhoods could land a bank in hot water for discriminatory lending practices. These risks become even more pronounced as regulations catch up with the rapid expansion of AI.
Forward-looking companies establish clear guidelines and internal committees to tackle these ethical challenges. Some create an “AI Ethics Board” that reviews high-stakes use cases—such as algorithmic hiring or predictive policing—to ensure the models pass fairness and transparency tests. Others integrate bias detection into their standard model development workflow, requiring data scientists to run checks that compare error rates across demographic groups (NewVantage Partners, 2022). Explainability is another big concern, especially for regulated industries. If a customer is denied insurance based on a black-box neural network, regulators and consumers alike may demand a logical explanation for the decision. Indeed, “trust” is the ultimate currency in data-driven relationships—losing it can cost far more than any short-term gains from a slick new AI model.
Another layer of ethical responsibility involves data privacy. Regulations like the General Data Protection Regulation (GDPR) in Europe or the California Consumer Privacy Act (CCPA) in the United States impose stringent requirements on how customer data can be collected, stored, and used. A successful data-driven organization cannot just rely on a “move fast and break things” ethos; it must incorporate data privacy checks at every stage—obtaining explicit consent where needed, anonymizing or tokenizing sensitive data, and having a plan for prompt breach notification if the worst happens. Firms that proactively embed privacy and ethics in their analytics strategy often discover a competitive advantage in the market: customers feel safer sharing data, regulators view them as responsible innovators, and internal teams can innovate with fewer legal or reputational worries.
From financial services to healthcare, regulated industries have always faced a tricky balance: embrace cutting-edge analytics while staying within strict compliance bounds (Communications of the ACM, 2019). Regulators might demand audit trails that explain how a model arrived at a particular decision, or impose periodic stress tests to prove the model remains valid under different scenarios. In some cases, data-driven credit scoring or insurance underwriting must pass muster with agencies that require evidence of non-discriminatory practices and transparency for consumers.
Integrating compliance into the data science pipeline from the outset can save substantial time and headaches later. For example, a bank building a machine learning algorithm for credit risk might incorporate model interpretability frameworks like SHAP (SHapley Additive exPlanations) to explain the relative influence of different variables on a borrower’s risk score. This sort of built-in transparency can go a long way toward satisfying regulatory auditors and easing concerns from consumer advocacy groups.
A practical best practice is maintaining an inventory of all production models, along with details about their training data, performance metrics, and intended use cases. This documentation makes it easier to respond quickly if a regulator or internal risk management team questions a model’s fairness or performance. It also helps avoid the “we lost track of that old model in the corner” syndrome, which can lead to outdated or unmonitored algorithms still making important decisions.
Far from being an obstacle to innovation, compliance can act as a catalyst for well-structured analytics programs. By working closely with legal and compliance teams, data scientists can design workflows and governance practices that not only meet regulatory requirements but also encourage more robust and reliable models. Firms that treat compliance as a critical design element often build more resilient analytics solutions, which ultimately translate into better business outcomes.
The more data science grows, the bigger the target it becomes for cyber threats. Every new data pipeline, third-party API, or user dashboard could be an entry point for hackers. Additionally, the models themselves can become attack surfaces—consider adversarial examples in computer vision, where carefully manipulated inputs can fool AI systems into false predictions. Organizations that fail to take a proactive stance on security can find themselves with compromised models or leaked datasets, eroding customer trust in a heartbeat (Deloitte, 2020).
One common tactic is enforcing a strict “need-to-know” principle. Data scientists might have access to anonymized or aggregated data rather than raw personal details. Encryption at rest and in transit is now standard for sensitive data. Regular security audits, penetration tests, and intrusion detection systems help keep an eye out for potential weaknesses. These measures are non-negotiable; in the absence of robust security, even the slickest machine learning solution becomes a liability.
Another dimension of risk involves what happens after models are deployed at scale. Model performance can degrade over time as market conditions or consumer behavior changes—a phenomenon known as “model drift.” Moreover, models that automate critical decisions could fail spectacularly if they encounter data outside the range of their training. Leading organizations therefore implement model risk management (MRM) processes, which include ongoing monitoring of predictive accuracy, bias checks, and fallback procedures if the model’s performance dips below a threshold (Deloitte, 2020).
Finally, accountability matters. If a pricing algorithm suddenly inflates rates for a segment of customers due to a hidden data bias, who is responsible for spotting that error and rectifying it? Clear lines of ownership—whether it is the data science team, the product owner, or a dedicated model risk function—ensure that issues get caught and resolved promptly. By establishing these controls upfront, companies can harness the power of advanced analytics without fear of stumbling into catastrophic errors or well-publicized scandals.
15.6. Measuring Impact and Demonstrating ROI
Data science is often praised as a powerful catalyst for innovation, but it can also turn into a money pit if projects are selected without a clear link to business objectives. Leading organizations avoid the trap of “analytics for the sake of analytics” by relentlessly focusing on impact (Communications of the ACM, 2019). They ask pointed questions at the outset: Which strategic pain points are we trying to address? How will this initiative increase revenue, reduce costs, or enhance customer loyalty? If the value proposition is murky, even the most advanced algorithm is unlikely to impress your CFO.
A more effective approach is to start with a clear business case. Suppose your goal is to reduce customer churn by 10%. You then design a data science project to identify at-risk customers and deliver personalized offers. By framing the project around tangible outcomes—a known metric with an associated financial impact—stakeholders can rally behind the effort. Executives will understand the “why” and can allocate resources with confidence (MIT Sloan, 2021). If the pilot is successful, it is easier to justify scaling the solution across multiple business units or regions.
This mentality extends beyond large, headline-grabbing use cases. A modest improvement in operational efficiency (like automating a manual process for invoice reconciliation) may yield significant cost savings once it is rolled out globally. The secret is not always chasing the flashiest AI project but identifying the right combination of feasibility and payoff. High-performing organizations maintain a pipeline of analytics ideas, each tied to a potential ROI, so they can prioritize and sequence projects systematically.
The old adage “What gets measured gets managed” applies doubly to data science. Without clear KPIs, even the best analytics teams can find themselves locked in endless proof-of-concept limbo, churning out fancy PowerPoint slides that do not move the financial needle. The most effective data science programs define KPIs at the start of each project and track them throughout the initiative (Communications of the ACM, 2019).
Figure 6: Illustration of the multidimensional nature of success measurement, emphasizing that effective KPIs must span financial performance, process optimization, risk mitigation, and technical accuracy. (Image by Napkin).
These KPIs might be strictly financial—like profit uplift or incremental revenue—or they might relate to process improvements, such as reducing stock-outs by a specific percentage. They could also be risk-related: for example, measuring how a new fraud detection model reduces chargebacks in a retail setting. Often it is helpful to have a blend of metrics. A model’s technical accuracy (precision, recall, or mean absolute error) might confirm you have built something robust, but the real proof is how that technical accuracy translates into measurable commercial outcomes.
Some organizations embed these KPIs into enterprise dashboards to keep them in plain sight. A retailer might track not only the number of advanced analytics projects in flight but also the aggregated ROI of those projects, effectively treating data science as a strategic portfolio. When non-technical stakeholders see these metrics—in monthly reviews, for instance—they gain concrete proof that data initiatives are not just an R&D playground but a genuine driver of performance. This transparent, metrics-driven approach can also diffuse internal skepticism: if you can point to a consistent track record of delivering value, executives are more likely to greenlight further analytics investments. Indeed, one global survey found that nearly 92% of mature AI adopters reported measurable business benefits from their data and AI investments (NewVantage Partners, 2022).
Data science projects, like living organisms, require constant care and feeding. A model that thrived six months ago could degrade if underlying customer behavior changes or if you start collecting data from new channels. Leading companies treat analytics initiatives as an evolving portfolio, continually monitoring performance against expectations (Communications of the ACM, 2019). Projects that fail to meet their forecasted ROI are subjected to root-cause analysis: Was the model flawed? Did the business process fail to adopt the insights? Or did market conditions shift unexpectedly?
Rather than viewing “failed” projects as a waste, these organizations glean valuable lessons to refine their processes. For example, a predictive maintenance system might overestimate how frequently a factory’s machinery needs servicing. That insight can lead to adjustments—either by fine-tuning the model’s parameters or by incorporating new data sources (like environmental conditions or production volume). Meanwhile, successful projects are expanded and used as blueprints for subsequent initiatives. A “pilot, measure, refine, scale” cycle ensures that each phase of analytics deployment is informed by real-world evidence rather than wishful thinking.
This portfolio mindset also helps executives make tough trade-offs, shifting resources away from underperforming efforts and doubling down on high-impact wins. Much like financial portfolio management, the aim is to optimize returns while diversifying risk. Over time, the entire organization matures in its ability to estimate analytics ROI, reduce time to value, and steer the most promising initiatives to success.
Brilliant data insights are useless if nobody knows about them—or, worse, if the people who should be acting on them are never informed. Many organizations stumble at the finish line by failing to broadcast their data science achievements. Communication is not just about self-congratulation; it is how analytics teams gain the organizational clout to scale (MIT Sloan, 2021).
An effective tactic is to create short case studies that translate technical jargon into real-world impact. Instead of bragging about “XGBoost algorithms” and “convolutional neural networks,” emphasize outcomes: “We reduced returns by 15% in Q2, saving an estimated $2 million.” This kind of impact story resonates with C-suite audiences and builds trust in the analytics function. Some companies even hold “demo days” or internal roadshows where data science teams show off their newest models to executives, middle managers, and frontline teams alike. These events not only spread awareness of what is possible but also spark new ideas for cross-functional collaboration.
Regular, transparent updates to senior leadership are equally important. A quarterly review might highlight the current pipeline of data science initiatives, each with a predicted or actual ROI. By including both successes and failures—and the lessons gleaned from each—analytics leaders signal a mature approach that values continuous improvement over mere optics. This openness can be disarming to skeptical stakeholders, demonstrating that data science teams are not hiding behind vanity metrics but are committed to genuine business impact. Over time, these communication efforts weave data science into the broader corporate narrative, establishing it as a vital driver of commercial strategy rather than a niche technical function.
15.7. Continuous Improvement and Innovation
Developing and deploying a new analytics model can feel like crossing the finish line of a marathon. But in the world of data science, that “finish line” is actually just the halfway point. Models are never “set and forget.” Over time, your customers’ behaviors evolve, your product lines expand, and market conditions shift—any of which can make once-accurate models obsolete if they are not actively maintained (Deloitte, 2020).
Leading organizations adopt a mindset that models are “living” assets, subject to continual refinement and retraining. They implement automated monitoring to track how well models perform against key metrics in real-world settings. If performance dips below a certain threshold—perhaps customer churn predictions are off by more than five percent—it triggers an alert for investigation. Sometimes the culprit is new data that the model has never seen, such as a product launch or external event. Other times, the model may need fresh features or an updated training set.
Practical Example: Consider an e-commerce company that uses a recommendation engine for personalized product suggestions. Initially, this model might boost sales by 15%. Over six months, however, new product categories are introduced, and customer preferences shift. If the recommendation engine is not retrained, sales could slip back toward previous levels. With a robust maintenance workflow—scheduled model retraining and frequent performance checks—data scientists can detect and address the drop, ensuring the engine continues to deliver value.
A strong maintenance culture also includes a feedback loop between business users and the analytics team. If a store manager reports that the new demand forecasting model consistently underestimates holiday spikes, that anecdotal intelligence should funnel back to the data scientists, who might adjust the training data to account for seasonality more explicitly. Embedding MLOps practices—like version control for models, automated testing, and continuous integration—helps streamline these updates (Deloitte, 2020). By viewing model maintenance as an ongoing commitment, organizations avoid the all-too-common fate of once-promising analytics tools gathering dust.
Once data science extends across multiple functions and locations, you face a new challenge: how do you keep track of dozens or even hundreds of models simultaneously influencing decisions? The risks of ad-hoc governance are high—duplicated efforts, inconsistent standards, and uncertain accountability if a model fails spectacularly. High-performing organizations address this by implementing structured model management (McKinsey, 2017).
A formal model registry acts as a central repository with essential details about each algorithm, such as who owns it, what data it uses, and when it was last updated. This documentation is especially crucial for regulated industries like finance or healthcare, where explaining a model’s lineage and rationale to auditors might be a monthly occurrence. Some companies establish a Model Risk Management (MRM) function, originally found in banking, to vet models before and after deployment. These teams conduct regular “audits,” verifying that the model still achieves acceptable levels of accuracy and does not discriminate against protected groups.
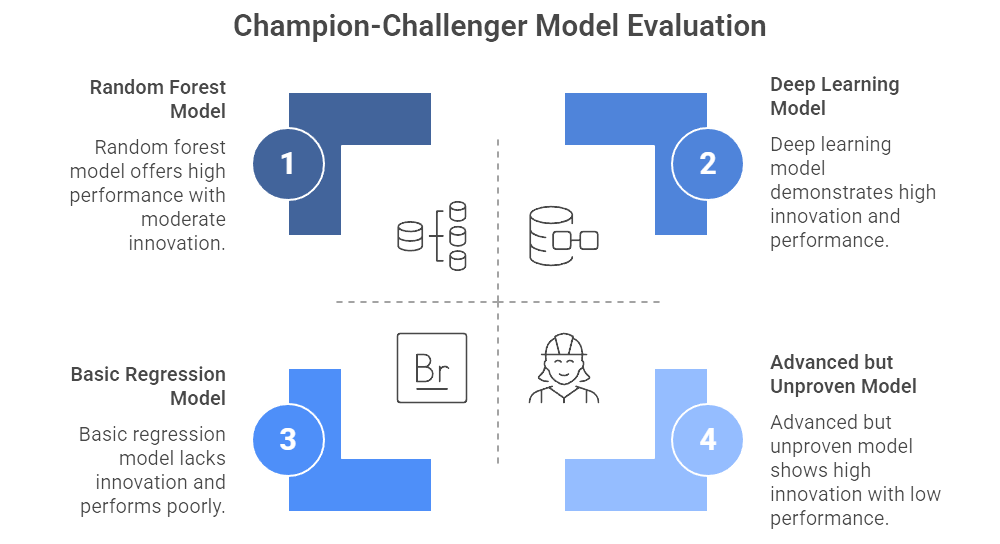
Figure 7: Illustration of a strategic evaluation of models, using the Champion-Challenger framework, balances the desire for innovation with the necessity of proven performance, guiding data-driven decision-making. (Image by Napkin).
Best-practice organizations also utilize champion-challenger frameworks. The champion model is the one currently in production—churning out recommendations, forecasts, or risk assessments. The challenger is a new or improved model, which silently runs in parallel, offering predictions that are compared behind the scenes. If the challenger consistently outperforms the champion, it takes over in production. This ensures the organization is constantly testing new techniques—like random forests or deep learning—without risking sudden disruption if a new approach fails. McKinsey (2017) found that companies with top-tier analytics programs are more than twice as likely to keep “challenger models” on standby, ensuring a built-in mechanism for innovation and quality control.
Data science does not stand still. New machine learning libraries, deep learning architectures, and analytical techniques pop up with dizzying frequency. Meanwhile, your organization’s competitive landscape changes, new data sources become available, and consumer demands evolve. Firms that rest on their laurels—thinking “our models are good enough”—quickly discover that their once-cutting-edge capabilities are losing ground (McKinsey, 2017).
Innovation can take many forms. It might be exploring advanced methods like natural language processing to analyze text-based customer feedback, or leveraging sensor data for real-time analytics in manufacturing. Some organizations set up dedicated “innovation squads” or R&D pods within their data science department to experiment with the latest approaches. These teams often work on short pilot projects—no more than a few weeks—before deciding whether to scale the new solution or shelve it.
A pragmatic way to fuel innovation is to partner with academic institutions or startups, tapping into emerging research or niche expertise. Another tactic is running internal hackathons, where data scientists are freed from their usual tasks to tackle bold challenges—like building a prototype AI model that forecasts global commodity prices. The key is to strike a balance: maintain a core focus on near-term business impact, but reserve some bandwidth for high-risk, high-reward experimentation. The lessons learned, even from failed experiments, often catalyze breakthroughs elsewhere.
Data science often starts as a series of localized wins. One department might reduce fraud by 20% with a new detection algorithm, or a supply chain team might save millions through better inventory optimization. The real magic happens when these breakthroughs are replicated and refined across different business units and markets (McKinsey, 2017).
To achieve this, organizations must capture and share knowledge systematically. An internal “analytics knowledge base” might document each project’s objective, the data sources used, the algorithms tried, and final outcomes. Teams across the globe can browse this library for inspiration—“Oh, our colleagues in Europe tackled a similar challenge with a Bayesian approach; maybe we can adapt that for our region.” Some companies run internal conferences or demo days where teams show off their best work, encouraging cross-pollination of ideas.
Scaling also demands the right infrastructure. Suppose a logistics division in South America has built a superb predictive maintenance model for delivery trucks. To extend this to other continents, the company might need standardized data pipelines, ensuring that sensor data from trucks in Asia is collected and formatted in the same way. The more harmonized the underlying data and platforms, the easier it becomes to replicate solutions across the enterprise, accelerating time to value.
This expansion is often guided by a roadmap that identifies which areas are ripe for analytics next. Maybe after tackling inventory optimization, the next logical step is workforce scheduling, followed by strategic pricing. Each successful deployment not only yields ROI but also fosters a data-driven culture—employees see that analytics is not just hype but a reliable method of solving real problems. Over time, the organization’s capability grows from isolated pockets of excellence to a pervasive data science ecosystem that spans every function and department.
15.8. Conclusion and Further Learning
Data science initiatives can be transformative, but their real power is unlocked only when they scale beyond small teams and proofs of concept. Throughout this chapter, we saw that achieving scale is not a purely technical endeavor – it hinges on leadership, alignment, and persistent execution. Companies that have succeeded treated data science as a strategic business function, with executives setting a clear vision and integrating analytics into the very fabric of how the organization operates. They invested in the often “unseen” foundations like data quality, governance, and cross-functional processes, knowing that flashy algorithms mean little without the right data and context. A critical insight is that culture can make or break these efforts: organizations must proactively manage change, educate their workforce, and create an environment where data-driven decision-making is the norm. When data science is embraced culturally (not just technologically), it shifts from being a series of projects to becoming an ongoing capability of the enterprise.
Equally important is the commitment to sustain and evolve data science initiatives over time. Leading firms establish feedback loops to measure the business impact of models and continuously improve them. Rather than declaring victory after a successful pilot, they ask “What’s next?” – expanding use cases, refining models as conditions change, and exploring new frontiers of AI and analytics. They institutionalize learning so that each project builds momentum for the next. This adaptive mindset ensures that data science doesn’t stall out after initial wins, but instead delivers compounding returns. In conclusion, scaling and sustaining data science is a journey of continuous improvement across people, process, and technology. For executives, the reward of navigating this journey is significant: an organization that consistently leverages data as a strategic asset, innovates faster, operates more efficiently, and competes more effectively in a data-driven world. By heeding the best practices and insights outlined in this chapter, business leaders can guide their companies to become truly data-powered enterprises, reaping the benefits for years to come.
Even with a solid understanding of how to scale and sustain data science programs, there is immense value in probing deeper and applying these concepts to specific contexts. The following prompts are designed to encourage further exploration and critical thinking. They invite you to reflect on the nuances of implementing data science at scale, consider different industry scenarios, and engage with the material in a hands-on way. By tackling these questions, you can deepen your insight into strategic decision-making for analytics and prepare to address real-world challenges. Use these prompts to guide discussions with colleagues, as journaling topics, or as research questions to investigate current best practices. Each prompt is an opportunity to connect the chapter’s high-level lessons with practical, detailed applications – solidifying your learning and uncovering new perspectives. Embracing these explorations will not only reinforce your knowledge but also empower you to become a more effective leader in driving data science initiatives. Let’s dive into some thought-provoking questions and scenarios:
Business Strategy Alignment – Choose a specific industry (e.g. retail, healthcare, finance) and identify three business challenges that are well-suited for data science solutions. How would you align a data science initiative with each challenge to ensure it supports the company’s strategic goals? Consider the key stakeholders to involve and the metrics you’d use to define success.
Executive Sponsorship – Imagine you are briefing the C-suite of a traditional manufacturing company on why they should invest in scaling data science. What key points would you highlight to get their buy-in? Outline a brief “elevator pitch” that links advanced analytics to competitive advantage in their context, addressing potential concerns an executive might raise.
Assessing Data Readiness – Conduct a quick data maturity audit for an organization of your choice. What gaps in data quality, accessibility, or governance might hinder their analytics scaling? List the top improvements needed (such as integrating data sources or establishing data standards) and propose a roadmap to address them.
Organizational Models – Debate the pros and cons of different organizational models for data science (centralized team vs. decentralized in business units vs. hybrid). Which model do you think works best for a global consumer products company and why? Consider factors like speed of innovation, consistency, domain knowledge, and control.
Talent Acquisition vs. Upskilling – You have a limited budget to grow your data science team. How would you balance hiring new specialists versus upskilling existing employees? Describe a strategy for building the needed skills (data engineering, machine learning, domain expertise) within a year. What roles are top priority, and how will you retain valuable talent?
Role of the Chief Data Officer – Explore the evolving role of the CDO/CDAO in enterprises. In what ways should a Chief Data Officer influence company strategy beyond managing data (for example, driving cultural change or identifying new data-driven business opportunities)? Provide examples of initiatives a CDO could lead to embed analytics deeper into the business.
Fostering Data Culture – Design a data culture campaign for an organization where decisions have historically been made by gut feel. What activities and messaging would you implement over six months to encourage employees to use data in their decisions? Think about training programs, internal communications, leadership behaviors, and incentive changes that could shift mindsets.
Analytics Use Case Prioritization – If you were tasked with selecting 5 high-impact data science projects for the next year in your company, how would you prioritize them? Draft a set of criteria (e.g. potential ROI, feasibility, strategic alignment, sponsor buy-in) to evaluate ideas. Apply these criteria to a few example project ideas and decide which to pursue first and which to defer.
Scaling a Pilot Project – Suppose your team developed a successful predictive model in one region or department. What is your plan to scale it organization-wide? Outline the steps required: from securing executive support, adapting the model to new contexts, providing training to new users, to setting up the necessary data pipeline in other regions. What challenges might you face during scale-out and how would you overcome them?
Cross-Functional Collaboration – Consider a scenario where the data science team and IT team have misaligned goals, causing friction in deploying models. How would you facilitate better collaboration between these functions? Propose specific actions such as joint planning sessions, shared KPIs, role clarification, or cross-training, and explain how these would improve the end-to-end process.
MLOps Implementation – Explore the concept of MLOps (Machine Learning Operations) in practice. What tools and processes would you put in place to support continuous integration, delivery, and monitoring of ML models in production? Describe a lifecycle from development to deployment for a model, highlighting how MLOps ensures reliability and scalability.
Ethical Considerations – Identify a potential ethical dilemma in a data science initiative (for example, using customer data for personalized marketing, or an AI model that could inadvertently disadvantage a group). How should the organization address this issue? Formulate a brief ethical guideline or policy that would govern this situation, and suggest oversight mechanisms (such as an ethics review board or bias audits) to uphold responsible AI use.
Measuring Data Science ROI – Design a scorecard for tracking the performance and ROI of data science projects in a portfolio. What metrics would you include to capture both technical performance and business impact? For instance, how would you measure model quality, user adoption, and financial returns? Describe how you would communicate this scorecard to senior management each quarter.
Case Study Analysis – Research a real-world company known for its analytics prowess (e.g. Netflix, Amazon, or Google). What strategies did they use to scale up their data science capabilities? Summarize one case where data science led to a significant competitive advantage or innovation for that company. What lessons from that case could apply to other organizations looking to follow a similar path?
Handling Project Failures – Not all data science projects succeed. Imagine a scenario where a high-profile analytics project in your company did not deliver expected results. How would you handle the aftermath constructively? Outline steps to review what went wrong (post-mortem), communicate insights to stakeholders, and ensure that the failure becomes a learning opportunity rather than causing loss of trust in analytics.
Change Management Plan – Draft a brief change management plan for introducing a new AI-driven decision support tool to a sales team. What are the key components you would include (training, communication, feedback channels, pilot phase, etc.) to encourage adoption? How would you address possible resistance from veteran sales reps who are skeptical about relying on a tool?
Data Governance in Action – Imagine your company is rolling out a self-service analytics platform to enable different departments to run their own analyses. What governance measures would you put in place to balance empowerment with control? Consider aspects like data access permissions, data dictionary documentation, quality checks on user-generated reports, and support from a central data team.
Adaptive Analytics Strategy – The business environment can change rapidly (e.g., sudden market disruptions or new regulations). How should a company’s data science strategy adapt to unforeseen changes? Discuss how you would re-prioritize projects or shift resources in response to a major change (such as COVID-19 impacting consumer behavior), and how to keep the analytics team agile and responsive to new questions that arise.
Scaling Beyond Company Walls – Explore the idea of extending data science initiatives through partnerships or open innovation. How might collaborating with external data partners, vendors, or even participating in open data competitions benefit a company’s analytics scaling? Propose one collaborative initiative (for example, a data sharing consortium in your industry, or a Kaggle competition to solve a problem) and explain how it could accelerate your organization’s data science maturity.
The Next Frontier – Looking ahead, what emerging technology or trend do you think will significantly influence how companies scale data science in the next 5–10 years? This could be anything from federated learning, to automated machine learning (AutoML), to new privacy-preserving techniques or organizational innovations. Describe the trend and speculate on how businesses might need to adjust their strategies to harness it. For instance, how would the rise of no-code AI platforms affect talent needs and workflow? What about the impact of stricter data privacy laws on cross-border analytics? Challenge yourself to envision the future state of enterprise data science and how leaders can prepare for it.
Embarking on these explorations will deepen your understanding and reveal new angles on scaling data science effectively. Keep pushing boundaries – the more you question and investigate, the better equipped you’ll be to lead successful, sustainable analytics programs. Remember that real-world application often presents complexities beyond theory, so grappling with these prompts will hone your ability to adapt principles to practice. Stay curious and keep learning; the field of data science is ever-evolving, and each challenge you tackle will refine your expertise and strategic thinking. Your commitment to continual growth is what will ultimately empower you to turn data science into a lasting engine of innovation and value in your organization. Happy exploring!
To bridge theory and practice, the following assignments present realistic scenarios that call for strategic planning and decision-making. These exercises are crafted to help you apply the chapter’s concepts in a tangible way. By working through these strategy-based assignments, you will translate knowledge into actionable plans, sharpening the skills needed to lead data science initiatives in an organizational setting. Each assignment has a clear objective and provides guidance to steer your thought process. We encourage you to treat these as simulations of actual business situations: develop your solutions as if you were truly responsible for the outcomes. This hands-on approach will reinforce your learning, highlight areas for improvement, and build confidence in your ability to drive data-driven transformation. As you complete the assignments, focus on the reasoning behind your strategies and the communication of your plans – both are crucial in executive settings. Use the guidance as a starting point, but feel free to inject your creativity and professional insight. The ultimate purpose is to refine and apply your skills so that you are better prepared to champion scaled and sustainable data science efforts in the real world.
🛠️ Assignments
📝 Assignment 1: Crafting a Data Science Strategic Roadmap
🌐 Scenario:
You have just been hired as the Chief Data Officer of a mid-sized retail company that has done ad-hoc analytics projects but lacks a coherent strategy. Leadership is eager to become “data-driven” but is unsure where to focus or how to proceed. They have tasked you with developing a 3-year data science strategic roadmap aligned with business goals.
🎯 Objective:
Create a comprehensive data science strategy document that aligns analytics initiatives with the company’s business objectives and outlines a phased plan for scaling up capabilities. The strategy should cover vision and goals, key use cases to pursue, required data and technology investments, team and talent needs, and an implementation timeline. It must also gain executive buy-in by clearly linking to business value.
💡 Guidance:
Begin by reviewing the company’s overall business strategy (e.g. is the focus on improving customer experience, optimizing supply chain, growing e-commerce, etc.). Identify 3–5 high-impact analytics use cases that directly support these strategic priorities (for instance, customer segmentation for personalized marketing if growth is a goal, or demand forecasting if efficiency is a goal). For each use case, outline the value proposition and how it would work in practice. Next, assess the current state of the company’s data infrastructure and analytics capabilities – what gaps need addressing (data quality, tools, skills)? Your roadmap should include foundational projects in Year 1 (such as consolidating customer data into a data warehouse, or hiring key staff like data engineers) before tackling more advanced analytics in Years 2–3. Clearly delineate milestones for each phase: e.g. Phase 1: build data platform and pilot one use case; Phase 2: expand to multiple use cases, introduce advanced techniques; Phase 3: scale across the enterprise with a governance framework. As you formulate the plan, incorporate a change management component – how will you drive adoption and culture change? Perhaps propose a data literacy program or the formation of a cross-department analytics champions team. Finally, prepare an executive summary that quantifies expected benefits (e.g. “by Year 3, data science initiatives should contribute an estimated 5% increase in revenue and 10% reduction in costs”) to secure buy-in. This assignment will refine your ability to connect analytics possibilities with concrete business planning, a crucial skill for any data science leader.
📝 Assignment 2: Designing an Organizational Structure for Scaled Analytics
🌐 Scenario:
A global financial services firm has pockets of data scientists scattered across IT, marketing, and risk departments, working independently. The CEO feels the company isn’t reaping the full benefits of these talented individuals due to lack of coordination. You are brought in as a consultant to recommend an optimal organizational structure and operating model for the firm’s data science function as it scales up.
🎯 Objective:
Develop a proposal for a data science organizational model that balances central governance with business unit relevance. Your proposal should define where the data science team(s) sit in the org chart, how they interact with business units and IT, and what governance mechanisms will ensure efficiency and consistency. The goal is to enable enterprise-scale analytics with both strategic alignment and agility.
💡 Guidance:
Start by considering the trade-offs of different models: a centralized model (all data scientists in one department serving the whole company), decentralized/embedded model (data scientists housed within each business unit), or a hybrid model (central hub plus embedded liaisons in units). For a large firm with diverse functions like this one, a hybrid “hub-and-spoke” is often effective. Outline your recommended structure in detail. For example: A central Analytics Center of Excellence under the Chief Data Officer that handles common infrastructure (data lakes, AI platforms), research, and governance standards. Then, smaller analytics teams or “spokes” embedded in key divisions (marketing, risk, operations) that work on business-specific projects and report dotted-line to the CDO. Explain how this model will work day-to-day – perhaps the central team provides data pipelines, tools, and mentoring, while embedded analysts ensure solutions meet local needs and drive adoption. Specify the roles needed: e.g. a Head of Analytics (CDO or equivalent) to lead the hub, data engineers and data scientists in the hub, plus “analytics translators” or product managers interfacing with business units. Include governance committees or routines, such as a weekly sync between central and embedded teams to prioritize projects, and a review board to evaluate model performance and compliance. Address how this structure will prevent silos (through rotation programs or communities of practice) and how it will scale (maybe starting with a central team of X people and adding unit specialists over time). By completing this assignment, you practice structuring a data science function for maximal impact – a key strategic skill as analytics organizations grow.
📝 Assignment 3: Enhancing Data Infrastructure and Governance
🌐 Scenario:
An insurance company has struggled with messy, siloed data and lengthy model deployment cycles. Data scientists spend more time wrangling data than building models, and when models are built, IT bottlenecks delay deployment. The CIO has requested a plan to modernize the company’s data infrastructure and governance to better support scalable data science and AI. You are leading the task force to propose improvements.
🎯 Objective:
Develop an action plan to upgrade data infrastructure and governance practices over the next 18 months. The plan should aim to ensure data scientists have quick access to clean, integrated data and a smooth pathway to deploy models into production. Key areas to address include data architecture (warehouses, lakes), data pipelines/ETL, data quality management, tooling for model deployment (MLOps), and governance policies for data usage.
💡 Guidance:
First, gather information on the current state: perhaps the company has multiple legacy databases (claims data in one system, customer info in another), with inconsistent definitions and access controls. Outline the target state of the infrastructure – for example, implementing a centralized cloud data lake/warehouse that consolidates all key data sources (policies, claims, customer interactions) into a unified platform. Recommend technologies or architectures suited for the company’s size (maybe a modern cloud provider, distributed file system, or data virtualization layer). Next, address data pipeline and quality issues: propose establishing an automated ETL pipeline that routinely cleans and updates data for analytics, and a data quality monitoring process (with data stewards accountable for critical data fields). For model deployment, you might suggest adopting an MLOps framework: containerize models, use a model registry, and set up CI/CD so that validated models can be deployed by IT in weeks, not months. Governance should be woven throughout: e.g. implement role-based data access so data scientists can easily get the data they need from the lake with proper security; create data governance guidelines to maintain metadata and lineage tracking for all data sources. Present your plan as a sequence of initiatives: Phase 1: design data architecture and migrate data, Phase 2: implement MLOps platform and retraining pipelines, Phase 3: enforce governance and optimize processes. Include quick wins like provisioning sandbox environments for data scientists or using a data profiling tool to immediately identify data errors – this shows value early while big infrastructure pieces are being built. This assignment will strengthen your ability to link technical improvements with strategic outcomes (faster insights, reliable data), and to communicate a clear plan bridging IT and analytics needs.
📝 Assignment 4: Driving Adoption and Cultural Change
🌐 Scenario:
A pharmaceutical company introduced a powerful analytics dashboard for its R&D and marketing teams, but six months in, usage is disappointingly low. Many employees stick to their old habits (spreadsheets, intuition) and are hesitant to rely on the new data insights. The Chief Analytics Officer has asked you to formulate a strategy to increase adoption and foster a data-driven culture in the organization, ensuring that the investment in analytics tools pays off.
🎯 Objective:
Create a change management and adoption plan aimed at significantly boosting the use of data/analytics in decision-making across the company. The plan should identify root causes of low adoption and detail interventions to address them – from training and communication to incentive realignment and leadership actions. The ultimate objective is to turn the initial skepticism into enthusiasm, embedding the new analytics dashboard (and data-driven methods generally) into everyday workflows.
💡 Guidance:
Start by diagnosing why employees might be avoiding the new tool. Is it a lack of awareness or understanding of the dashboard’s features? Does it provide insights that users don’t trust or know how to interpret? Are people afraid analytics might replace their jobs or expose mistakes? List these potential barriers candidly. Now design a multi-pronged change program to tackle each barrier. For example: Education and Training – Organize hands-on workshops and “lunch and learn” sessions for each department, showing practical use cases of the dashboard with the team’s own data. Perhaps implement a “Analytics Buddy” system pairing less experienced users with data team members for support. Communication and Storytelling – Launch an internal communication campaign highlighting success stories where analytics made a positive difference (e.g. a project that succeeded faster due to insights from the dashboard). Hearing peers talk about wins can build credibility. Leadership and Incentives – Ensure senior managers visibly use and endorse the dashboard. They could start meetings by reviewing key dashboard metrics, signaling its importance. Adjust KPIs if needed: for instance, make “data-driven decision rate” a metric, or include effective use of data in performance reviews. User Feedback Loop – Set up channels for users to give feedback on the tool (maybe a monthly user forum or an in-app feedback button), and act on suggestions to improve usability or relevance of the insights. People are more likely to engage if they feel their input shapes the tool. Recognition and Gamification – You might introduce friendly competitions or rewards, such as acknowledging the team that most increased their data usage or a badge system for power users of the dashboard. Lay out a timeline for these activities, showing a concerted effort over the next year. Emphasize measurement: define what success looks like (e.g. dashboard usage statistics doubling, survey results indicating higher trust in data) and how you will track progress. By completing this assignment, you practice the “soft” yet critical skills of change leadership – persuading and enabling people to embrace new ways of working through data.
📝 Assignment 5: Demonstrating ROI and Business Impact
🌐 Scenario:
The analytics team at an e-commerce company has developed several machine learning models (for pricing, customer churn prediction, and personalization), but senior executives remain unconvinced of their value. In quarterly meetings, the question “How is data science contributing to our bottom line?” keeps coming up. You have been asked to create a clear ROI analysis and communication plan to demonstrate the impact of these data science initiatives and to guide future investment decisions.
🎯 Objective:
Develop a framework for measuring and reporting the ROI of the company’s key data science projects, and apply it to produce a compelling analysis for one project of your choice (pricing, churn, or personalization). Additionally, outline how you would communicate these results and insights to an executive audience in order to secure ongoing support. The aim is to validate the business value generated by data science and provide learnings to improve that value over time.
💡 Guidance:
Start by defining what ROI means for data science in this context. It could be purely financial (increase in profit, revenue uplift, cost savings) or include strategic value (improved customer satisfaction, market share growth, risk reduction). Choose one project, say the customer churn prediction model, and list all the ways it creates value. For example: by identifying at-risk customers and enabling targeted retention offers, it might reduce monthly churn from X% to Y%, which translates into $Z in retained revenue over a year. Gather the needed data – perhaps marketing can provide how many customers were saved via outreach and their average spend. Calculate the benefit (retained revenue or customer lifetime value saved) and then compute the costs of the project (team salaries portion, infrastructure, any software). With these, estimate an ROI percentage or payback period. If some benefits are qualitative (like “better customer experience”), think of proxy metrics or quote testimonials from sales reps about improved conversations with clients thanks to the insights. Now structure a simple ROI framework that can be reused: e.g. for each project, track metrics A, B, C before and after model implementation, attribute changes to the model (with a control group if possible), and compute net value minus cost. After doing the analysis for churn (or your chosen case), prepare an executive-friendly summary. This could be a one-page report or slide that states: “Data Science ROI Highlight: Our churn model drove an estimated $5M in retained revenue last quarter, a 10x return on investment. Churn rate dropped from 5% to 4.5% in the targeted segment, directly attributable to model-driven interventions【analysis evidence】. Beyond financials, this translates to 1,000 customers kept, strengthening our brand loyalty.” Explain the assumptions behind the numbers in simple terms and note any improvements planned (maybe next quarter you’ll refine the model to capture even more). Outline how you will report this regularly – perhaps integrating it into the company’s KPI dashboard or doing a quarterly “analytics impact review” presentation. By working on this assignment, you’ll enhance your ability to quantify and communicate the value of data science – arguably one of the most important skills for sustaining executive support and funding for analytics programs.
By engaging with these assignments, you embark on a robust journey through data science in an FMCG setting—tackling marketing dashboards, forecasting complexities, consumer analytics, and supply chain puzzles while never losing sight of ethical responsibilities. Each project offers a stepping stone toward mastering the art and science of turning raw data into actionable insights that resonate with both internal decision-makers and the broader consumer audience.
Comments