Chapter 4
Data as a Strategic Asset – Sources, Quality, and Governance
"Data is a strategic asset that can be used to make more informed decisions, drive innovation, and create competitive advantage." — Derek Strauss
Data has emerged as a critical strategic asset for modern businesses, comparable in importance to financial and physical capital. This chapter explores how organizations can harness data for competitive advantage by focusing on three core areas: data sources, data quality, and data governance. We outline the fundamental concepts of treating data as an asset, illustrate the vast array of data sources now available in industries like finance, retail, healthcare, FMCG, distribution, and logistic, and emphasize the importance of maintaining high data quality. We then discuss robust data governance frameworks to ensure data is managed, protected, and used responsibly. Throughout, real-world examples and case studies demonstrate how industry leaders leverage data to drive innovation, improve decision-making, and achieve operational excellence. The insights provided are conceptual and strategic, intended for executives with minimal technical background, yet they highlight practical steps and industry-specific scenarios that show how data can fuel growth and efficiency when properly sourced, refined, and governed.
4.1. Understanding Data as a Strategic Asset
Data has steadily moved from being an operational byproduct—some necessary clutter stored on servers—into a bona fide strategic asset that can drive measurable, sustained growth. Leading organizations recognize that properly managed data does more than streamline processes; it opens new avenues for innovation, efficiency, and competitive advantage (Deloitte US). In essence, data gains value when businesses harness it to improve customer experiences, reduce operational risks, and develop entirely new products or services. Yet, merely hoarding volumes of information is not enough. As countless executives have discovered, building data lakes without a clear strategic framework often results in a swamp of unstructured information that no one can leverage effectively.
It is easy to overlook data’s true potential when daily reports and dashboards become routine. However, those organizations that treat data as a strategic resource, on par with financial or human capital, typically uncover hidden efficiencies and revenue streams. According to one analysis, data-driven decision-making can boost productivity and output by 5–6%, which naturally translates into higher profitability (Brynjolfsson et al.). This is not just academic hype. Financial institutions are using advanced analytics to recalibrate credit risk assessments in real time, while retailers optimize their product mix and pricing strategies across thousands of SKUs daily. The direct connection between data-informed decisions and performance gains underscores why executives who champion data-centric thinking frequently see their firms outpace less analytics-savvy rivals.
Companies systematically leveraging data tend to achieve a measurable edge in market value and performance, often overshadowing competitors that rely on gut instinct. This advantage emerges because data-driven enterprises can react to market shifts faster, spot emerging consumer trends earlier, and orchestrate internal processes more efficiently. Such capabilities extend across industries. In finance, algorithmic trading and real-time fraud detection stand as prime examples of data’s immediate impact on the bottom line. In the consumer goods sector, advanced demand forecasting and supply chain optimization ensure the right products appear on shelves at precisely the right moment. Healthcare organizations harness machine learning to detect patterns in patient data, improving outcomes and operational efficiency, while logistics firms use predictive models to optimize routes, saving millions in fuel and labor costs (Deloitte US; DigitalDefynd, 2025). The unifying thread across these diverse domains is a recognition that well-managed data ignites strategic transformation, creating possibilities that once seemed out of reach.
Although data rarely shows up as a line item on corporate balance sheets, its long-term value rivals that of tangible resources like manufacturing plants or vehicles. In fact, many of today’s market disruptors—think technology giants or forward-thinking startups—derive a substantial portion of their enterprise value from proprietary data assets and analytics capabilities. These intangible assets feed innovation pipelines by helping companies anticipate consumer demands, tailor product features, or identify promising new markets (Deloitte US). Consequently, executives are allocating greater budget to data initiatives: modernizing infrastructure, deploying data lakes, and elevating roles such as Chief Data Officer to the executive table. Like any other strategic investment, developing data assets requires diligent stewardship, from security protocols and data governance to consistent quality checks and alignment with broader corporate goals.
The true power of data only materializes when a data-driven mindset infiltrates the organization at every level. This shift begins with leadership. When C-level executives or board members champion fact-based decision-making, employees across departments are more inclined to trust analytics over “we’ve always done it this way.” Companies like Amazon and Netflix attribute much of their rapid growth and disruptive strategies to a culture where data underpins practically every business decision, from UX design to new product launches. By contrast, organizations that keep data siloed or fail to maintain data quality can miss lucrative opportunities, make flawed decisions, or lag behind more nimble competitors (Deloitte US). Many businesses now invest heavily in data literacy programs, training employees to understand and interpret analytics, and ultimately embedding data into the daily workflow. This cultural evolution—often heralded as a hallmark of “digital transformation”—moves data from being a buzzword to a driving force behind strategic planning, innovation, and execution.
Treating data as a strategic asset also means understanding the broader lifecycle that fuels its value creation. Data collection, once a passive exercise, now requires deliberate planning to capture the right information at the right touchpoints—be it through IoT sensors, transactional logs, or CRM platforms. The cleaning and preprocessing phase, often dismissed as mundane, is arguably where most data scientists invest the bulk of their time, ensuring consistent formats, accurate records, and actionable metrics. Exploratory analysis then reveals patterns or anomalies, guiding the subsequent model-building phase, which can range from straightforward regression models to advanced deep learning architectures. Once built, these models demand thorough evaluation against key business metrics before they are deployed and integrated into operational workflows. Finally, maintenance processes, including ongoing retraining and monitoring, help sustain performance over time. Ignoring any one of these stages can stifle data’s potential, proving that a holistic approach is mandatory if data is to truly function as a strategic engine.
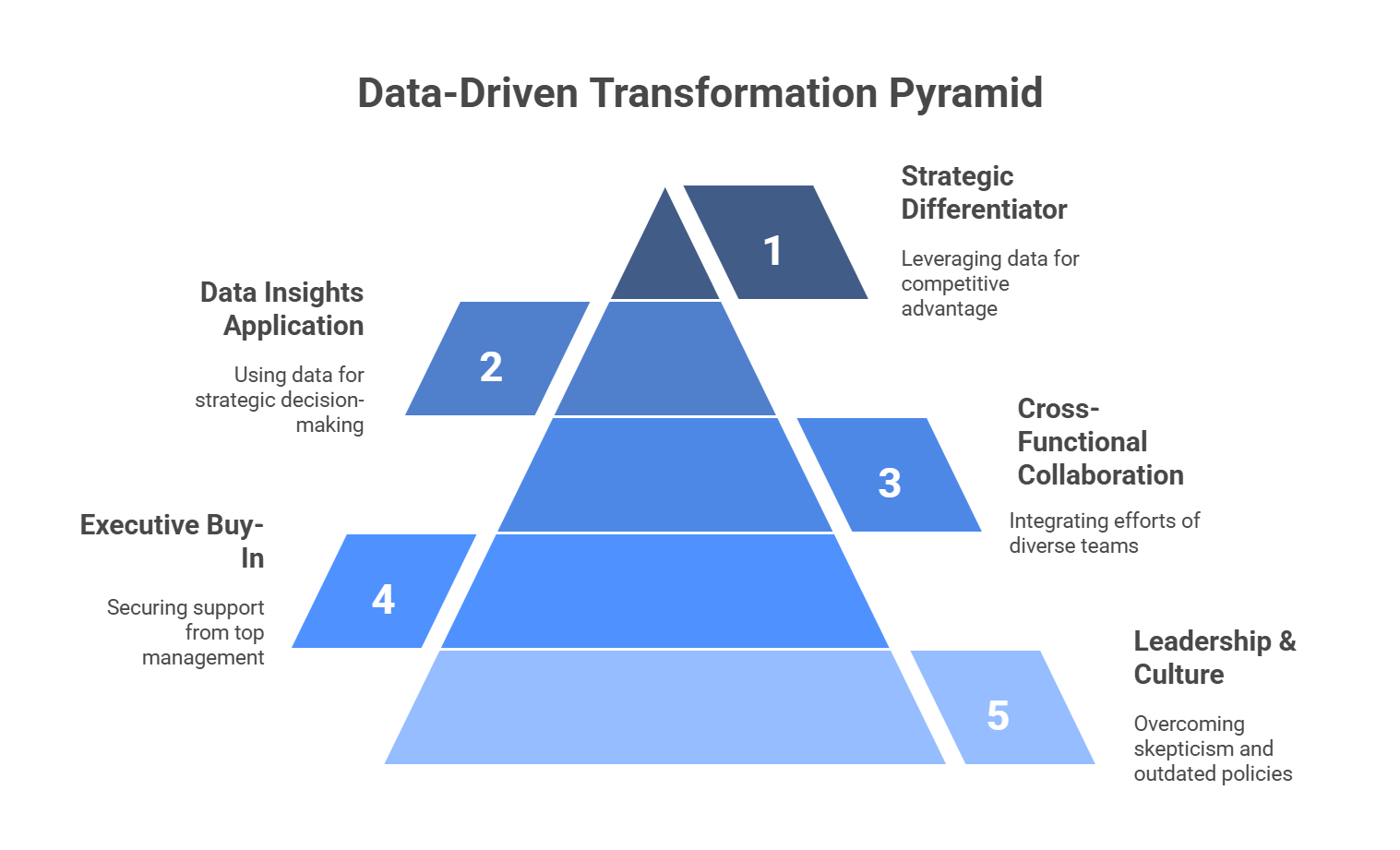
Figure 1: Illustration of the progressive steps needed for organizations to effectively utilize data, starting with leadership and culture, and culminating in leveraging data for competitive advantage.
No discussion of data as a strategic asset is complete without touching on the leadership and cultural factors that influence success. Chief Data Officers, for instance, often come into organizations where siloed data systems, outdated policies, or entrenched skepticism hamper progress. Getting executive buy-in, aligning data investments with commercial objectives, and establishing cross-functional collaboration between data scientists, IT, and domain experts is essential. The payoff can be significant: as data insights begin to inform everything from marketing campaigns to inventory management, skeptics see the tangible impact and gradually join the bandwagon. Over time, the organization matures into a data-driven juggernaut, capable of extracting deeper insights faster and using them to adapt quickly to market shifts or consumer demands. In this manner, data transforms from a nebulous resource into a clear strategic differentiator that consistently drives value.
In an increasingly complex and digitized economy, data has graduated from an afterthought to a primary source of competitive advantage. Firms that consciously invest in data collection, analytics infrastructure, and—crucially—a supportive culture set themselves up for sustained success. They discover operational efficiencies that boost margins, deliver hyper-personalized experiences that delight customers, and unearth new revenue streams ahead of the curve. Meanwhile, their less data-savvy peers risk sliding into reactive mindsets, missing out on growth opportunities, and grappling with higher costs. As executives weigh strategic priorities, few decisions carry more potential upside—or more potential pitfalls—than how they treat data. Handled prudently and aligned with the organization’s larger objectives, data becomes an invaluable asset with compounding returns, helping shape the future of industries and redefining how business is done.
4.2. Diverse Data Sources in Modern Business
Modern enterprises are awash in data from an ever-expanding array of sources, ranging from social media chatter to sensor readings collected by Internet of Things (IoT) devices. According to some estimates, global data generation could reach hundreds of exabytes per day by the middle of this decade (IDC, 2018). While this influx may look like a miracle to data-hungry analysts, it can also become a logistical nightmare when poorly managed. Businesses now routinely collect not only structured data, such as customer transactions in relational databases, but also unstructured information in the form of videos, social posts, images, and text. Savvy organizations realize that unifying these disparate data streams provides a more holistic view of their operations and customer behaviors. However, the road to harnessing that data is fraught with pitfalls: incomplete metadata, siloed data lakes, and real-time velocity demands all complicate the effort. Those that succeed in taming this deluge discover new revenue possibilities, heightened efficiency, and more personalized customer engagement.
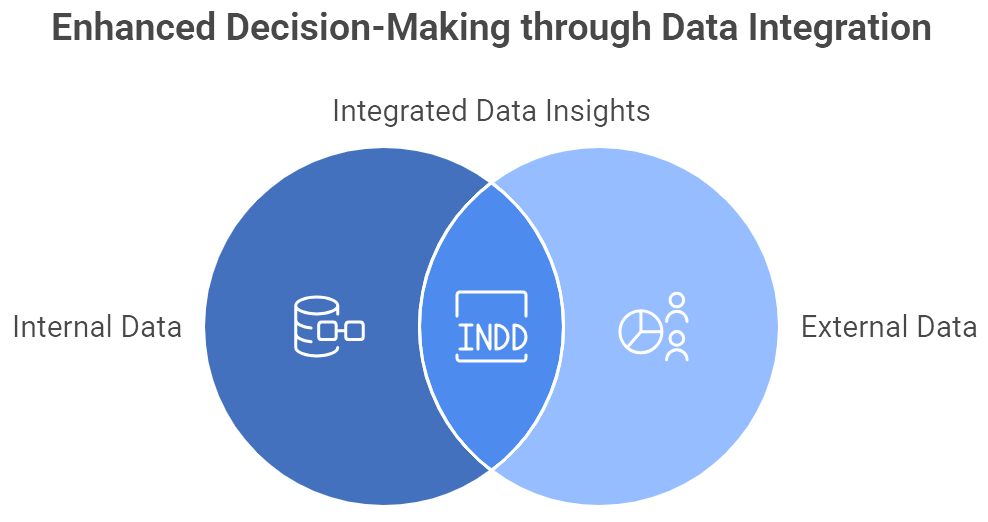
Figure 2: Illustration of how integrating internal and external data sources creates a comprehensive foundation for robust analytics-driven decision-making. (Image by Napkin).
Enterprises frequently divide their data ecosystem into two broad categories: internal and external. Internal data originates within the organization—transaction logs, CRM records, production outputs, and supply chain details, for example. These sources often represent the “low-hanging fruit” of analytics, given that teams theoretically have direct control over data formats and governance. Yet, obstacles like legacy IT systems or departmental silos can still block the creation of a unified data view. External data, on the other hand, comes from beyond the company’s walls. Market research reports, social sentiment analysis, publicly available economic indicators, and third-party demographic data can all complement internal sources, enriching models and unlocking insights that a single data set cannot reveal on its own. A retailer that merges its in-store POS information with real-time social media trends might uncover nuanced shifts in consumer sentiment, while a bank layering external credit bureau feeds onto customer transaction histories can pinpoint emerging fraud patterns before they escalate into major losses. Combining internal and external data requires careful integration strategies, as well as robust cleaning and validation processes to ensure consistency. When executed effectively, however, this synthesis leads to a broader, richer foundation for analytics-driven decision-making.
Financial institutions live and die by data. An ordinary day might include millions of credit card swipes, countless stock trades, and streams of ever-changing interest rates or exchange quotes. Core data repositories typically hold detailed transaction records and customer account profiles, allowing banks, brokerage firms, or insurers to track revenues, analyze portfolio risks, or launch targeted cross-selling campaigns. Increasingly, these organizations also mine alternative data like website clicks, app usage patterns, and geolocation signals to drive personalized product recommendations. On top of that, many firms ingest macroeconomic data—unemployment rates, GDP trends, commodity prices—to enrich forecasting models for risk management and asset allocation. Where the data deluge truly becomes interesting is in real-time analytics for fraud detection, high-frequency trading, and instant credit approvals. Advanced machine learning algorithms monitor incoming data streams to catch anomalies within milliseconds, flagging suspicious credit card transactions or trades before they turn into financial disasters. Building such a system entails more than coding savvy; it requires sophisticated data engineering pipelines, bulletproof governance to handle regulatory constraints, and close collaboration between data scientists, compliance officers, and operational teams (Brynjolfsson et al.).
Retailers and Fast-Moving Consumer Goods (FMCG) companies have long understood that data about purchasing habits forms the backbone of strategic decision-making. From point-of-sale scanners that log every product bought and price paid, to loyalty programs that reveal a shopper’s long-term preferences, these data sources can feel endless. E-commerce operations extend the complexity further by capturing clickstream data, abandoned cart behavior, and time spent on product pages. All of that internal information is enriched by third-party market research, social media sentiment, and even weather data (since a sudden heatwave can trigger spikes in sales of beverages or air conditioners). The logistical side is equally critical: sensors, RFID tags, and warehouse scans track the movement of goods from production to store shelves, generating more data in a single day than many legacy systems can comfortably process. Leaders such as Walmart famously leverage real-time data to optimize inventory, minimize stockouts, and tailor product assortments per location, boosting both revenue and customer loyalty (Deloitte US). To support these efforts, businesses must invest heavily in analytics infrastructure, data cleaning, and staff training, ensuring that insights gleaned from these myriad sources are accurate, timely, and actionable.
Healthcare stands as one of the most data-intensive industries, yet historically much of its information languished in isolated paper files or incompatible systems. The shift toward electronic health records (EHRs) has already democratized some clinical data, providing hospitals and clinics with easier ways to exchange patient information. Beyond EHRs, however, lies a new frontier of IoT-enabled health devices—from wearable fitness trackers and smart glucometers to remote patient monitoring sensors. By linking these continuous data feeds with clinical records, healthcare providers can detect early warning signs of patient deterioration, reduce hospital readmissions, and even support personalized treatment plans based on genomic data. Additionally, large public health databases offer aggregated population insights that help planners anticipate outbreaks or allocate resources more effectively. While these opportunities sound thrilling, achieving them entails methodical data integration and scrupulous attention to privacy regulations like HIPAA. Institutions that manage these complexities responsibly can dramatically enhance patient outcomes and operational efficiency, making a compelling case for data science as a catalyst for healthcare transformation (Deloitte US).
In distribution and logistics, data has become the difference between on-time delivery and an unhappy customer tweeting about a late package. Fleet operators rely on real-time GPS data, telematics, and route optimization software to coordinate massive delivery networks. Warehouse operations harness RFID tags, barcode systems, and advanced scanning technologies to monitor inventory movements and detect bottlenecks. Meanwhile, external data streams—ranging from local traffic patterns to weather forecasts—help logistics managers dynamically adjust routes and schedules. The complexity spikes even higher when these firms must handle cross-border shipments, relying on customs databases and port authority updates for smooth clearance. For industries like manufacturing or heavy machinery, IoT sensors built into equipment relay performance metrics, enabling predictive maintenance and minimal downtime. By preventing breakdowns, firms reduce operational hiccups and keep customers satisfied. Achieving this level of synchronization demands robust data governance and real-time analytics architectures that can turn incoming feeds into actionable insights, often within seconds. Those that pull it off gain a distinct competitive edge, slashing fuel costs, reducing delivery times, and earning a reputation for reliability.
While the benefits of diverse data sets are alluring, combining them presents formidable challenges that cannot be shrugged off. Merging high-velocity sensor data with slower-paced, unstructured consumer feedback requires thoughtful architecture—data lakes, warehouses, or event-driven systems capable of standardizing formats on the fly. Even seemingly trivial details, such as consistent date-time stamps across different data feeds, can become major stumbling blocks when neglected. Meanwhile, incomplete or contradictory records can throw off machine learning models, leading to poor recommendations or flawed forecasting. Many organizations have discovered that a well-defined data governance strategy, complete with data catalogs, lineage tracking, and clear accountability for data owners, is crucial for taming this chaos (Deloitte US). Without it, analytics initiatives devolve into guesswork, with teams second-guessing data quality at every turn. Successful enterprises, by contrast, embed data integration best practices into their workflow, ensuring that insights flow seamlessly across departments—from marketing to finance to supply chain management—and underpin everyday decisions rather than languishing in isolated silos.
A final but critical point is that amassing diverse data sets means little if they do not align with the company’s strategic objectives. An organization that invests heavily in social media sentiment analysis, for instance, yet struggles to tie those insights to product development or customer service improvements, may wind up with an expensive hobby rather than a game-changing asset. Data collection strategies should be guided by clear questions: which market indicators might predict a sales surge, which variables most influence a customer’s likelihood to churn, or how real-time sensor data can reduce operational bottlenecks. By anchoring data efforts to genuine business use cases, companies ensure that the integration of multiple sources yields measurable impact. The key is a relentless focus on outcomes, accompanied by a cross-functional approach: data scientists partner with domain experts, IT builds robust pipelines, and executives champion analytics-driven pilots. The result is a virtuous cycle, where each new data source magnifies the value of existing ones, reinforcing the overall strategy and powering the organization’s evolution into a truly data-driven enterprise. If additional references are required to delve into advanced data integration techniques—such as real-time streaming platforms or specialized data virtualization solutions—they would fit naturally within this discussion, offering deeper technical insights to support a commercial audience hungry for both the “what” and the “how” of leveraging diverse data sources.
4.3. Ensuring Data Quality and Integrity
Treating data as a strategic asset is only effective if the underlying information is trustworthy and accurate. When data is riddled with errors, inconsistencies, or omissions, even the most sophisticated analytics and models can produce faulty insights, leading to misguided strategies and financial losses. According to IBM, poor data quality costs U.S. businesses about $3.1 trillion annually in inefficiencies and failures, a figure that underscores how quickly small inaccuracies can balloon into large-scale issues (IBM). Another study by Gartner found that organizations lose an average of $12.9 million per year due to bad data, further highlighting the substantial financial repercussions (Gartner). By contrast, high-quality data inspires confidence in analytics outputs and fosters a culture where employees trust the insights that come from data-driven initiatives, paving the way for more informed and strategic decision-making.
The old computing adage “garbage in, garbage out” remains as relevant as ever in the context of data science. If a logistics provider’s shipment records are full of discrepancies or not updated in a timely manner, even the most advanced route optimization models will propose suboptimal plans. Retailers that rely on flawed customer databases—featuring duplicate or incorrect entries—risk sending promotions to the wrong people or missing potentially lucrative market segments altogether. In finance, inaccurate risk data can mislead bank executives about the institution’s exposure, potentially triggering regulatory scrutiny
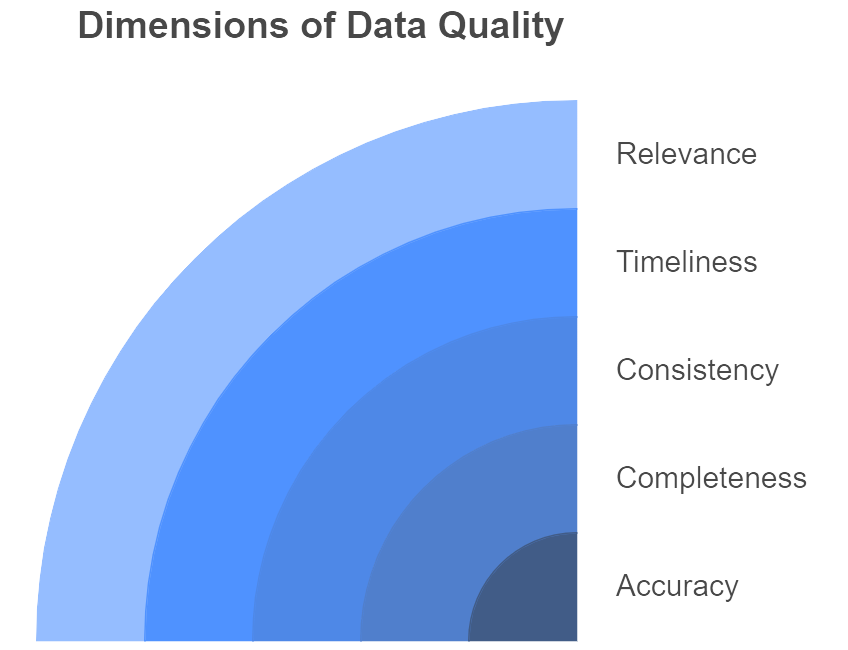
Figure 3: Illustration of data quality into its fundamental components, showcasing how each dimension contributes to reliable and trustworthy data. (Image by Napkin).
or penalties. Investing in data quality at the front end is invariably cheaper than scrambling to fix problems after flawed decisions have already been made. For instance, a healthcare provider with inconsistent patient records not only faces administrative headaches but could also compromise patient safety if outdated information is used in a critical diagnosis.
Data quality encompasses multiple dimensions that organizations can measure and improve. Accuracy is paramount: data should faithfully represent the real-world entity or event it describes, whether that is a customer’s address or the timestamp of a sensor reading. Completeness ensures all necessary information is captured so that decisions are not made on partial views. Consistency requires that data remains uniform and coherent across different systems, so a product ID or customer ID references the same entity in every database. Timeliness (or currency) denotes that the data is up-to-date and accessible when needed, a crucial factor for real-time analytics scenarios. Relevance adds another layer, focusing on whether the data is actually pertinent to the business question at hand. By breaking data quality into these dimensions, companies can methodically pinpoint the root causes of errors—whether they stem from faulty input forms, missing data fields, or mismatched naming conventions. In industries like finance, the emphasis often rests on consistency and accuracy due to strict regulatory requirements. In consumer-facing sectors, timeliness may be equally critical, as missing a short-lived trend can mean losing ground to competitors.
The dangers of low-quality data are not hypothetical. In healthcare, flawed records can contribute to incorrect diagnoses or medication errors, resulting in serious patient harm. In 2022, a data integration error at Unity Technologies led to an overestimation of revenue by $110 million, causing the company’s stock to plummet by 37% (Unity Technologies, 2022; Gartner). Such incidents demonstrate that poor data management is not a mere technicality but a strategic business risk with the potential to erode shareholder value and corporate reputation. Meanwhile, distribution and logistics firms often grapple with mismatched inventory data, culminating in costly overstocking in one warehouse and shortages in another. Financial institutions have suffered multimillion-dollar losses from spreadsheet errors and duplications—catastrophic events that reinforce how essential it is for data quality to be monitored and maintained diligently.
Recognizing these risks, many organizations are adopting structured data quality management practices. Automated data cleansing tools help identify and correct errors, such as malformed entries or inconsistent formatting. Validation rules at the point of entry—e.g., in customer signup forms or supply chain input systems—ensure that data problems are caught before they proliferate. Master data management (MDM) solutions take this a step further by creating a unified record of key entities—such as products, customers, or suppliers—across the enterprise. For instance, a retailer might integrate all sales channels (stores, e-commerce, mobile) into one standardized system so that product identifiers, descriptions, and prices are always in sync. Data profiling and quality auditing tools can operate on a continuous basis, flagging anomalies like sudden spikes in missing fields or uncharacteristic outliers in a time series. Instead of reacting to data crises after the fact, companies can adopt an ongoing, proactive stance that embeds quality into data collection and maintenance processes.
Maintaining data integrity is not just a function of the IT department. It involves a blend of technical oversight and organizational responsibility. Data Stewards or Data Quality Analysts within different business units often serve as frontline guardians, monitoring incoming data, coordinating cleanup efforts, and establishing quality thresholds. At the enterprise level, a Chief Data Officer (CDO) may lead broader data quality initiatives, setting formal policies and metrics that define acceptable quality standards. These efforts are increasingly important in regulated industries like finance and healthcare, where regulators require robust data governance. For instance, banks must adhere to BCBS 239 principles from the Basel Committee, which mandate timeliness and accuracy in risk data aggregation (Basel Committee). Proper governance structures also clarify who “owns” each dataset and who is accountable when issues arise. By distributing responsibilities and aligning incentives around high-quality data, companies transform data quality from a technical concern into a shared strategic priority.
Data quality is less a one-time project than an evolving process that demands ongoing vigilance. Many organizations adopt feedback loops in which data consumers—such as analysts, product managers, or data scientists—report anomalies or gaps to the teams that produce or manage the data. If an abnormal spike in missing values appears after a new customer intake process is launched, root-cause analysis might reveal that a mandatory field on the web form was never actually enforced. These lessons then shape process improvements, from refining user interfaces to retraining staff on data entry procedures. Some companies even quantify the cost of poor data quality internally, using the results to justify investments in better tools and training. Over time, as data quality metrics improve, employees grow more confident in analytics outputs, and the enterprise as a whole becomes more agile, innovative, and competitive. Ultimately, robust data quality management paves the way for the advanced analytics that executives crave—machine learning, AI-driven recommendation engines, and real-time decision support—by ensuring these models have reliable information on which to run.
4.4. Data Governance, Security, and Compliance
Data governance is the discipline that clarifies who owns data, how it is used, and under what conditions it can be shared or modified (Data Governance, 2024). Although it might sound like a bureaucratic checkbox, effective governance is what transforms “data as an asset” from a catchy slogan into tangible business practice. In much the same way financial governance enforces checks and balances for corporate spending, data governance stipulates policies, procedures, and accountability for information usage. When done right, it ensures data flows securely across the organization, staying accurate, accessible, and properly protected at every step. For data science leaders and C-suite executives, this translates into higher-quality insights, fewer compliance nightmares, and a culture where analytics can flourish without straying into risky territory.
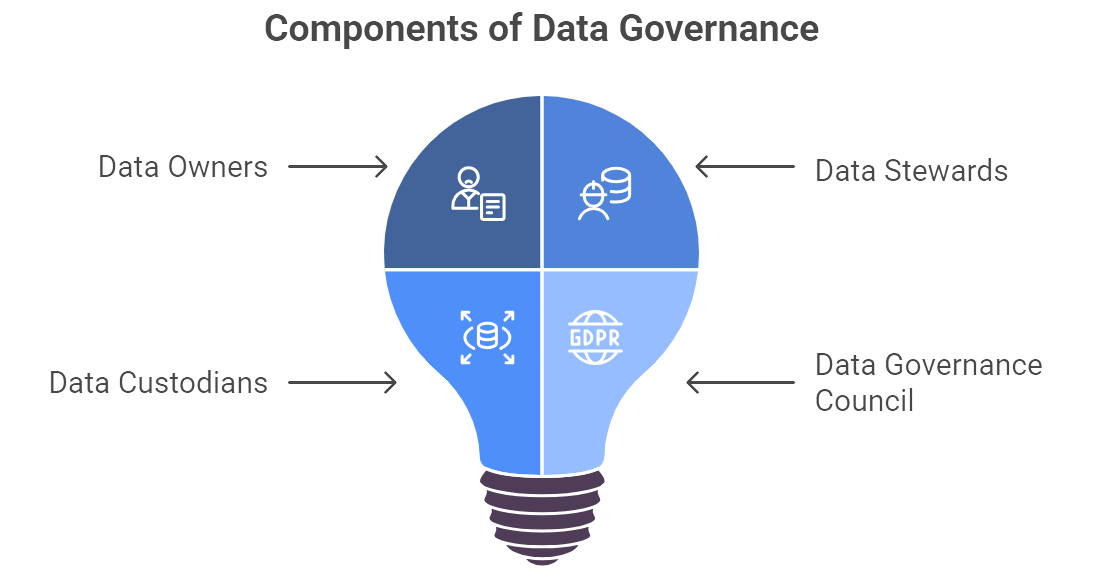
Figure 4: Illustration of the core components of data governance, showcasing the collaborative nature of roles like Data Owners, Stewards, and Custodians, and the guiding influence of the Data Governance Council and regulatory compliance such as GDPR. (Image by Napkin).
A strong governance framework typically outlines the roles of Data Owners, Data Stewards, and Data Custodians, among others (Data Governance, 2024). Data Owners—often senior executives—have ultimate accountability for the data within their domain. The CFO might be the Owner of finance data, while a Chief Marketing Officer could oversee marketing and customer data. Data Stewards handle the day-to-day realities of ensuring the information is accurate, consistent, and aligned with business definitions, preventing the classic scenario where “customer ID 1234” means one thing to sales and another to product development. Sometimes a Data Governance Council or similar body oversees the entire program, setting policies around retention periods, classification levels, and approved usage. These policies may demand that personal data be encrypted, or that “critical data elements” be audited regularly for accuracy—an approach that mitigates the freewheeling data sprawl that plagues many modern enterprises.
In an era of rampant cyber threats and evolving privacy laws, data governance directly intersects with security and compliance. Regulatory regimes like GDPR, HIPAA, PCI-DSS, and CCPA introduce stringent requirements for data handling, from consent management to encryption standards (Lessons for Healthcare from Finance About Data Governance). A healthcare provider might implement role-based access controls to patient data, ensuring only authorized clinicians can see detailed medical histories. A bank storing credit card information must comply with PCI-DSS encryption protocols, or risk fines and reputational damage if a breach occurs. Beyond these legal obligations, there is the simple business reality that customers and partners need to trust you. Failure to secure sensitive data can erode that trust overnight, tarnishing brands and exposing executives to unwelcome scrutiny. The upshot is that security and privacy are not afterthoughts—they form the bedrock upon which data governance policies are built, shaping access permissions, audit trails, and incident response procedures.
Different industries impose their own flavors of governance and compliance. Financial institutions, for instance, must align with BCBS 239 guidelines on risk data aggregation and reporting (Basel Committee). This means banks need traceable data lineage, robust quality controls, and near-real-time reporting capabilities. Insurance firms juggle Solvency II requirements, while healthcare organizations face a mosaic of rules around patient privacy, data exchange formats, and EHR standards. Logistics operators grapple with interoperability guidelines like EDI, which facilitate efficient data sharing across supply chains, but also demand consistent data definitions. Although these regulations and standards may seem daunting, they serve a dual purpose: safeguarding stakeholders—be they consumers, investors, or patients—and compelling organizations to maintain well-structured, high-integrity data. Companies that excel at governance often discover that compliance can be an innovation driver rather than a hindrance, as it forces them to adopt streamlined processes that lower risk and speed up analytical workflows.
Implementing data governance at enterprise scale is a formidable challenge, but modern tools are making it more feasible. Data catalog software automatically crawls databases to inventory data assets, track their lineage, and document business definitions (Data Governance, 2024). Platforms like Collibra or Informatica offer dashboards where stakeholders can see the current “health” of datasets, log quality issues, and identify the relevant Data Steward or Owner to initiate corrective action. Master Data Management (MDM) systems centralize key data points—such as customer IDs or product SKUs—into a single repository, eradicating the chaos of multiple, conflicting versions scattered across spreadsheets and legacy applications. AI-driven automation further accelerates governance tasks by spotting policy violations or classifying new datasets according to sensitivity. A real-world example might be an e-commerce site that automatically flags personal details (like email addresses) if they accidentally appear in a public-facing data store, triggering an alert to the security team. Rather than treat governance as a grudging chore after the fact, these technologies embed policies into the data pipeline from inception, smoothing friction between compliance and innovation.
Critics of governance sometimes paint it as red tape that slows down data accessibility. Done poorly, that critique has merit: nobody wants a labyrinth of approvals turning every data request into a quest worthy of medieval chivalry. Yet, best-in-class organizations showcase another reality—proper governance actually accelerates responsible data sharing and fosters trust in the analytics process (Gartner). When people trust that the data is well-defined, consistent, and secure, they use it more confidently. Teams spend less time arguing about whose numbers are correct and more time analyzing what the numbers signify for business decisions. In a retail setting, for example, consistent product codes and supplier data might allow different departments—merchandising, marketing, supply chain—to share a single view of inventory. This eliminates duplication and guesswork, shaving weeks off new project rollouts. Analysts can focus on generating insights rather than hunting down the “real” sales totals. The result is a cultural shift where data becomes a lever for innovation, not just an IT resource to be locked away.
Real-life stories illustrate governance payoffs with refreshing clarity. A global bank that introduced an enterprise-wide data governance framework saw a dramatic reduction in manual data reconciliation for risk reporting, freeing staff to focus on more strategic analyses. A consumer goods conglomerate created a Data Governance Council that preemptively resolved data definition battles among different regions and product lines, accelerating analytics initiatives by months. Meanwhile, 67% of companies confirm that governance is crucial to improving data quality, reinforcing the link between structured processes and more accurate, timely information (Data Governance, 2024). Any senior executive who has suffered through costly data mishaps—a million-dollar marketing campaign hitting the wrong audience, or a regulatory fine for inaccurate reporting—needs no persuasion about governance’s ROI. The up-front effort of designating roles, clarifying policies, and investing in the right tools often pays for itself many times over by preventing fiascos that can derail even the most promising data science projects.
Ultimately, data governance, security, and compliance form the foundation upon which advanced data analytics—and by extension, data-driven strategy—can stand. Without these guardrails, even the flashiest AI initiatives risk devolving into ethical quagmires, data breaches, or plain old confusion about whose numbers to trust. By embedding governance principles into day-to-day processes, organizations minimize risk and maximize their capacity for agile decision-making. Executives gain the freedom to pursue transformative analytics projects—machine learning–powered personalization, real-time pricing, predictive maintenance—knowing that the underlying data is robust, consistent, and legally compliant. In that sense, governance is not a barrier to innovation but the scaffolding that supports sustainable, long-term growth in a data-driven economy.
4.6. Conclusion and Further Learning
Data has unequivocally become a strategic asset for enterprises across finance, retail, healthcare, FMCG, distribution, and logistics. This chapter demonstrated that to unlock data’s full value, business leaders must source data broadly, ensuring they harness the rich variety of internal and external information now available, maintain high data quality, treating accuracy and consistency as non-negotiable to trust the data, and govern data diligently with the right policies, roles, and compliance measures. By investing in these foundations – sources, quality, and governance – organizations set the stage for powerful data-driven strategies. The payoffs include sharper decision-making, personalized customer experiences, operational efficiencies, and even new revenue streams from data. Key takeaways for executives are to champion a data-driven culture, allocate resources to robust data management practices, and align data initiatives with business objectives. Going forward, those companies that treat and manage their data as a true strategic asset will be positioned to adapt faster, innovate more effectively, and outperform competitors in the digital economy. In summary, the strategic management of data is not a technical hurdle but a business imperative – one that requires vision, stewardship, and continuous commitment from leadership to translate into sustained competitive advantage.
Even with a solid understanding of data as a strategic asset, true mastery comes from continual exploration and questioning. Below is a set of thought-provoking prompts designed to encourage deeper inquiry into the concepts of data sources, quality, and governance. These prompts can be used to guide further research or drive discussions with AI assistants and experts. By delving into these questions, business leaders and learners can uncover nuanced insights, adapt general principles to specific industry contexts, and stay abreast of emerging trends in data management. Each prompt is an invitation to explore scenarios and strategies beyond the chapter, helping to reinforce knowledge through application and critical thinking. Use these as springboards for brainstorming within your team or as a basis for consulting an analytics expert or AI for detailed explanations. Engaging with such open-ended questions will not only solidify what you’ve learned, but also cultivate the forward-looking mindset needed to keep leveraging data for strategic advantage in a rapidly evolving landscape.
Cross-Industry Data Use: How are data-driven strategies implemented differently in finance, retail, healthcare, and logistics? – e.g. compare how a bank versus a hospital would leverage data sources and what unique challenges each faces.
Internal vs. External Data: What external data (from partners, third-parties, or open data sources) could enhance your organization’s internal datasets? – explore the potential and risks of integrating external data for richer insights.
Data Volume vs. Quality: If you had to prioritize, would you focus on collecting more data or improving the quality of existing data? – discuss the trade-offs and scenarios where one is more beneficial than the other.
Real-Time Data Decisions: In what business situations is real-time data most critical? – identify operations (e.g., stock trading, emergency healthcare, supply chain routing) that gain competitive edge from instant data, and how to manage the quality of fast-moving data streams.
Regulatory Compliance Strategies: How can a company ensure compliance with data privacy laws (like GDPR or HIPAA) while still extracting business value from data? – propose governance practices that balance legal obligations with innovation (for instance, anonymization techniques or privacy-by-design frameworks).
Data Governance Frameworks: Design a basic data governance framework for a mid-sized enterprise. – outline key roles (e.g., who should be the Data Owner for customer data?), policies, and metrics that such a company should institute.
Improving Data Quality: What are effective methods to identify and clean “dirty data” in a large customer database? – consider tools (software for data cleaning), processes (routine audits, crowdsourcing corrections), and roles (data steward responsibilities) in your answer.
Case Study – Data Failure: Analyze a known case where poor data management led to a business failure or scandal. – for example, a major analytics error or a data breach; discuss what went wrong in terms of sources, quality, or governance, and how it could have been prevented.
Data Monetization Opportunities: What untapped data in your industry could be monetized or turned into a new service offering? – brainstorm how companies can package insights or data (perhaps selling trend analyses, or offering benchmarking data to partners) and what governance would be needed.
Emerging Technologies: How might emerging technologies like AI and machine learning improve data quality or governance? – explore concepts such as AI-driven data cleansing, anomaly detection for quality, or automated policy enforcement, and their potential impact.
Cultural Change: What steps can leadership take to foster a data-driven culture in an organization historically driven by gut instinct? – outline change management tactics: training programs, incentive realignment (rewarding decisions backed by data), success stories to build momentum, etc.
Data Strategy Roadmap: How would you create a 3-year roadmap for a company to evolve into a data-driven enterprise? – consider stages like building infrastructure, improving quality, establishing governance, then advanced analytics, with tangible milestones at each stage.
Data Ethics: What ethical considerations arise when using customer data for competitive advantage? – discuss issues such as consumer consent, bias in algorithms, transparency to users, and how governance policies can address these concerns while still allowing data use.
KPIs for Data Management: Which key performance indicators should a firm track to gauge the success of its data governance and quality efforts? – suggest metrics (e.g., data error rate, time to data access, number of compliance incidents, user satisfaction with data) and how they inform management decisions.
Industry 4.0 and IoT Data: For manufacturing or logistics companies, how can IoT sensor data be leveraged beyond operations? – examine possibilities like predictive maintenance services, improved product design through usage data, or new business models, and the governance needed to manage sensor data deluge.
Data Silos Breaking: What are common causes of data silos in organizations, and how can they be broken down? – discuss organizational barriers (departmental ownership, legacy systems) and solutions (data integration platforms, cross-functional data teams, executive mandates for sharing).
Crisis Management: How should a company respond when a critical data quality issue is discovered (for example, a mistake in financial reporting data)? – outline an incident response plan: immediate actions (stopgap measures, notifications), root cause analysis, remediation steps, and long-term fixes via governance.
Scaling Data Operations: As a company’s data grows in volume and complexity, what strategies ensure that quality and governance keep pace? – consider the use of data lakes, modular governance processes, incremental automation, and scaling the data team, as well as avoiding common pitfalls in growth phases.
Benchmarking Maturity: How can an organization benchmark its data management maturity against industry best practices? – suggest frameworks or models (like DAMA DMBOK, CMMI for data) to assess current capabilities in sourcing, quality, governance, and identify gaps to target.
Future Trends Discussion: Envision the role of data as a strategic asset 10 years from now. – speculate on how trends like quantum computing, advanced analytics, or even stricter regulations might change the way organizations collect, manage, and leverage data, and what enduring principles from today will still apply.
By exploring these questions, you deepen your understanding and discover practical nuances of data strategy. Each prompt encourages looking at data management from different angles – whether it’s applying concepts to real scenarios, evaluating your organization’s practices, or anticipating future developments. Embrace the opportunity to discuss and research these topics further. Remember, the field of data is ever-evolving; continuous learning and curiosity are your allies in staying ahead. The more you question, probe, and experiment, the more adept you become at turning data into actionable strategy. Keep pushing the boundaries of your knowledge – the insights you gain will empower you to lead your organization confidently in the data-driven world.
Understanding theory is vital, but the real value comes from putting concepts into practice. The following hands-on assignments are crafted to help you apply the chapter’s insights in realistic business scenarios. These exercises are suited for busy professionals and do not require heavy technical work, but they will prompt you to think deeply about how to implement data strategies within an organization. By engaging with these tasks, you’ll bridge the gap between conceptual knowledge and practical execution – learning by doing. Each assignment focuses on a core aspect of data as a strategic asset (sources, quality, governance, or usage) and provides clear instructions so you can get started. Executives and team leaders can use these as workshop activities or self-guided projects to sharpen their skills. Tackle them at your own pace, and consider involving cross-functional colleagues for a richer perspective. These assignments will not only reinforce what you’ve learned in this chapter, but also build confidence in your ability to manage and leverage data effectively. Let’s turn insights into action.
🛠️ Assignments
📝 Assignment 1: Data Source Inventory (Industry-Specific)
🎯 Objectives:
Help you identify and categorize diverse data sources within a specific industry. Develop an understanding of internal vs. external data, and recognize how different formats, quality levels, and update frequencies shape an organization’s ability to leverage data.
📋 Tasks:
Select one industry of interest—finance, retail, healthcare, FMCG, or logistics—and imagine you are building a data ecosystem for a hypothetical company in that field. Compile at least ten data sources. Split them into internal (transaction databases, CRM, ERP logs) and external (social media feeds, market research, government data, etc.). Document each source’s format (structured vs. unstructured), potential value (what insights or decisions it might support), and any known challenges (e.g., limited update frequency, lack of standardization, missing metadata).
💡 Guidance:
When finalizing your list, think about how combining these sources could yield deeper insights. A CRM system might reveal detailed customer purchase patterns, while social media sentiment could show real-time shifts in consumer attitudes. Merging these insights can unlock powerful strategic perspectives. If time permits, replicate this exercise for a different industry or conduct an actual data source inventory within your own organization. This approach sharpens your ability to recognize the breadth of data available and plan cohesive data-collection strategies.
📝 Assignment 2: Data Quality Audit and Cleanup Plan
🎯 Objectives:
Enable you to spot common data quality issues, investigate root causes, and propose both immediate and long-term remedies. Reinforce the concept that clean, reliable data underpins effective analytics and informed decision-making.
📋 Tasks:
Obtain a sample dataset—ideally relevant to your industry—either from public sources or as a simulation. Examine the data for at least three distinct quality problems, such as duplicates, missing entries, inconsistent naming conventions, or obvious errors. Identify possible causes (human error, system glitches, poor integration) and propose methods for rectifying them (Excel functions, SQL scripts, or data preparation tools). Then outline a plan to prevent future issues by establishing validation rules, improving staff training, or enhancing system checks.
💡 Guidance:
Where feasible, use real data from your workplace (while respecting privacy or confidentiality constraints). Document your findings in a short memo or presentation, detailing each issue and the cleanup approach. Consider automating repetitive tasks using basic scripts or data profiling tools. This practical exercise helps you develop a systematic approach to auditing and maintaining data quality over time.
📝 Assignment 3: Draft a Data Governance Policy
🎯 Objectives:
Familiarize you with the fundamentals of structuring data governance, from setting policy objectives to naming essential roles and establishing compliance measures.
📋 Tasks:
Assume you are newly appointed to lead data governance for an organization. Write a concise (1–2 page) policy document outlining the scope, objectives, governance roles (Data Owners, Stewards), and core principles or rules. Incorporate elements of data quality standards, privacy obligations, and any relevant industry regulations (PCI, SOX, HIPAA, etc.). Include at least three clear policy statements—e.g., “All critical data fields must meet minimum accuracy and completeness thresholds.” Conclude with a brief note on how the governance policy will help meet compliance requirements.
💡 Guidance:
Stay focused on clarity and practicality. The goal is not legal perfection but a solid foundation that executive stakeholders can endorse. After drafting, read it from the standpoint of a department head or senior manager. Is the policy’s purpose clear? Does it convey accountability? Incorporate feedback or suggestions from peers to refine your policy. Over time, you can expand this outline into a more comprehensive charter with added details on data classification and escalation procedures.
📝 Assignment 4: Case Study Analysis – Data-Driven Success
🎯 Objectives:
Deepen your understanding of how real organizations achieve tangible results from data initiatives. Identify best practices and lessons learned that can be transferred to other contexts.
📋 Tasks:
Choose a known organization that reaped notable benefits through data-driven strategy (Netflix, Tesco, Johns Hopkins Hospital, DHL, etc.). Research and craft a concise (around one page) case study explaining their key business challenge, the data sources and governance measures they employed, and the outcomes they achieved—whether revenue gains, cost savings, user growth, or improved customer loyalty. Conclude with 2–3 lessons relevant to your own work environment.
💡 Guidance:
Make explicit references to themes from this chapter—data quality, governance, innovative usage of new data streams, or leadership influence. Outline how these factors contributed to the success (or failures) in the case. When you have finished your write-up, consider sharing it with your team or colleagues to spur conversation on whether those same strategies could work in your context.
📝 Assignment 5: Data-Driven Decision Simulation
🎯 Objectives:
Highlight the practical impact that reliable data (or the lack thereof) has on key business decisions. Illustrate how data-driven approaches foster greater confidence and clearer outcomes compared to guesswork or intuition.
📋 Tasks:
Pick a scenario where a business decision depends heavily on data—expanding a product line, allocating budgets, optimizing routes in logistics, or prioritizing hospital department funding. Create two versions of this scenario: in the first, you have abundant, clean, well-governed data; in the second, the data is incomplete or riddled with inaccuracies. Describe how your decision-making differs in each context. If possible, use a simplified dataset (public or custom) to run basic calculations or comparisons for the data-rich scenario.
💡 Guidance:
Write 2–3 paragraphs or design a short slide deck contrasting the two approaches. Emphasize how lacking data forces guesswork and may undermine confidence in the outcome, while robust data bolsters more precise and justifiable decisions. You can strengthen this exercise by employing actual numbers in the data-rich scenario—calculating basic statistics or cost comparisons. Reflect on how likely you are to trust each outcome. This assignment underlines the tangible returns of proper data investment and may help you champion better data practices within your role.
By completing these practical assignments, you actively translate knowledge into skills. Each task is an opportunity to apply concepts from the chapter to realistic situations, reinforcing your understanding through experience. Don’t hesitate to iterate on these assignments – for instance, revisit your governance policy draft after a few weeks with fresh eyes, or update your data inventory as you learn of new sources. To further refine and expand your skills, consider the following: seek feedback from colleagues on your assignments (peer review can reveal new perspectives), experiment with simple data tools (like data visualization software for your case study, or a data quality plugin for your audit) to become more hands-on, and stay curious by exploring additional resources (such as industry reports or courses on data strategy). Remember that building competency in leveraging data is a journey; each practical step you take builds confidence and capability. Keep engaging with real-world data challenges, and gradually, you’ll become not just conversant in treating data as a strategic asset, but truly fluent in executing data-driven initiatives in your organization.
Comments