Chapter 7
Data Science in Retail – Personalization and Operational Efficiency
"Personalization is the key to cutting through the noise and making a meaningful connection with customers." — Angela Ahrendts
In this chapter, we explore how data science powers customer personalization and operational efficiency in retail. We will examine recommendation engines, demand forecasting, dynamic pricing, customer segmentation, and supply chain optimization, illustrating each with real-world case studies. We’ll also discuss future trends—from hyper-personalized shopping to blockchain and IoT—that promise to further transform retail. The goal is to provide business leaders with a clear understanding of fundamental concepts, strategic frameworks, and practical applications of data science in retail. Each section outlines key ideas at three levels: fundamental principles, conceptual approaches, and practical implementations.
7.1. Introduction Data Science in Retail
Data science is no longer a fringe experiment reserved for tech-savvy startups; it has firmly embedded itself at the heart of modern commercial strategy. Organizations that master the art of gathering, interpreting, and acting on data can quickly outmaneuver slower-moving competitors. In the retail sector specifically, data science has transformed everything from inventory management to personalized marketing. The sheer volume of information—spanning point-of-sale transactions, loyalty programs, website clicks, and even social media chatter—presents enormous opportunities for uncovering consumer insights and streamlining operations. The magic, of course, is in the proper application of analytics and AI. When done right, you get near-oracular clarity into customer preferences and supply chain dynamics. When done poorly, you end up with costly technology projects and absolutely no measurable return.
Many executives initially see data science as a purely technical function or, worse, an inscrutable black box conjured up by their data scientists. However, understanding fundamental concepts like classification, regression, and deep learning can be a game-changer for senior leaders looking to guide strategic decision-making. By translating raw data into actionable insights, a well-designed data science program can reduce waste, predict demand spikes, and offer precisely the right product at the right moment to the right customer. Indeed, forward-thinking retailers leverage advanced algorithms to optimize marketing campaigns, improve product recommendations, and automate the more mundane elements of stock replenishment. The results speak for themselves in both top-line growth and bottom-line savings, with those insights-rich organizations outpacing their peers in both profit and market share (McKinsey). It might seem like magic, but it’s really just a well-trained model doing what it was designed to do.
The foundations of data science start with something far less glamorous than machine learning: data collection and cleaning. If your raw data is inaccurate, incomplete, or simply irrelevant, no amount of predictive modeling will fix that underlying dysfunction. It’s a bit like expecting fine cuisine when your main ingredients are rotten. Seasoned data scientists know they spend a significant chunk of their time scrubbing and organizing information into a usable format. Executives who underestimate this step often experience delays, budget overruns, and a slow realization that cutting corners on data quality is the business equivalent of building on quicksand. There is also an important question of data governance, which ensures that the right people have access to the right information under the correct regulatory framework—especially when dealing with sensitive consumer details. Balancing innovation with privacy, regulatory obligations, and ethical considerations is key to ensuring that data-driven initiatives are both effective and trustworthy (Microsoft Industry Blogs).
Once reliable data pipelines are in place, companies can pivot to the more exciting stages of the data science lifecycle: exploratory analysis, model building, and model evaluation. Exploratory Data Analysis (EDA) is the detective work that surfaces trends, relationships, and anomalies lurking in the data. By visualizing distributions, identifying outliers, and investigating correlations, analysts piece together insights that either confirm or challenge existing business hypotheses. This iterative exploration often acts as a reality check, unearthing unexpected patterns—like a product that sells better in a specific region or a customer segment that responds poorly to a certain promotion. Such revelations not only sharpen the focus for subsequent modeling but also provide immediate opportunities for targeted interventions. After EDA, teams proceed to develop predictive or prescriptive models using techniques ranging from linear regression and decision trees to the latest deep learning architectures. The choice of method depends on the problem’s nature. Forecasting demand for seasonal products might call for time-series models, while personalizing shopping experiences often benefits from recommendation algorithms that leverage collaborative filtering or neural networks.
Evaluation then steps in as the polite but unforgiving critic. Testing the model on historical data is standard practice, but in a commercial context, executives also want to see how the model might behave in the “real world.” This could involve back-testing strategies against previous sales periods, running pilot programs in selected regions, or A/B testing with live audiences. The ultimate question is whether the predicted outcome—be it increased customer retention, higher average order value, or improved supply chain efficiency—justifies the cost and complexity of the deployment. If it does, you move on to rolling out the model at scale. If it doesn’t, you return to the drawing board. This phase is often accompanied by wry internal jokes about “yet another pivot,” but the truth is that iteration is par for the course in data science. Even the most experienced teams seldom get it right on the first try.
Deployment is the moment when your data science initiative steps out of the lab and faces the music. Integrating models into everyday business operations might mean automating recommendations in an e-commerce platform or enabling real-time supply chain re-routing based on machine learning forecasts. Either scenario requires tight collaboration across functional teams—software engineers to handle production environments, IT to manage infrastructure, domain experts to interpret results, and executives to sponsor and champion changes. Suffice it to say, if one link in this chain fails, the entire system can collapse in a spectacularly unprofitable fashion. Yet when done successfully, this is where the real payoff lies: in continuously improving customer experiences and making smarter decisions faster.
An emerging frontier in data science—especially relevant for retail but increasingly important across all commercial sectors—is real-time analytics. Gone are the days when weekly or monthly reports provided sufficient insight. Retailers now strive to personalize offers at the moment a user clicks on a product page or to optimize inventory routes within hours rather than days. This requires sophisticated streaming data architectures, low-latency processing pipelines, and algorithms capable of learning (or at least adapting) on the fly. Properly orchestrated, real-time analytics can be the ace in the hole that sets a retailer apart, giving them the agility to capitalize on fleeting market conditions. Yet executives should approach these technologies with a healthy dose of skepticism. Slick demos often hide the complexities—and costs—of building and maintaining such systems.
No conversation on data science in a commercial setting would be complete without addressing AI ethics. The more advanced the analytical techniques, the greater the potential for unintended consequences. Biased models might discriminate against certain demographic groups, personalization can sometimes verge on invasive surveillance, and real-time analytics can inadvertently create echo chambers that reinforce existing customer behaviors instead of expanding them. Leading organizations are tackling these challenges through clear governance policies, diverse data science teams, and robust transparency measures. It’s not just about “doing good for society” but also about maintaining brand integrity and long-term customer trust. One public scandal fueled by an unethical AI application can do irreversible damage to corporate reputation, so executives must be well-versed in these risks and hold data science teams accountable.
A final layer of complexity—one that seldom gets the fanfare it deserves—is the ongoing maintenance of data science initiatives post-deployment. Models degrade over time as market conditions, competitor actions, and consumer preferences shift. This phenomenon, known as model drift, can render once-accurate predictions obsolete. Consequently, an organization that invests in data science must plan for periodic retraining, model recalibration, and system upgrades. Successful teams implement feedback loops that monitor performance metrics, capturing fresh data that feeds into the next iteration of modeling. It might not be glamorous, but this culture of continuous improvement distinguishes organizations that ride the wave of data-driven innovation from those that are swept under it.
From startups to global conglomerates, the need for a cohesive data science strategy is universal. It requires executive vision, technical expertise, cross-functional collaboration, and perhaps most importantly, a culture that embraces learning from the inevitable mistakes. Leaders who champion data science as a strategic pillar—rather than a peripheral lab experiment—set the tone for innovation. They create the conditions in which data scientists, IT, domain experts, and front-line staff can collaborate effectively. Aligning these stakeholders around clear objectives ensures that each data project supports overarching commercial goals, whether that means boosting profit margins, delighting customers, or driving long-term brand loyalty.
Perhaps the most brutal truth is that data science is not a cure-all. It won’t fix flawed business models or incompetent management. However, when properly understood and strategically deployed, it can uncover growth opportunities, highlight operational inefficiencies, and enable real-time adaptability in a volatile market. For retail executives, the importance of data science has become undeniable. Surveys, both formal and informal, show that companies leveraging advanced analytics to guide merchandising, marketing, and supply chain decisions regularly see accelerated revenue growth and improved margins (McKinsey). Data science, in other words, has evolved from a nice-to-have capability to a must-have commercial imperative. For those ready to make the leap, the road may be filled with buzzwords, evolving technologies, and the occasional overhyped vendor pitch—but the rewards for getting it right are simply too large to ignore.
7.2. Customer Personalization & Recommendation Engines
Customer personalization sits center stage in retail’s grand performance of data science, where machine learning and AI unify to craft individualized shopping experiences that sometimes feel more attentive than your personal stylist. Executives rightly see these capabilities as a revenue multiplier and a loyalty booster rolled into one. At its core, customer personalization uses algorithms to decipher everything from past purchases and browsing history to subtle preferences a customer might not even know they have. The concept is simple: treat each customer as a “segment of one” and deliver precisely what they want before they even realize they want it. This notion of preemptive service was once the stuff of science fiction, but it has morphed into a commercial imperative for any retailer wishing to stay relevant.
The mechanics of personalization often revolve around recommendation engines that show up on e-commerce sites, mobile apps, and email campaigns. These engines employ machine learning techniques—collaborative filtering, content-based filtering, or deep learning—to identify patterns in customer data and then generate suggestions in real time. The immediate and tangible upside of implementing a robust recommendation engine is reflected in increased basket sizes and elevated customer engagement. It is well known that Amazon, which constantly refines its recommendation engine, attributes a large share of its sales (around 35 percent) to these AI-driven suggestions (FACT-Finder). That means an enormous slice of revenue stems from the “you may also like” panels that nudge customers to buy more. Other retailers might not replicate Amazon’s success overnight, but they can capture a similar effect by strategically tailoring offers, content, and even landing-page layouts.
The broader impact of personalization has been documented in various studies. Retailers that excel in personalization generate significantly higher revenue from personalization-driven activities—up to 40 percent more than their average competitors (McKinsey). Additional research indicates that most consumers these days not only welcome personalization but expect it. One survey found that 71 percent of shoppers anticipate some degree of tailored interaction, while 76 percent report frustration when personalization is missing (McKinsey). A separate study discovered that 80 percent of consumers are more inclined to do business with brands offering personalized experiences (Epsilon, 2018). These figures translate to more than just warm, fuzzy feelings. They speak directly to conversion rates, average order value, and customer lifetime value. Executives who view personalization as a “nice-to-have” might want to revisit the math. The sums are not trivial.
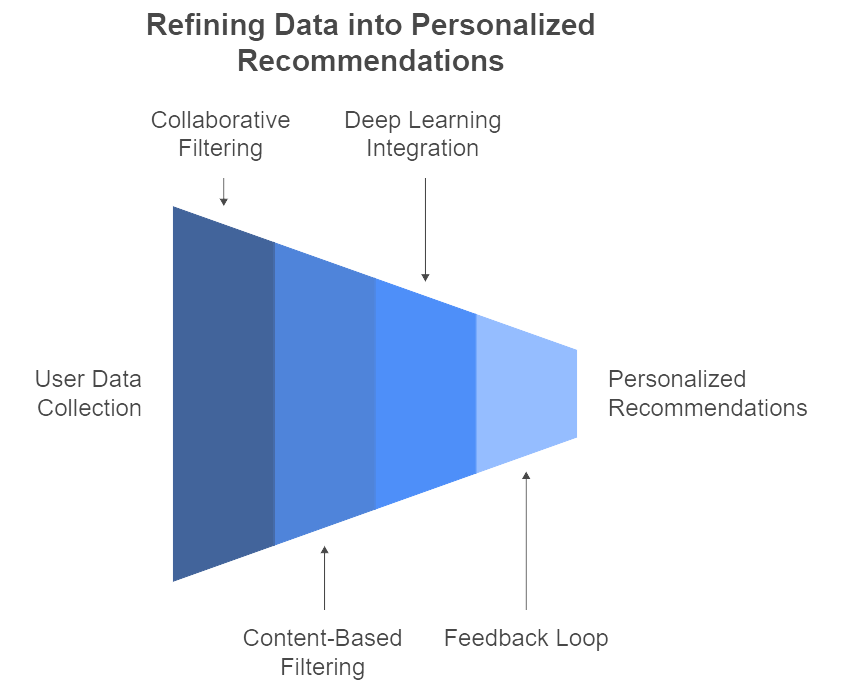
Figure 1: Illustration of of how user data is transformed into personalized recommendations through a combination of filtering methods and a feedback loop. (Image by Napkin).
A recommendation engine typically begins by collecting as much relevant data as possible. This includes transaction history, browsing patterns, search queries, wish-list items, product ratings, and demographic information. The next step is often collaborative filtering, where the system identifies “look-alike” customers whose past behaviors align with each other, then assumes they might share future interests. Alternatively, content-based filtering leverages features of the items themselves—product descriptions, tags, or attributes—to recommend similar or related products. Deep learning approaches combine these and other factors, sometimes capturing hidden correlations that simpler models miss. The real intrigue lies in how these algorithms adapt over time. Many recommendation engines employ continuous feedback loops: as customers make new purchases or show disinterest by ignoring a suggestion, the model retrains (or at least updates its parameters) to refine the next set of recommendations. It’s a perpetually evolving process that can generate results that feel uncannily accurate.
One often-overlooked aspect is how to measure success. Traditional metrics like click-through rate and conversion rate are valuable, but more sophisticated organizations also track changes in net promoter score, average order value, and the incremental revenue directly attributable to personalized recommendations. Running A/B tests allows data science teams to see if a new algorithm truly outperforms the old one. This test-and-learn culture is where executive support makes all the difference, because real-time experiments and iterative improvements require infrastructural and organizational commitments that can be costly. However, those costs generally pale in comparison to the lost opportunity of failing to engage your customer base in a personalized way.
Behind the glossy user interface of a recommendation engine lies a complicated web of data pipelines, machine learning models, and integration layers. The development process starts with data ingestion—potentially involving multiple data lakes, warehouses, or real-time streams. Data scientists then spend an embarrassingly large portion of their time cleaning and validating that data. After all, an engine fueled by inconsistent or inaccurate data will yield warped suggestions that can alienate rather than delight. Next comes model selection. Depending on the scale and scope, some retailers opt for simpler techniques with rapid iteration cycles, while others invest heavily in deep learning architectures that can make more nuanced predictions. In either scenario, champion-challenger frameworks are often used. One model—the champion—is in production, while other models—the challengers—are tested in parallel until one outperforms the incumbent.
The final hurdle, deployment, is by no means trivial. Proper integration into the e-commerce platform or email campaign manager is essential for recommendations to surface at the right time. This calls for cross-functional collaboration among data scientists, software engineers, and marketing teams. Once deployed, the recommendation engine demands continuous monitoring. Market conditions change, product lines evolve, and customers shift their preferences. A robust system flags drops in performance or anomalies in suggestion patterns, triggering retraining or updates. Neglecting this maintenance can lead to the dreaded phenomenon of “model drift,” where an algorithm once hailed as genius slowly becomes irrelevant. Retailers who treat these engines as one-and-done implementations inevitably find themselves scrambling when sales mysteriously plateau.
Sephora exemplifies how the retail experience can be augmented through strategic data science. The beauty retailer employs customer data from both online channels and in-store visits. The foundation is built on understanding individual preferences—be it skincare concerns or favored makeup brands—then offering targeted product recommendations and tutorials tailored to each shopper’s unique profile. This seamless experience extends to mobile apps that suggest new products based on a person’s purchase history and even facial scans (Sephora). The payoff manifests in higher customer satisfaction scores, repeat purchases, and a brand reputation that skews toward “innovative.” The lesson for executives across sectors is straightforward: personalization doesn’t just happen online. Brick-and-mortar environments, too, can be transformed by integrating data insights into the physical shopping journey.
Given personalization’s direct link to revenue, it’s easy for leadership to get caught up in the excitement and demand an overnight transformation. This fervor, while admirable, is often misguided. Building a recommendation engine that resonates with millions of customers is an iterative process that involves plenty of trial and error, data wrangling, and stakeholder alignment. Companies that attempt a rushed, top-down launch without first securing quality data or clarifying business objectives tend to end up with half-baked solutions that confuse both staff and customers. A better approach is to start with a well-defined pilot program—perhaps focusing on a specific product category or customer segment—measure the impact meticulously, and then scale up. At each step, it helps to keep open lines of communication between data scientists, marketing teams, and the IT department so everyone stays clear on objectives and results.
It’s also crucial to address the cultural dimension of personalization initiatives. Marketing and merchandising staff accustomed to traditional mass campaigns may feel threatened by an algorithm that reconfigures their promotional strategy. Meanwhile, data scientists can become frustrated by creative requests that contradict what the models indicate. Effective leadership can bridge these gaps by demonstrating how data science complements, rather than replaces, human expertise. This balancing act requires transparency around how recommendations are generated and how the data is governed. Privacy regulations and ethical considerations should not be an afterthought. One misstep in protecting customer data can severely damage brand credibility. Another pitfall is algorithmic bias, where certain customer segments receive suboptimal or even discriminatory recommendations. A robust governance framework, combined with regular audits of the algorithm’s output, can mitigate such risks.
As the industry evolves, personalization is moving toward real-time recommendations driven by streaming data. This means a retailer can adjust its website layout or promotional messaging literally as customers click through, based on second-by-second browsing patterns. Achieving such dynamic responsiveness typically requires sophisticated data pipelines and low-latency model inference. It may sound expensive—and it is—but the resulting spike in engagement and conversion can justify the investment for larger enterprises or those competing in hyper-competitive markets. Keep in mind, however, that real-time personalization is a double-edged sword. It can delight customers or spook them if the recommendations feel intrusive. Striking the right balance is as much about empathetic design as it is about technical prowess.
In short, personalization isn’t merely a tactic for boosting sales; it’s fast becoming a cornerstone of strategic differentiation. A well-executed recommendation engine delights customers by making their shopping journey more relevant and efficient. At the same time, it provides a measurable lift in everything from conversion rates to repeat visits. Getting to that point requires cross-functional unity, a culture that embraces experimentation, and a healthy tolerance for the complexities of data infrastructure. The retailers that figure out this puzzle—those that align leadership vision, data quality, technical capability, and creative flair—stand to create customer experiences that not only drive revenue but also build lasting brand loyalty.
7.3. Demand Forecasting & Inventory Optimization
Demand forecasting in retail has always been a high-stakes guessing game, largely because predicting human behavior is tricky at the best of times. The aim, of course, is timeless and straightforward: to have the right products in the right amounts at the right locations and at precisely the right moment. Historically, retailers relied on rudimentary methods such as simple averages or manual extrapolations of last year’s sales. Today, data science has reshaped demand forecasting into a far more sophisticated discipline that ingests not only historical sales but also a dizzying array of external signals—from weather data and local events to economic indicators and social media chatter (Data Science in Retail: Use Cases & Insights, Year). The result is an improved level of predictive accuracy that can help retailers sidestep the expensive pitfalls of empty shelves (stockouts) or warehouses bursting with unsold inventory (overstock).
Modern forecasting models capitalize on machine learning techniques like time-series analysis, regression methods, or neural networks (Complete guide to machine learning in retail demand forecasting | RELEX Solutions, Year). The essential difference between these and more traditional methods lies in the sheer volume of factors they can process. No human planner can plausibly weigh hundreds of variables for thousands of stock-keeping units (SKUs) across multiple time horizons—but an algorithm can, provided the data pipelines are well-constructed. This new era of predictive analytics gives organizations a level of agility and responsiveness once thought impossible. It’s one thing to guess that the holiday shopping season might start earlier this year; it’s another to confirm it quantitatively, reorder stock based on genuine demand signals, and then see fewer markdowns when the season ends.
Demand forecasting only reaches its full potential when it’s integrated seamlessly with inventory optimization. Predict a surge in demand for a specific product, and you can proactively boost your replenishment orders. Anticipate a dip, and you scale back accordingly. In practical terms, this interplay between forecasting and optimization helps retailers reduce costly out-of-stocks while preventing unwanted inventory buildup. Walmart, for instance, famously employs advanced analytics for store-level demand forecasting. By harnessing these predictive models, Walmart reduced its stockouts by 16 percent, increased inventory turnover, and as a direct result, elevated both product availability and sales (Transights, Year). It sounds almost too good to be true—better customer satisfaction and higher profits—but it works because every store’s forecast is continually refined by the tidal wave of sales data streaming in each day.
Walmart’s results are not an isolated anecdote. Advanced demand forecasting and inventory management reportedly contributed to a 2.5 percent increase in Walmart’s revenue and a 10 percent reduction in logistics costs (Transights, Year). These numbers might sound modest until you recall the company’s massive scale. Similar success stories can be found at Amazon and Alibaba, both of which deploy machine learning to forecast SKU-level demand and then optimize inventory deployment across distribution centers (RIT Digital Institutional Repository, Year). If that approach was once considered an optional advantage, it is now a necessity for retailers playing in the global arena. Customers expect speed, accuracy, and availability, and the first retailer to run out of a hot product risks losing customers who will shop elsewhere.
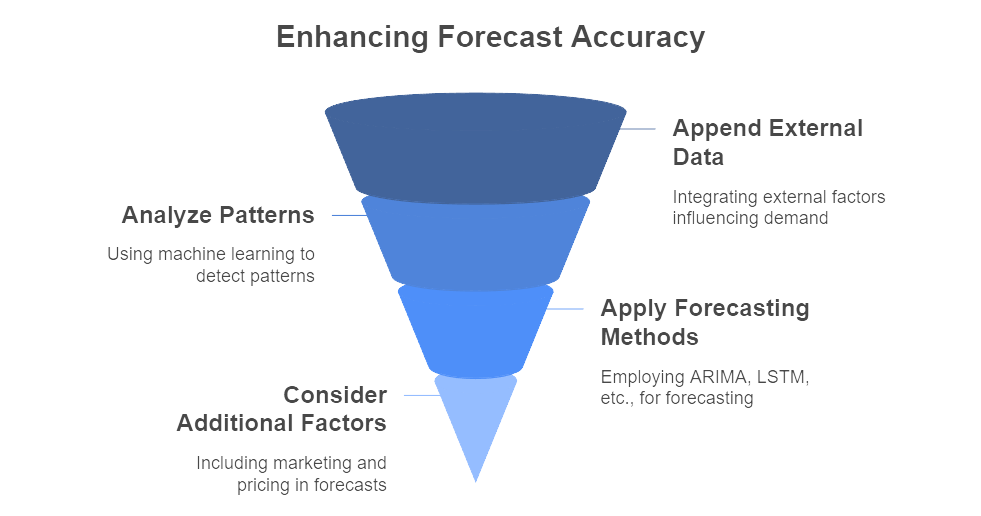
Figure 2: Illustration of the methodologies used to improve forecasting accuracy through a structured approach. (Image by Napkin).
At the fundamental level, forecasting starts with a clear objective: match supply to expected customer purchases. That means collecting and storing historical sales at the most granular level possible—SKU, store, or region—and then appending any relevant external data that might influence demand (BizTech Magazine, Year). Daily temperatures in summer can be critical for beverage sales; local sporting events might drive a spike in sales of team jerseys; regional economic shifts can shape discretionary spending. At the conceptual level, machine learning-based forecasting exploits these relationships by analyzing patterns that would be impossible to detect using a manual process. Methods such as ARIMA, exponential smoothing, or LSTM (Long Short-Term Memory) neural networks can capture seasonality, trends, and sudden shifts in consumer behavior. When combined with additional factors, such as marketing promotions or competitor pricing, the forecast becomes far more accurate.
The next step is inventory optimization, which takes the forecast as an input and then calculates the ideal re-order quantities and timing. This can involve operations research techniques like linear or integer programming, especially for multi-echelon inventory systems. Put in simpler terms, the forecast might say you’ll sell 5,000 units next week, but the optimization model will also account for lead times, safety stock levels, and transportation constraints to determine exactly how much to order now. In practice, advanced software integrates these two processes so they run automatically and continuously, ingesting live data, recalculating demand, and updating stocking rules. It is a far cry from the days when a monthly meeting and a shared spreadsheet passed for demand planning.
A typical demand forecasting journey starts with data collection and cleaning. This step is as glamorous as washing dishes after a dinner party, but there’s no skipping it. Retailers must pull data from point-of-sale systems, e-commerce platforms, marketing campaigns, and supply chain logs. A robust master data management (MDM) framework helps ensure SKU definitions are consistent across different systems. Once the raw data is consolidated, data scientists explore it—visualizing time-series trends, identifying outliers, and searching for correlations with external variables like price promotions or competitor tactics. This exploration often reveals that historical assumptions were wrong or oversimplified. Perhaps demand for certain products is highly weather-dependent in some locations but not in others. Or maybe a competitor’s periodic discount actually siphons away more sales than believed.
When the data is sufficiently clean, the model-building phase begins. Data scientists select or experiment with different algorithms. In many cases, they employ champion-challenger strategies: one model is the “champion” currently in use, while alternative “challenger” models run in parallel for comparison. The best-performing model—based on evaluation metrics like mean absolute error or mean absolute percentage error—becomes the new champion. Finally, that champion model is deployed into the operational environment. Here is where cross-functional collaboration is indispensable. The IT department ensures reliable data pipelines and computing infrastructure. The supply chain team interprets forecast outputs to adjust procurement or distribution schedules. Marketing coordinates promotions, and finance tracks costs, ensuring the entire operation stays within budget. Executives set the tone and ensure these groups share a common vision. Without a strong cultural push toward data-driven decision-making, even the flashiest forecasting tools can languish unused.
Demand forecasting, however advanced, can still go spectacularly wrong. A notorious issue is a lack of trust in the model’s results—usually because the model was developed in isolation by a team of data scientists who never communicated with on-the-ground merchandisers. Or the system might produce an obviously inflated forecast because the data pipeline is capturing promotional data incorrectly. These scenarios highlight the importance of transparent communication and robust data governance. Another pitfall is focusing too narrowly on forecast accuracy without considering practical constraints. A near-perfect forecast is worthless if you can’t actually position the inventory where it’s needed in time, or if the lead times to reorder are too long to respond to short-term fluctuations.
Organizations also risk “analysis paralysis” when they want the forecasting model to incorporate every possible variable. The more complicated a model, the more time and computational resources it demands, not to mention the difficulty in interpreting it. A simpler, well-calibrated model that stakeholders understand can often outperform a black-box approach that, in theory, might be more powerful but in practice is unwieldy. Finally, it’s essential to keep the models up to date. Consumer habits evolve, new competitors enter the market, and external conditions shift. If you fail to retrain or recalibrate, your once-shining model will degrade, and the forecasts will drift out of sync with reality.
Fashion retailers provide some of the most striking examples of the benefits of data-driven forecasting. By using machine learning models to identify short-term trends—like the sudden rise of a specific color or cut—companies can optimize orders from suppliers and avoid being stuck with racks of unsold clothing at the end of the season. Some have slashed their end-of-season markdown rates considerably, adding percentage points to their overall margins. In grocery retail, real-time demand forecasting helps prevent waste of perishable items, simultaneously benefiting profit margins and environmental sustainability. In electronics, forecasting can prevent that embarrassing scenario of releasing a new gadget only to realize that demand has exceeded supply by such a large margin that it will take months to restock. These are not just intangible benefits; they translate into measurable improvements in revenue, operational costs, and customer satisfaction.
On the intangible side, there is also a cultural shift. Executives who embrace data science in demand forecasting often discover that their organizations become more proactive and nimble. Teams learn to anticipate rather than just react, making them better prepared for everything from sudden changes in consumer preference to supply chain disruptions. The level of inter-departmental collaboration also improves, because everyone needs to understand how the forecast is produced, how to challenge it with business context, and how to act on its recommendations. This cross-functional synergy is the real secret sauce that turns a technical advancement into a commercial advantage.
Some leading retailers are already experimenting with real-time forecasting solutions that ingest streaming sales data and update projections within hours or even minutes. This is made possible by robust data architecture—think distributed computing, in-memory databases, and streaming analytics pipelines. While this is still cutting-edge and often costly, it offers a significant competitive edge in categories where demand can shift overnight, such as fashion trends or limited-edition product drops. Of course, one must tread carefully. Implementing real-time forecasting without ensuring adequate production and logistical agility is like installing an advanced GPS system in a car that has no engine. The technology might be shiny, but it won’t get you anywhere.
Demand forecasting and inventory optimization form the bedrock of modern retail operations. Powered by machine learning and enriched with data from every corner of the digital universe, these functions dramatically improve a retailer’s ability to match supply and demand precisely. Fewer stockouts mean happier customers, and fewer overstocks mean healthier profit margins. If that sounds like the holy grail, it’s because—done well—it often can be. Yet success requires more than flashy algorithms. It demands high-quality data, skilled data scientists, collaborative cross-functional teams, and executives who champion evidence-based decision-making. Leaders who treat advanced forecasting as a passing fad or a “tech thing” best left to specialists risk missing out on a powerful lever for competitiveness. Conversely, those who integrate these predictive capabilities into their broader commercial strategy find themselves better prepared to adapt, innovate, and thrive in a marketplace defined by change.
7.4. Dynamic Pricing Strategies
Dynamic pricing is the practice of regularly adjusting prices in response to a range of factors such as supply, demand, competitor behavior, and even the time of day. Although airlines and hotels originally popularized this approach—think of how airfare can spike if you book too close to the departure date—retailers have increasingly embraced the concept, largely thanks to AI and machine learning tools that make rapid price shifts feasible. The logic behind dynamic pricing is deceptively simple: if demand is high, and inventory is limited, raise prices to optimize revenue (and possibly moderate demand to avoid running out of stock entirely). If demand slumps, reduce prices or offer promotions to stimulate sales. As basic as that may sound, real-world implementation can be as complex as it is lucrative.
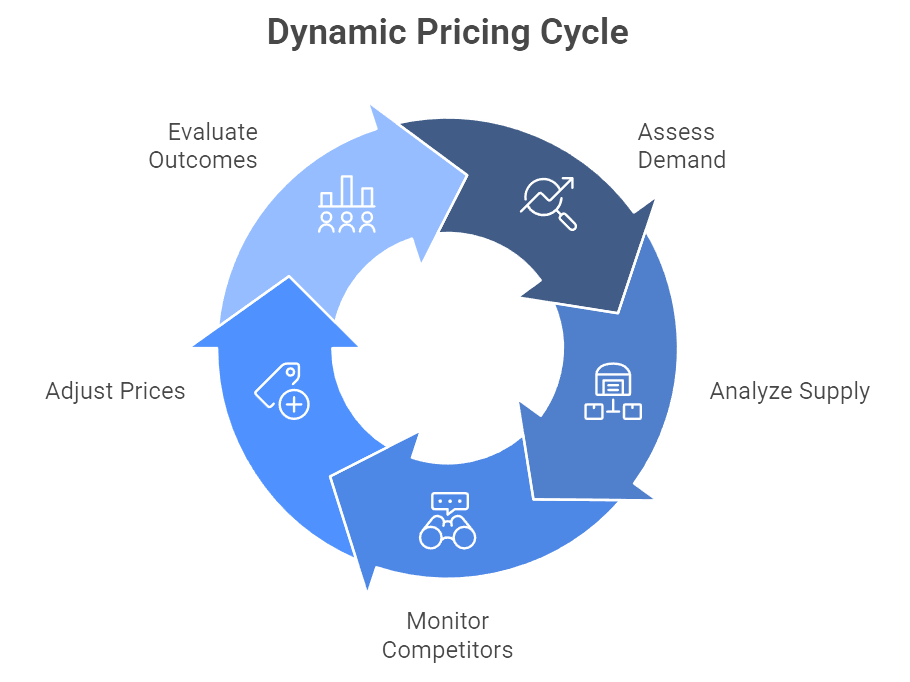
Figure 3: Illustration of the iterative process of assessing demand, analyzing supply, monitoring competitors, adjusting prices, and evaluating outcomes. (Image by Napkin).
/Much of the modern excitement around dynamic pricing stems from AI-powered solutions that scrape competitor websites for current prices, analyze recent sales velocity, check inventory levels, and then recommend (or automatically implement) updated prices in near-real time. Some online retailers shift prices as frequently as every hour to keep pace with market conditions. Amazon, for example, is notorious for making millions of price changes per day (Profitero). These changes can be as small as a few cents, yet even tiny variations, multiplied across thousands or millions of product listings, can significantly impact overall profitability. What used to require weeks of back-and-forth meetings among merchandising teams can now happen almost instantaneously, driven by algorithms that learn from transaction data and emerging trends. The goal is to hit the sweet spot that maximizes either revenue or market share without alienating customers.
A fundamental principle of dynamic pricing is that no price is ever set in stone. Instead, prices shift based on a torrent of signals, such as demand forecasts, inventory levels, and competitor moves. This is where the concept of price elasticity becomes vital. If customers are highly sensitive to price changes—like they are for groceries or basic household goods—a minor hike can send them running to a competitor. But for luxury goods or unique, limited-edition items, retailers might raise prices more aggressively because the customer’s willingness to pay is less elastic. Neglecting elasticity can undermine even the best data-driven strategy. There is a thin line between “optimizing revenue” and “driving your customers into the arms of your competitors.”
On a conceptual level, dynamic pricing relies on data-driven algorithms—often machine learning models—that assimilate multiple data streams and then propose a price that achieves certain objectives, whether that’s maximizing profit, increasing market penetration, or ensuring a quick sell-through of perishable goods. More sophisticated setups use reinforcement learning: these systems effectively learn from their own pricing decisions by tracking how real customers react, iterating toward an ideal pricing policy over time. The advantage of these advanced approaches is their ability to navigate highly complex or volatile markets. However, from a governance standpoint, it’s crucial to impose sensible guardrails. Otherwise, you risk fiascos like exponential price hikes for essential goods or near-instantaneous discounts that crater margins and damage brand equity.
When executed carefully, dynamic pricing can produce eye-catching gains in revenue and profit margin. A report from Boston Consulting Group noted that retailers embracing AI-driven pricing often see gross profit lifts of 5–10 percent, along with longer-term revenue growth (BCG). This is not an isolated success story. Walmart is said to use AI to adjust grocery prices in real time, balancing the need for competitiveness against the equally pressing need to protect margins (Grocery Doppio). Done right, the result is a nimble pricing strategy that flexes with demand curves instead of clinging to static “set it and forget it” price tags.
For high-demand or trendy products, dynamic pricing allows a retailer to capitalize on surging interest without having to do multiple manual repricings. When, for instance, a specific toy suddenly goes viral on social media, the dynamic pricing engine might nudge up the price by a small amount—within brand guidelines—to capture additional margin and avoid a total stockout. Conversely, for slow-moving inventory, the system might continuously discount items until they move. This means fewer end-of-season markdowns and less wasted stock. Over time, retailers may find they generate more consistent revenue streams because pricing is perpetually aligned with real demand rather than guesswork.
Although the strategic concept is straightforward, practical execution can be complex. It typically involves setting up a pricing center of excellence or a specialized team that oversees AI-based pricing tools, monitors competitor data, and enforces brand guidelines (BCG). This central oversight ensures dynamic pricing doesn’t devolve into chaotic price fluctuations that confuse or irritate customers. The team collaborates with IT to ensure data pipelines run smoothly. They work with merchandising to establish which items should be dynamically priced—some retailers choose to keep core staples at a stable price to preserve a perception of reliability—and they coordinate with marketing on promotional events.
In e-commerce environments, dynamic pricing is typically managed through software that integrates directly with the retailer’s online storefront, automatically updating prices as frequently as desired. Brick-and-mortar retailers, while more constrained, can still change prices daily (or even multiple times a day) if they have electronic shelf labels. Another crucial component is A/B testing. Retailers frequently test new pricing rules in certain regions or among a small subset of online users to gauge the impact before rolling out changes nationwide or sitewide. Through these experiments, pricing managers can see which strategies genuinely lift profitability or sales volume, and which inadvertently cause customers to bounce to competitors.
One of the biggest challenges in dynamic pricing is maintaining customer trust. If a customer sees the price of a product jump by 20% from one visit to the next without any obvious reason, they may question the retailer’s fairness. In some cases—particularly with large price hikes—outrage can go viral on social media, tarnishing brand perception. It’s a delicate dance. Retailers must draw clear boundaries around how much prices can fluctuate within a given timeframe or for a particular product. As a rule of thumb, retailers might set a modest maximum upward price adjustment to ensure customers aren’t blindsided.
There is also the question of fairness. Dynamic pricing strategies can, in theory, segment customers based on their browsing or purchasing history, offering different prices for the same product. Airlines do this all the time, but in retail, heavy-handed segmentation may trigger a backlash if customers perceive it as discriminatory. Some businesses have faced public scrutiny for charging higher prices to users shopping on premium devices or from affluent ZIP codes, even if the practice was intended to align with willingness to pay. The lesson is that brand image can be fragile, and dynamic pricing must never appear exploitative. The best strategies are those that pivot quickly to reflect real market conditions while preserving a reputation for transparency and fairness.
Despite the allure of higher profits, dynamic pricing is not immune to pitfalls. First is the risk of a “race to the bottom” if you rely too heavily on competitor data. If your AI constantly undercuts the lowest competitor price by a small margin, you might spark an endless cycle of price drops that shrinks margins for everyone involved. Another stumbling block is the complexity of interpreting demand signals. Does a drop in sales indicate that your price is too high, or could it be tied to external factors like a local weather event or a negative product review that went viral? Machine learning models are powerful but far from omniscient; they depend on high-quality, context-rich data.
Over-reliance on automation can also lead to bizarre outcomes. There have been cases where algorithmic pricing bots on online marketplaces created wildly inflated product listings because each bot was pegged to the other’s price, incrementally adjusting upward. At the same time, if you set the algorithm too aggressively to chase sales volume, you could end up with deep discounts that erode profit margins beyond recovery. Essentially, dynamic pricing algorithms do exactly what they’re instructed to do—so retailers must be extremely clear about the business rules and constraints baked into these systems.
Successful dynamic pricing initiatives hinge on a few key factors: executive support, a robust data infrastructure, skilled data scientists, and tight-knit collaboration across merchandising, marketing, and IT. Leaders need to evangelize the idea that prices should be fluid and that technology can make these decisions more effectively than human instincts alone. At the same time, they must emphasize the importance of brand integrity and customer experience. This means establishing guidelines for how quickly and how drastically prices can move, as well as ensuring that in-store staff understand the rationale behind dynamic pricing, so they can address customer questions or concerns.
Looking ahead, dynamic pricing is poised to grow more sophisticated. Real-time analytics, driven by streaming data, will allow retailers to change prices not just daily or hourly, but possibly minute by minute if the category demands it. The integration of personalization engines could create “micro-segments,” where each customer is offered a price reflective of both real-time demand patterns and individualized preferences. While that might sound like utopia for revenue managers, it also raises the stakes for transparency, fairness, and regulatory compliance. Nonetheless, dynamic pricing remains one of the most powerful levers in the modern retailer’s toolkit, offering a chance to boost margins, reduce waste, and stay agile in an increasingly volatile market.
7.5. Customer Segmentation & Behavioral Analytics
Not all customers are created equal, and in the retail world, that simple truth can be either a curse or an opportunity, depending on how it’s managed. The days of lumping every shopper into the same bland “general audience” category have given way to more intelligent, data-driven approaches. Customer segmentation is the practice of dividing a customer base into distinct groups that share common characteristics or behaviors. Historically, segmentation might have been as basic as labeling customers by age or annual income. The real game-changer happened when data scientists realized they could combine a variety of signals—transaction histories, promotion responses, online browsing habits, and more—to cluster customers in ways that yield tangible commercial benefits (Data Science in Retail: Use Cases & Insights, Year). Well-executed segmentation not only allows for targeted marketing, but it also paves the way for hyper-relevant product recommendations, personalized promotions, and an overall customer experience that feels almost eerily in tune with each individual’s preferences.
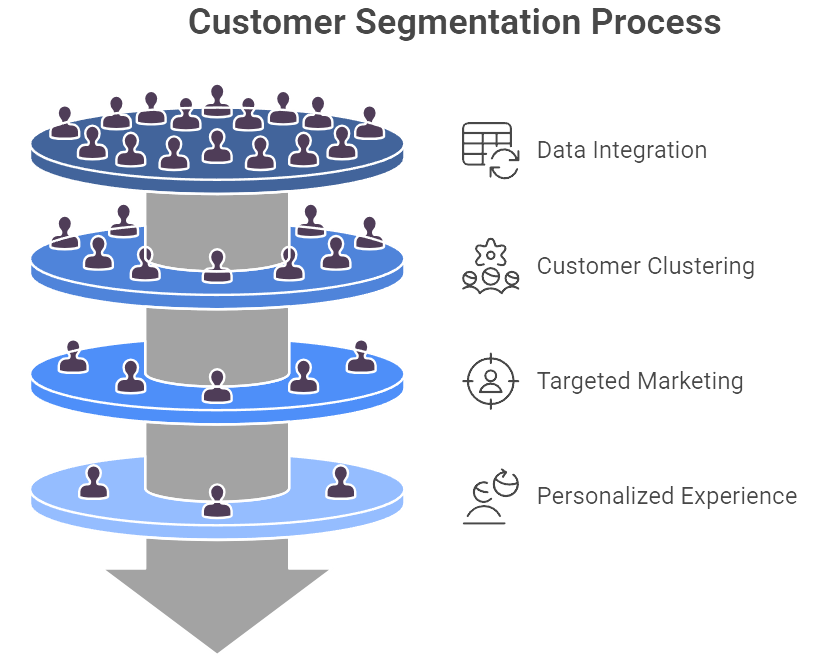
Figure 4: Illustration of the process of segmenting customers to enhance marketing effectiveness and customer satisfaction. (Image by Napkin).
A large body of research confirms that a relatively small percentage of customers tends to drive a disproportionately large slice of revenue—a phenomenon sometimes called the 80/20 rule, where roughly 20% of buyers account for 80% of sales (McKinsey, Year). By identifying who these top-tier customers are and what keeps them coming back, retailers can focus their marketing and service efforts where they matter most. Maybe these high-value customers crave the exclusive early access to new fashion lines. Maybe they’re enticed by VIP events or a next-level loyalty program. Whatever it is, you want to cater to them, because losing one of these individuals can hurt your bottom line more than losing a swarm of casual browsers. Conversely, segmentation can also reveal at-risk groups, such as customers whose once-frequent purchases have begun tapering off. Armed with that insight, retailers can target these groups with win-back campaigns—anything from a strategically timed discount to a personalized product suggestion that re-sparks their interest.
Beyond these revenue considerations, effective segmentation also underpins more refined messaging strategies, product assortments, and even store layouts. Segment insights can inform buying teams about which products to stock and in what quantities, ensuring that the merchandise reflects the preferences of profitable segments. For instance, a high-end electronics segment might warrant a deeper assortment of premium gadgets, while a bargain-focused group might need more space allocated to clearance or promotional bins. Executives who invest in robust segmentation initiatives often discover that it not only boosts revenue but can also reduce operational waste. If you know exactly which segments want which products, you’re less likely to overstock irrelevant items or squander marketing dollars chasing the wrong audiences.
The core concept behind behavioral analytics is fairly straightforward: identify patterns in how customers actually behave rather than how you assume they behave. This often begins with something as basic as recency, frequency, and monetary value (RFM analysis). A retailer might categorize customers based on how recently they’ve purchased, how frequently they shop, and how much they typically spend. RFM provides an easy-to-understand framework, but more advanced techniques—such as K-means clustering—can unearth more nuanced segments. For instance, you might discover a group that only buys children’s clothing when it’s on sale, or a segment that repeatedly purchases luxury items at full price the moment a new collection drops.
Increasingly, retailers are turning to predictive segmentation. Rather than simply describing historical behaviors, they forecast future patterns—like a customer’s likelihood to churn, or their propensity to respond to a particular type of offer (McKinsey, Year). These models can incorporate dozens or even hundreds of variables, from the time of day a customer typically shops to the types of product reviews they leave. Behavioral analytics can also track the “customer journey,” mapping how individuals progress from first-time buyers to brand advocates, or how they fall off after a disappointing interaction. Retailers then design automated triggers to intervene at critical points, say by sending a coupon to someone who’s recently had a negative experience but hasn’t yet defected to a competitor.
While the concepts of segmentation and behavioral analysis sound great in theory, they only deliver real value when integrated into day-to-day operations. Effective segmentation strategies typically involve feeding the segment data into CRM and marketing automation systems so that each group receives relevant offers, messages, or product recommendations. A new customer might be introduced to best-selling items or a guide to the retailer’s loyalty program, while a returning VIP might get an invitation to a private sale or early access to limited-edition products. In brick-and-mortar settings, segmentation can inform visual merchandising: store displays might be calibrated to highlight the products most appealing to each location’s dominant segments. Sales associates might even receive cues on a mobile device when a high-value customer walks in, prompting more personalized service—although this kind of personalization can stray into the “creepy” category if not handled transparently.
A practical example might involve a sporting goods retailer that identifies a niche “Outdoor Enthusiasts” segment buying camping gear at regular intervals. By targeting these enthusiasts with early-season previews, exclusive new product launches, or specialized how-to content (like backpacking tips), the retailer not only upsells higher-margin items but also fosters a sense of loyalty. Meanwhile, a “Casual Fitness” segment could benefit from more frequent promotions on affordable home workout gear or entry-level running shoes. The different approaches reflect the distinct motivations and purchasing habits within these segments. Over time, data analysts track the results, refine the segment definitions, and measure ROI, leading to a cycle of continuous improvement in marketing, merchandising, and overall customer experience.
One of the biggest challenges in segmentation is striking the balance between effective personalization and the looming possibility of data misuse. Customers generally appreciate being treated as individuals, but many bristle when retailers know a little too much about them. Collecting and analyzing customer data—particularly if it includes sensitive or personal information—requires robust governance frameworks and an explicit commitment to privacy. Retailers must also comply with regulations like GDPR in Europe or various state-level laws in the United States. Moreover, segmentation should never cross the line into biased or discriminatory practices. If certain segments inadvertently correlate with protected categories, you might be unwittingly engaging in differential treatment. This is where inclusive design and diverse data science teams become critical safeguards.
Another pitfall is letting segments become obsolete over time. A “new parents” segment, for instance, won’t stay that way forever. Similarly, a “college students” group might evolve into young professionals. Consumer behaviors and preferences shift, sometimes faster than the organization’s segmentation model can adapt. Regularly refreshing the segmentation—just like retraining a predictive model—keeps your insights aligned with real-world changes.
Though segmentation offers enormous potential, any CEO or CMO will tell you it’s more challenging than it looks. Deploying advanced analytics tools is one thing; embedding them into the corporate DNA is another. Top executives need to champion the idea that not all customers should be treated the same and that such differentiation isn’t an act of favoritism but rather a rational strategy to deliver precisely what each type of customer values. That mindset also requires close collaboration among data scientists, marketing teams, IT departments, and store operations. Marketers have to trust the data, and data scientists need to recognize the practical constraints of marketing budgets, brand guidelines, and consumer psychology. If these groups operate in silos, segmentation efforts will either stall or produce half-baked insights that never see the light of day.
Culture also plays a pivotal role in how segmentation outcomes are implemented. Frontline staff need to understand the rationale behind a new segmentation approach, lest they resist changes that feel arbitrary or complicated. Offering incentives and training can help them see how responding differently to different types of customers can elevate both sales and customer satisfaction. Some retailers even build cross-functional “customer insight teams” that continuously refine segmentation models and share findings across the company. These teams measure the financial impact of each segment-targeted campaign, bridging the gap between analytics and actual revenue.
As retailers accumulate more data from online interactions, social media, in-store sensors, and even mobile apps, segmentation is evolving to become more dynamic. Instead of categorizing customers on a monthly or quarterly cycle, advanced organizations are using real-time analytics to detect shifts in customer behavior almost as they occur. This could mean identifying “micro-moments” when a shopper transitions from casual browsing to purchase intent, triggering an immediate offer or recommendation that seals the deal. A spree of modern technologies—like streaming data pipelines and low-latency machine learning models—makes such “on-the-fly” segmentation possible. Of course, the boundary between predictive insight and invasive creepiness remains a delicate line. The key is to deploy these advanced tools in a way that genuinely enhances the customer experience rather than coming off as a brazen effort to squeeze every last dollar out of each transaction.
Customer segmentation and behavioral analytics have emerged as linchpins of any data-driven retail strategy. From rudimentary RFM scoring to sophisticated predictive modeling, these techniques illuminate why different customer groups act the way they do—and what can be done to steer that behavior in beneficial directions. The payoff is substantial: higher conversion rates, better resource allocation, and more personalized experiences that foster loyalty. At the executive level, it’s essential to understand that segmentation is not a one-and-done project but a continual process of listening, learning, and adjusting. When used responsibly and guided by sound leadership, segmentation can be a competitive differentiator, elevating a retailer’s profitability while also delivering genuine value to customers who appreciate being recognized for their unique preferences.
7.6. Case Studies
Real-world examples often provide the most compelling evidence of how data science principles translate into commercial success. From e-commerce giants that set the global standard in personalized recommendations, to fast-fashion retailers that slash inventory risk with near-instant feedback loops, these case studies demonstrate how theory becomes practice—and how practice drives profit. They also highlight the organizational and cultural shifts required to make data science a genuine strategic pillar, rather than a passing fad or merely a back-office function.
Amazon is perhaps the quintessential data science juggernaut in retail, a company that has transformed once-impossible concepts—like real-time pricing—into daily reality. One of Amazon’s most visible data-driven tactics is its recommendation engine, which greets customers at every turn. The familiar prompt, “Customers who bought X also bought Y,” is powered by collaborative filtering models that analyze billions of transactions, clickstreams, and product attributes (FACT-Finder, Year). The revenue impact of these recommendations is staggering: studies estimate that about 35% of Amazon’s total sales derive from these algorithmic nudges.
Yet personalization is just one side of the coin. Amazon also employs dynamic pricing on a scale that leaves competitors scrambling to keep up (Profitero, Year). Prices on popular items can change as frequently as every ten minutes, responding to real-time signals like competitor pricing, stock levels, and consumer demand. A price intelligence firm reported that Amazon makes over 2.5 million price adjustments daily (Profitero, Year). That might sound borderline chaotic, but it ensures Amazon is rarely caught off guard when demand surges for a trending toy or a must-have gadget. If stock depletes quickly, the system might nudge prices up to capitalize on demand—or reallocate more inventory if available—thus preventing out-of-stocks. The net result is a finely tuned balance between revenue maximization and customer satisfaction, at a speed few traditional retailers can match. The key takeaway is that data science—applied relentlessly—gives Amazon both a granular awareness of market shifts and an ability to respond in near-real time.
Walmart, the world’s largest retailer by revenue, demonstrates that data science is not the sole domain of digital natives. The company has long been an analytics pioneer, dating back to the days when it shared POS data with suppliers via its Retail Link system (Transights, Year). In recent years, Walmart has substantially upgraded its AI and big data initiatives to optimize forecasting, inventory management, and store operations. By integrating transaction logs, weather forecasts, social media data, and even local events, Walmart can predict demand at the store level with a level of precision that was once unthinkable. This improvement reportedly yielded a 16% reduction in stockouts and significant cuts in inventory costs (Transights, Year).
The ripple effects of better data-driven forecasting are wide-ranging. Warehouse operations become smoother, as staff and drivers no longer scramble in the dark to dispatch the right products at the right times. Trucks arrive loaded with just enough inventory to meet demand, reducing both overstock and stockouts. The same data-driven ethos extends to Walmart’s customer engagement strategies. Personalized product suggestions on Walmart’s mobile app and website harness the company’s massive data lakes. In one reported initiative, these customized promotions and product recommendations increased customer retention by 10% (Transights, Year). Walmart is also experimenting with sophisticated tools like AI-driven cameras to monitor produce quality and blockchain technology to trace food origins (Blockchain in the food supply chain - What does the future look like?, Year). In one pilot, the time to trace mangoes from farm to store shrank from over six days to just 2.2 seconds. The key takeaway here is that even a retail behemoth with a vast physical footprint can adopt a data-first culture, reaping benefits in both cost management and customer satisfaction.
Few industries exhibit the volatility of fashion, where consumer tastes can pivot faster than a runway model. Two companies illustrate distinct but equally successful applications of data science in this turbulent market.
Stitch Fix is an online personal styling service that built its entire business around algorithms. Customers begin with a detailed style quiz, providing data on everything from body dimensions to aesthetic preferences. Machine learning models, assisted by human stylists, then curate a personalized “Fix” of clothing and accessories. Over time, the system refines its recommendations based on keep-vs.-return data, user feedback, and changing style trends. This approach—melding AI-driven insights with human intuition—lets Stitch Fix scale personalized styling to millions of customers, a task that would be logistically impossible if done entirely by hand. The sheer volume of data on body shapes, style preferences, and individual feedback also guides product development, as Stitch Fix sometimes designs apparel in-house based on emerging trends detected by its algorithms.
Zara, on the other hand, leans into data science as the backbone of its celebrated “fast fashion” model. Each day, Zara’s stores worldwide send granular feedback on what is selling—and what is sitting idle—directly to HQ. That information informs design, production, and distribution decisions in near-real time, shrinking the gap between runway inspiration and store arrival to just a few weeks. If a new jacket sells out in Paris but gathers dust in Milan, Zara can reallocate stock accordingly. This data-driven agility keeps inventory lean, reducing the need for markdowns on unwanted items. Equally important, it ensures that the brand stays one step ahead of consumer demand, translating ephemeral trends into tangible products before the trend loses momentum. The key takeaway from fashion retail is that data can either serve to hyper-personalize (Stitch Fix) or to rapidly respond to and shape market trends (Zara). Both strategies aim to solve the sector’s perennial challenge of high markdown rates, but they do so by prioritizing data in entirely different ways.
Sephora offers a masterclass in unifying online and offline channels to create a seamless customer experience. Its Beauty Insider loyalty program boasts tens of millions of members (Sephora, Year), each generating valuable data across in-store purchases, website visits, and interactions with Sephora’s mobile app. By merging these data streams into a single 360-degree customer profile, Sephora ensures that whether a shopper is browsing eyeshadow palettes online or seeking product advice from a sales associate in-store, the experience feels consistent and tailored.
Technology plays a starring role in Sephora’s approach. The company’s app features augmented reality (AR) try-on tools so customers can virtually sample lipsticks or eyeshadows. Every virtual “try-on” generates data—like which shades are most commonly tested—helping Sephora anticipate inventory needs and design targeted promotions. In-store, staff can access a customer’s purchase history and preferences from a shared tablet interface, offering an elevated, personalized touch that might otherwise be reserved for boutique salons. The data loop becomes self-reinforcing: more interactions lead to more data, which leads to more precise personalization, which further increases engagement. Sephora is also experimenting with AI-based skin assessments (Skin IQ) that analyze skin tone or concerns and then recommend specific products. This multifaceted system has led to boosts in loyalty, with some marketing campaigns linked to Beauty Insider data significantly outperforming generic mass campaigns. The key takeaway is that an omnichannel strategy infused with data science can break down barriers between online and offline, resulting in a cohesive brand experience that wins customer loyalty and boosts sales.
Whether it’s Amazon fine-tuning prices in real time or Zara updating its racks at breakneck speed, these case studies illustrate how data science can catalyze commercial performance in radically different contexts. One universal insight is that success typically requires a holistic approach. Cutting-edge algorithms alone do not suffice; companies need cohesive data pipelines, a culture that trusts and acts on analytics, and thoughtful processes to translate insights into customer-centric actions. Equally important is the balance between automation and human expertise. Stitch Fix deploys AI to crunch the numbers but still relies on stylists for the final curation. Zara uses quantifiable sales data to guide decisions but also encourages store managers to input qualitative feedback on fashion trends. This blend of science and art, data and judgment, appears time and again in the most successful implementations.
There is also the evergreen issue of data quality and governance. Amazon and Walmart aren’t just good at using data; they’re equally skilled at collecting and organizing it at scale. Meanwhile, companies like Sephora have excelled at motivating customers to willingly share data by delivering tangible benefits in return—like personalized beauty recommendations and time-saving digital tools. These dynamics underscore a final point: companies that gain consumer trust and provide real value in exchange for data are the ones best positioned to thrive in this increasingly data-driven retail landscape.
7.7. Future Trends & Innovations
The pace of change in retail data science is anything but slow. Emerging technologies are converging to reshape how companies gather insights, engage customers, and optimize operations. While many of these trends build on themes already explored—such as personalization, supply chain transparency, and automation—they promise to take each to an entirely new level of sophistication. Below are some of the most prominent developments on the horizon and the strategic implications for business leaders who wish to harness them effectively.
Today’s personalization typically involves grouping customers into highly specific segments and tailoring marketing or product recommendations to each. The next step is individual-level personalization, or hyper-personalization, which leverages every shred of data available. Browsing context, current location, social media posts, recent purchases, and even local weather can be woven together in real time to deliver a deeply customized experience. If you walk into a store, a digital kiosk might greet you by name (having recognized your phone’s Bluetooth ID, for instance) and display curated offers reflecting your browsing history or most recent online purchases.
Industry forecasts suggest that by 2025, AI-driven assistants and chatbots could handle a substantial share of online transactions, offering a concierge-like experience to each shopper (Agentic AI, Year). Picture a chatbot that references your workout gear purchase last month and seamlessly suggests matching accessories, or a voice assistant that alerts you to a flash sale on a product you left in your online cart. Generative AI further expands these possibilities by automatically crafting individualized marketing content, from emails that reference your last purchase to real-time ads based on your immediate interests. Such capabilities pose both tremendous revenue opportunities and serious privacy questions. The line between “pleasantly relevant” and “uncomfortably invasive” is thin and can shift quickly, so brands pursuing hyper-personalization must handle data responsibly and transparently.
Blockchain technology has moved beyond the realm of cryptocurrencies into areas where transparency, trust, and traceability are paramount. Retail supply chains, rife with opportunities for inefficiency and fraud, stand to benefit considerably. Leading retailers have already trialed blockchain-based solutions to track produce from farm to store, enabling near-instant recall and verification of product origin (Blockchain in the food supply chain - What does the future look like?, Year). In the fashion sector, blockchain can confirm whether a garment is made from ethically sourced materials, guarding against counterfeits and boosting consumer confidence.
Future blockchain implementations could see entire industry consortia collaborating on shared digital ledgers. A clothing retailer might record every step of production—from cotton harvesting to final store delivery—so customers or regulators can trace it back at a glance. Smart contracts could automate payments once deliveries are confirmed, slashing paperwork and accelerating workflow. While interoperability and the lack of industry-wide standards remain hurdles, momentum is building. Blockchain adoption not only aids compliance but also offers a point of differentiation: a brand that can prove the provenance and sustainability of its products may hold a competitive edge with increasingly conscientious consumers.
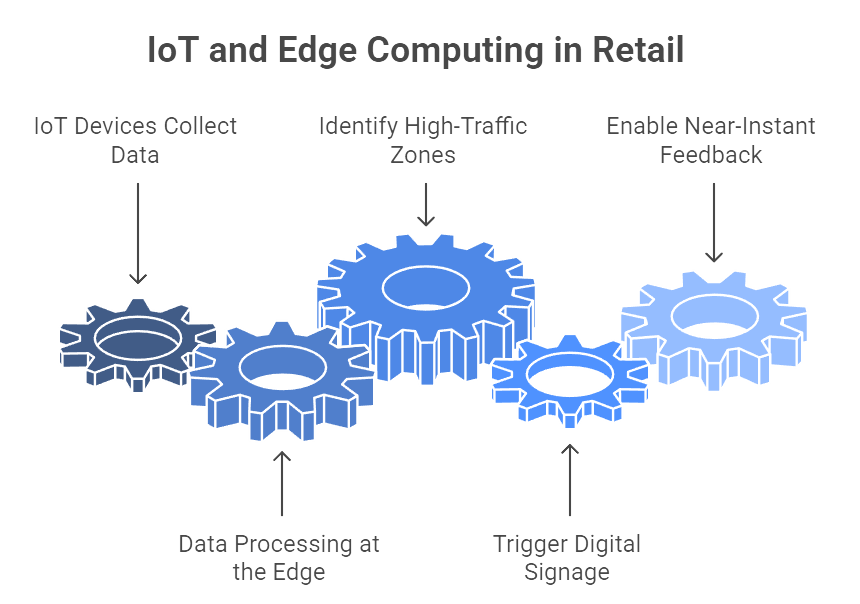
Figure 5: Illustration of how IoT and edge computing are utilized in retail, from data collection to triggering digital signage. (Image by Napkin).
The Internet of Things (IoT) is steadily infiltrating every corner of the retail ecosystem. Shelf sensors, weight scales, RFID tags, and smart beacons can collectively generate staggering volumes of real-time data, revealing detailed patterns of store traffic, inventory levels, and product movement. Managing and processing this data in real time requires robust infrastructure, which is why edge computing—processing data locally rather than in distant cloud servers—will become increasingly integral. In a smart store, for example, a network of cameras might identify high-traffic zones and prompt dynamic digital signage to display relevant promotions. Because these adjustments must happen in seconds, pushing all data to the cloud for processing isn’t always feasible. Edge computing solves that latency issue, enabling near-instant feedback loops.
As 5G and next-generation wireless networks roll out, the number of devices that can be simultaneously connected in a single store will skyrocket, opening the door for even more sophisticated real-time analytics. From automated checkouts that detect which items a customer picks up, to refrigerated units that track expiration dates, IoT devices can autonomously trigger restock alerts, re-route deliveries, or even adjust pricing based on stock levels. The result is an environment where operational decisions—from which products to spotlight to how many staff should be on duty—are driven by live data rather than monthly or quarterly snapshots. Of course, the flipside is a heightened focus on cybersecurity, as every device in the network can become a potential entry point for attackers if not properly managed.
In the near future, advanced analytics won’t just inform tactical decisions like pricing or stocking; it will also play a more prominent role in strategic planning. Machine learning models and AI-powered simulations can help executives evaluate large-scale decisions—expanding into a new region, launching a new product line, or switching from brick-and-mortar to hybrid omnichannel models. These tools can aggregate historical data, market research, and real-time signals to project outcomes with surprising accuracy.
Such decision-augmentation might also include voice interfaces, wherein an executive can simply ask, “How did our East Coast campaign perform last weekend, and are there any anomalies I need to know about?” The AI, integrated with all pertinent data sources, could provide a concise, context-rich response. Similarly, visual analytics platforms enhanced by AI could allow leaders to manipulate variables—like promotional budgets or merchandising mix—and immediately see predicted impacts on sales, inventory turns, or customer satisfaction. The goal is to empower human decision-makers with machine-calculated foresight, not to replace their judgment entirely. Striking that balance between AI-led automation and essential human intuition remains a critical cultural challenge.
While still in early stages, augmented reality (AR), virtual reality (VR), and mixed reality (MR) hold promise for transforming how consumers interact with products. Retailers like Sephora have already deployed AR try-on tools, and fashion brands are experimenting with virtual showrooms. Looking ahead, the concept of a “metaverse”—a shared virtual space—could allow retailers to build entire digital storefronts where customers browse, try on digital versions of products, and then place orders for real-world delivery. AI will be crucial in curating these experiences, ensuring that each user sees products relevant to them and can receive real-time, AI-driven styling advice or product recommendations.
Retailers that seize these immersive channels may find new avenues for engagement, particularly among younger consumers who grew up interacting with digital avatars in gaming environments. On the operations side, immersive technologies could facilitate virtual training for store associates or even remote collaboration between designers and suppliers. The technical and financial barriers to widespread adoption remain non-trivial, but those who innovate early may gain a brand distinction that’s hard to replicate.
The future of data science in retail centers on amplifying two pillars: personalization and operational efficiency. These new technologies—hyper-personalized AI, blockchain, IoT, edge computing, and immersive experiences—all advance one or both of those goals. Yet they also introduce new complexities, whether legal (managing privacy and data rights), technical (integrating a surge of IoT devices), or cultural (ensuring the human element remains at the forefront). The chief executives of tomorrow will need a solid grasp of how these trends reshape both consumer expectations and organizational capabilities. As AI and analytics become even more pervasive, leadership will revolve around orchestrating the interplay between automation and human insight, ensuring that the brand’s identity and ethical stance remain uncompromised in the pursuit of innovation. Those who manage this balancing act successfully will emerge as the retail powerhouses of the next decade.
7.8. Conclusion and Further Learning
Data science has unequivocally become a driving force in retail, powering both the front-end customer experience and back-end operations. Through the course of this chapter, we saw how personalization and operational efficiency act as two pillars supported by analytics and AI. Retailers employing recommendation engines and customer analytics are crafting personalized journeys that delight customers and foster loyalty. Simultaneously, those leveraging predictive models for demand forecasting, dynamic pricing algorithms, and optimization techniques in their supply chain are achieving levels of efficiency that reduce costs and improve agility. Several key takeaways for business executives emerge:
Customer-centric data science pays off: Personalization isn’t just about making customers feel special; it has direct financial impact in higher conversion rates, bigger basket sizes, and longer customer lifetime value. The numbers are compelling – from 40% revenue boosts among personalization leaders to vastly higher growth for companies using behavioral insights. Investing in AI that improves customer engagement (recommendation systems, segmentation, loyalty analytics) is investing in sustainable growth.
Efficiency and agility through AI are competitive necessities: Markets change fast, and retailers must respond quickly to demand shifts, supply disruptions, or new trends. Data science tools like ML forecasting, dynamic pricing, and optimized logistics algorithms give retailers the agility to react in near-real time. This means fewer missed sales due to stockouts, less money tied in excess inventory, and pricing that stays sharp against competition. The case studies of Walmart, Amazon, and Zara exemplify how data-driven decisions can make operations both cost-effective and customer-responsive.
Integrated strategy is key: The full value of data science is realized when insights flow across the organization. Personalization efforts can inform product assortment (if data shows a new trend, the buying team should know). Demand forecasts should feed into marketing promotions (if we predict low demand next month, perhaps a campaign can lift it). A siloed approach will limit benefits. Executives should champion a culture where data is shared and cross-functional teams collaborate around data insights – essentially creating a data-driven organization. Additionally, having a solid data infrastructure (clean data, modern data platforms, and the right analytics tools) is foundational.
Future readiness: Emerging trends like hyper-personalization, IoT, and blockchain will likely raise consumer expectations for personalization and transparency, while offering new ways to streamline operations. Business leaders should keep an eye on these innovations, running pilots where appropriate. For example, exploring a blockchain traceability project or an AI chatbot for customer service can position a retailer as an early mover with valuable learnings. Importantly, with greater power of data comes greater responsibility – issues of data privacy, security, and ethical AI use must be top of mind to maintain customer trust and comply with regulations.
In conclusion, data science in retail is about leveraging data to make smarter decisions, faster – always with the twin goals of better serving the customer and improving operational outcomes. The cases and concepts discussed show that when executed well, data-driven personalization and efficiency are mutually reinforcing. Satisfied, engaged customers generate more data and more demand; efficient operations fulfill that demand in a profitable way, allowing further investment in customer experience. This virtuous cycle is at the heart of modern retail success. As the industry evolves, the retailers who thrive will be those who view data science not as a tech project, but as a strategic business capability woven into every facet of their organization.
The journey to become a data-driven retail organization is ongoing, but the destination – a business that can delight each customer individually while operating like a well-tuned machine – is well worth the effort. As W. Edwards Deming famously said, “In God we trust; all others must bring data.” In retail’s competitive battleground, bringing data – and using it wisely – is what will separate the winners from the rest.
To deepen understanding and spark strategic thinking, consider the following discussion questions and prompts:
Balancing Personalization and Privacy: How can retailers balance hyper-personalization with consumer privacy concerns and data protection regulations (like GDPR)? Discuss strategies for personalization that respect privacy, such as opt-in programs or anonymized data analytics.
ROI of Data Science Projects: What key performance indicators (KPIs) should a retail executive look at to measure the success of a data science initiative (be it a recommendation engine or an inventory optimization tool)? Consider metrics across customer experience, revenue, and cost savings.
Omnichannel Data Integration: In an omnichannel retail model, what are the challenges of integrating data from online and offline channels? Explore methods to create a unified customer view and how that enables better service (e.g., buy-online-pickup-in-store optimization).
Case Study – Failed Implementation: Can you think of or find examples where a data science initiative in retail failed to deliver expected results? What went wrong (e.g., poor data quality, lack of user adoption, algorithm bias)? Discuss lessons learned.
Ethical AI in Retail: Should retailers ever not use certain data (like very personal data points) even if it could improve personalization? Debate the ethical boundaries of using AI in retail, for instance, using AI to profile customers’ financial status or health-related information for marketing.
Customer Segmentation Brainstorm: How might a retailer segment its customers beyond obvious categories? For a retail sub-sector (fashion, electronics, grocery), brainstorm creative segmentation criteria (perhaps based on lifestyle, engagement level, or channel preference) and how those segments could be targeted differently.
AI vs Human Touch: As AI recommendation engines and chatbots become prevalent, how important is the human element in retail going forward? Discuss scenarios where human intuition or service adds value on top of AI, and how retailers can blend the two for optimal results.
Dynamic Pricing Perception: Dynamic pricing can sometimes upset customers (e.g., if they notice price changes or feel treated unfairly). What practices can retailers adopt to implement dynamic pricing without damaging customer trust? (Think about transparency, price guarantees, loyalty member benefits, etc.)
Supply Chain Risk Analytics: With global supply chains facing disruptions (pandemics, geopolitical issues), how can data science help in risk mitigation? Discuss the use of predictive analytics for supply chain risk (like forecasting potential supplier delays or shifts in transportation costs) and contingency planning.
AI in Merchandising Decisions: In fashion or electronics, trends change quickly. How could AI assist merchants or buyers in deciding what new products to stock? Consider data sources like social media, search trends, or even AI-generated design.
Personalization in Physical Stores: We know e-commerce excels at personalization, but how can brick-and-mortar stores deliver personalized experiences using data? Discuss current or future technologies (clienteling apps, in-store sensors, AR mirrors) that enable personalization in-store, and the data challenges involved.
Scaling Data Science in Retail: For a mid-sized retailer beginning its data journey, what should be the first few data science projects to tackle? Debate priorities – is it better to start with customer-facing analytics (marketing personalization) or operational analytics (inventory optimization) and why?
IoT Data Explosion: Imagine a future store with hundreds of IoT devices (cameras, beacons, smart shelves). What new analytics opportunities does this open? For example, discuss how foot traffic heatmaps, dwell time in aisles, or even sensor-detected customer mood (happy, frustrated) could inform retail decisions in real time.
Cross-industry Learning: Retail isn’t the only sector using data science. What can retail learn from other industries (like finance or healthcare) about using AI effectively? Conversely, is there something unique about retail data (e.g., high volume of customer transactions) that leads to unique approaches?
Data Visualization for Retail Ops: If you were to design a dashboard for a retail executive, what would you include to give a daily pulse of personalization and operational efficiency? Consider what real-time visuals (maps of inventory, funnel of customer segments, etc.) would help spot issues or opportunities quickly.
AI Adoption Challenges: Discuss the main barriers to adopting AI in a retail organization. Consider factors like legacy IT systems, talent gaps (data scientists in a traditionally non-tech company), change management for store employees, and cost. How might these be overcome?
Future of Physical Retail: With data and AI making online retail highly optimized, what is the future role of physical stores? Explore concepts like experience centers, showrooms, or fulfillment hubs – supported by data insights – as new retail formats.
Loyalty Programs and Data: Loyalty programs are rich data sources. How can retailers modernize their loyalty programs using AI? For example, discuss individualized rewards, predictive churn scoring (identifying which loyalty customers might leave and intervening), and tying loyalty data with personalization engines.
Edge Computing Use Case: Consider a specific edge computing scenario in retail (for instance, a convenience store chain implementing smart checkout or a warehouse using on-premise AI for real-time sorting). What are the benefits and potential pitfalls of doing computing at the edge in that scenario?
KPI Trade-offs: Sometimes efficiency and customer experience can conflict (e.g., reducing inventory might risk stockouts). Discuss how data science can help find the right balance. Can AI-driven simulations or multi-objective optimizations assist in balancing cost vs service? Encourage thinking about trade-off metrics (for example, fill rate vs inventory carrying cost) and how leadership might decide on an acceptable balance using data.
These prompts encourage exploring the strategic, technical, and ethical dimensions of data science in retail, and should stimulate robust discussions or research projects for readers looking to deepen their mastery of the subject.
To translate concepts into practice, here are five exercises with objectives and guidance. These assignments are designed to be accessible to business professionals (some may require analytical thinking or simple use of tools like spreadsheets, but not heavy coding) and will reinforce the chapter’s learnings through real-world application.
🛠️ Assignments
📝 Assignment 1: Customer Persona Development from Data
🎯 Objective:
Create data-driven customer personas for a retail business by analyzing a sample customer dataset. This will help in understanding segmentation and personalization at a practical level.
💡 Guidance:
Imagine you have access to a dataset of customers with attributes like age, gender, total annual spend, number of purchases, favorite product categories, and whether they use online or in-store channels. (If actual data is not available, you can fabricate a small sample for this exercise.) Using this data, segment the customers into 3–5 personas. For each persona, summarize key characteristics (e.g., “Budget-minded Busy Parents: mid-30s, shop mainly in-store for groceries, responsive to discounts, moderate annual spend”). You can use simple tools: for example, sort and filter the data to find patterns, or use Excel’s pivot tables to see clusters (like age vs spend, or category preferences by group). The deliverable is a brief description of each persona and what marketing or service strategies you would recommend for each. This exercise reinforces how segmentation works and how raw data translates into actionable profiles.
📝 Assignment 2: Market Basket Analysis
🎯 Objective:
Perform a basic market basket analysis to discover product affinities, simulating how recommendation engines suggest complementary products.
💡 Guidance:
Take a sample of transactional data (or create one) with transactions and the items purchased in each transaction (for instance, Order 1001: items A, B, C; Order 1002: items A, D; etc.). Using either manual inspection or a simple association analysis, identify which products are frequently bought together. For instance, you might find that in 30% of purchases where “Coffee Maker” is bought, “Coffee Beans” are also bought. List 3–5 strong associations (“rules”) you discover (e.g., IF customer buys X, they often buy Y). Then, translate these into recommendation ideas (e.g., recommend Y on the website whenever someone views X). You can do this by tallying co-occurrences of items. More advanced (optional): use a spreadsheet or an analytics add-on to calculate support and confidence of association rules. The outcome will mimic the logic behind Amazon’s “Frequently Bought Together” suggestions and solidify understanding of collaborative filtering concepts.
📝 Assignment 3: Demand Forecasting Simulation
🎯 Objective:
Experience demand forecasting by building a simple predictive model (even a basic linear trend or moving average) and comparing it to actual outcomes.
💡 Guidance:
Take historical sales data for a product (e.g., last 24 months of monthly sales for item X – you can assume some trend or seasonality and create a small table of values). Using that data, forecast the next 3 months’ sales. You could use a simple method like: average of last 3 months (moving average), or same month last year adjusted by overall growth rate, or even just a linear projection if there’s a clear upward trend. Document your method and rationale. Now, assume some “actual” sales for those 3 months (perhaps inject a surprise event like a stockout or a big promotion in one month) and see how your forecast would have performed (calculate forecast error%). Write a short reflection on what might improve the forecast (e.g., “If I had known about the promotion in advance, I’d have adjusted July’s forecast up.”). This exercise helps you appreciate the variables that go into forecasting and the challenges forecasters face, linking back to why AI models (which can consider promotions, seasonality, etc.) are valuable.
📝 Assignment 4: Pricing Strategy Game
🎯 Objective:
Develop a simple dynamic pricing strategy for a product and simulate its effect on sales and profit, illustrating the concepts of price elasticity and competitor influence.
💡 Guidance:
Choose a hypothetical product (say a winter coat) and define a baseline scenario: price = $100, and at that price, weekly sales are 100 units. Now imagine a competitor reduces their price; how might you respond? Create a small scenario analysis: If you drop price to $90, perhaps you expect sales to rise to 120 units (considering elasticity). At $80, maybe sales go to 140 units. Calculate revenue and perhaps profit (assume a cost per coat, say $50). Compare scenarios: $100 \ 100 vs $90 \ 120 vs $80 \* 140 in revenue (and similarly profit after cost). Which yields the best outcome? Also consider an opposite scenario: strong demand allows raising price – what happens at $110 with maybe 90 units sold? This “game” can be done in a spreadsheet. The goal is to see dynamic pricing in action and understand diminishing returns or sweet spots. Document your assumptions about how demand changes with price (that’s effectively an elasticity assumption). Write a brief recommendation based on your findings (e.g., “Our analysis suggests dropping price to $90 could increase total profits, but going to $80 starts to erode profit margins. A dynamic pricing strategy could float our price around $90–$100 depending on inventory levels and competitor moves.”). This practical task ties together concepts of pricing, elasticity, and competitive dynamics.
📝 Assignment 5: Store Efficiency Audit
🎯 Objective:
Conduct a mini operational efficiency audit for a retail store (this can be theoretical), identifying areas where data science tools could improve performance.
💡 Guidance:
Think of a physical retail store environment (it could be a clothing store or a supermarket). List the main operational processes: inventory ordering, shelf replenishment, staff scheduling, checkout process, etc. For each, ask questions or gather simple data via observation (or assumption). For example: How often do popular items run out on shelves? Are there times when checkout lines get long? Do employees seem under-utilized at certain hours? Then, for at least 2 of these issues, propose a data-science solution. E.g., “Observed that shelves go empty for Item X by 4pm daily – a data-driven replenishment system could predict this and alert staff at 3:30pm to refill from the backroom,” or “Noticed long lines at 6pm – suggest implementing an analytics tool like Kroger’s which predicts and opens new registers preemptively.” If you have access to any store data (even sales by hour), use it to back up your observations. The deliverable is a short report or presentation outlining the inefficiencies and the potential AI/analytics solutions (like forecasting, IoT sensors, scheduling optimization). This assignment makes you step into the shoes of an operations manager and see how data and analytics can solve day-to-day retail challenges, reinforcing the value of operational efficiency initiatives.
Each of these assignments is designed to be approachable but insightful. By completing them, a business professional or student will gain practical intuition: segmenting customers and crafting personas, seeing how product associations lead to recommendations, grappling with forecasting variability, experimenting with pricing outcomes, and spotting efficiency gaps in operations. These hands-on exercises translate the chapter’s concepts into real-world decision-making scenarios, solidifying the reader’s ability to apply data science thinking in a retail context.
Comments