Chapter 9
Data Science in FMCG – Market Trends and Supply Chain Intelligence
"The goal is to turn data into information, and information into insight." — Carly Fiorina
Data science is revolutionizing the Fast-Moving Consumer Goods sector by enabling companies to make smarter, faster decisions across their business. This chapter explores how FMCG firms use analytics and AI for real-time market trend identification, precise demand forecasting, and deep consumer behavior insights to drive personalization. It highlights how supply chains are optimized through predictive planning and automation, and how data-driven strategies are guiding product innovation and more targeted marketing campaigns. Practical case studies – from Coca-Cola’s use of data to create new flavors to Unilever’s AI-powered supply chain improvements – illustrate tangible benefits. The chapter also addresses the challenges of this data-driven transformation, including data privacy, regulatory compliance, and ensuring ethical, unbiased AI. Looking to the future, it discusses emerging technologies like IoT and blockchain for supply chain transparency and paints a picture of an FMCG industry where data intelligence is integral to staying competitive, fostering innovation, and building trusted consumer relationships.
9.1. Introduction to Data Science in FMCG
Data science has rapidly evolved from a vague buzzword into a key strategic lever for Fast-Moving Consumer Goods (FMCG) companies. At its core, data science merges statistical methods, computational techniques, and domain expertise to make sense of massive datasets and fuel data-driven decisions. Within the FMCG sector, these decisions touch every conceivable part of the value chain—from concepting new products to refining logistics for last-mile delivery. The thrill of extracting actionable insights from gigabytes of sales data, social media chatter, and supply chain logs is undeniable. Yet, the process is neither quick nor painless. When successfully implemented, data science initiatives enable FMCG firms to stand out in a cut-throat market through targeted marketing, demand forecasting, personalized customer engagement, and more efficient operations (Polestar Solutions). The message is clear for any executive who prefers not to hemorrhage market share: data-driven decision-making is no longer an optional “nice to have”; it is a vital component of modern corporate strategy.
However, adopting data science effectively requires more than a few shiny dashboards. It demands a top-down commitment to analytics culture, cross-functional collaboration, and enough technological backbone to handle everything from advanced machine learning to real-time insights. This section delves into the essentials of data science for FMCG, examining not just the “what” of algorithms and platforms, but also the “why” and the “how” of applying these tools in a real-world commercial setting. For those with an appetite for blunt truths: yes, data science can work wonders, but it can also be a resource-hungry black hole if your organization is unprepared. The pages ahead will explore both sides of that coin, offering a comprehensive overview for novices seeking an introduction and for industry veterans who crave deeper strategic insights.
Executives and business leaders in FMCG who have been around the block understand one reality: consumer preferences shift at a pace that can feel disturbingly unpredictable. One moment, a quirky flavor of chips or soda suddenly goes viral; the next, it is tossed aside for the next big thing that sweeps social platforms. A robust data science capability allows firms not only to track these changes as they happen, but to predict them with enough advance warning to optimize product mixes, promotional campaigns, and supply chain configurations (Polestar Solutions). The results can be tangible and rapid—reduced waste, increased revenue, better on-shelf availability, and a swifter response to competitive threats. Firms that master this agility often see the kind of top-line growth and operational efficiency that becomes the envy of their more reactive peers.
Still, let us not pretend the path is all roses. Data silos are endemic to large organizations, and the FMCG sector is no exception (Polestar Solutions). One division jealously guards its consumer research logs, while another stores supply chain records in archaic systems that date back to a time when “digital” referred mostly to watches. The result is messy integration work that can quickly derail well-intentioned analytics projects. Legacy IT infrastructure compounds the problem, making it complex to stitch in new AI platforms with existing ERP or CRM systems (Polestar Solutions). Cultural inertia often does the rest, as frontline staff and even some managers resist the notion that algorithms might—gasp—offer better predictive accuracy than gut instinct. Executives who have tried pushing analytics through these obstacles know it can feel a bit like herding cats, only with million-dollar budgets on the line.
Despite these headaches, many large consumer goods companies have managed to emerge victorious. One global FMCG leader famously leveraged predictive analytics to improve its demand forecasting by analyzing historical sales, market trends, promotions, and seasonal shifts. The result was a 15% boost in forecast accuracy, delivering fewer stock-outs, less overstock, and a dramatic improvement in overall service levels (Polestar Solutions). Another global brand employed advanced machine learning to sift through social media chatter—scraping platforms for comments that might hint at consumer sentiment around new product flavors. By correlating those sentiments with real-time sales data, the company preempted a costly product failure and even discovered a new flavor combination that swiftly became a category bestseller (Provost and Fawcett, 2013 would fit well here). These achievements underline a simple fact: done right, data science can propel business outcomes in ways that make even the most cynical CFO smile.
Understanding the full promise of data science begins with clarity on its foundational elements. Data science is the discipline that uses scientific methods—statistics, mathematics, computer programming, and domain knowledge—to uncover insights from structured and unstructured data. Within this broad domain lie crucial subfields such as machine learning, which involves training algorithms on historical data so they can identify patterns and make predictions. Machine learning branches into supervised learning (where labeled examples guide the algorithm), unsupervised learning (where the algorithm seeks hidden structures in unlabeled data), and reinforcement learning (where algorithms learn through trial and error in dynamic environments). In recent years, deep learning has also risen to prominence, utilizing multi-layered neural networks that mimic the human brain’s structure to tackle complex problems like image recognition and natural language understanding.
Yet, superior algorithms mean little without properly curated data. FMCG firms often house terabytes of point-of-sale information, transactional data, and consumer feedback. At first glance, such volume might seem like a goldmine, but quantity can be a curse if data is riddled with errors, duplications, or missing fields. Data cleaning and integration—often relegated to the background as the “boring part” of data science—are in fact critical to extracting any serious value. If you enjoy writing blank checks for avoidable fiascos, feel free to dismiss these painstaking processes. Otherwise, an upfront investment in data quality is non-negotiable for any high-stakes analytics endeavor (Davenport and Harris, 2017 would fit well here).
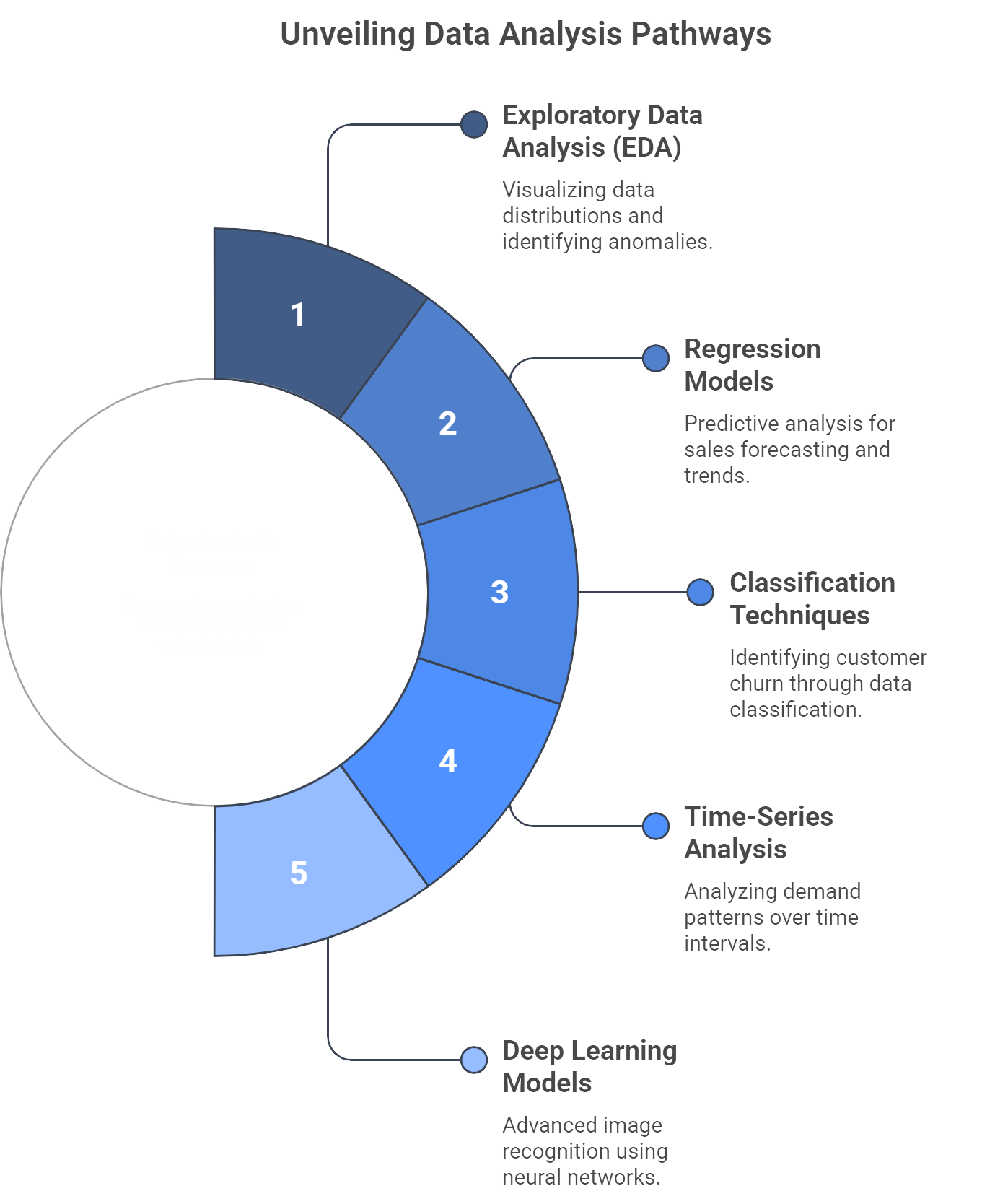
Figure 1: Illustration of a structured approach to data analysis, covering topics from exploratory data analysis to advanced deep learning models. (Image by Napkin).
Once data is collected and cleaned, exploratory data analysis (EDA) takes center stage. This involves visualizing data distributions, identifying outliers, and uncovering hidden relationships. EDA lays the groundwork for subsequent modeling by ensuring the data is well-understood and that any anomalies or biases are discovered early. Think of this step as a security checkpoint that can save your team from boarding a flight with the wrong luggage. After EDA, the modeling phase begins. FMCG companies typically employ regression models for sales forecasting, classification techniques for churn prediction, and time-series analysis for demand planning. More advanced shops may incorporate deep learning models to tackle intricate challenges such as image-based product recognition on retail shelves. Regardless of the model type, rigorous evaluation against test datasets is essential. No executive wants to bet the bottom line on a model that looks great in a sandbox but fails miserably in the real world.
FMCG professionals often operate with razor-thin margins and intense competition, making real-time analytics a powerful game-changer. Instead of receiving sales data days or weeks later, companies can now monitor performance at the store or distribution-center level in near real time (Polestar Solutions). For an executive wanting immediate feedback on whether a newly launched product is a flop or a home run, this instant visibility can be downright addictive. But with great power comes great responsibility: real-time analytics can also amplify the damage if flawed models or biased algorithms feed rapid-fire decisions. For instance, a miscalibrated model might jack up prices at the wrong moment, triggering a social media backlash that dwarfs the initial gains. FMCG leaders, therefore, must tread the line between agility and prudence, ensuring that data-driven decisions are tempered by expert domain knowledge and robust ethical guidelines (Polestar Solutions).
AI ethics becomes even more pressing when personalizing offers or analyzing consumer behavior. Gathering consumer data is no longer just about scanning loyalty cards at the checkout; it can involve facial recognition in stores, location tracking via mobile apps, and extensive social media monitoring. Regulators and the public alike are paying closer attention to how companies use such data. If organizations overstep, they risk reputational damage and potential legal consequences. The FMCG industry, which relies heavily on consumer trust, cannot afford to be cavalier. Treat data privacy and responsible AI use as cornerstones of your strategy, or brace for an unwelcome spotlight that can unravel years of brand building (Polestar Solutions).
Achieving a seamless integration of data science within an FMCG organization’s broader commercial strategy demands more than simply recruiting a data science team and crossing your fingers. It starts with leadership alignment. When top executives champion analytics-driven transformations, it sends a clear message across the firm that data is no longer an afterthought, but a strategic asset. From there, cross-functional collaboration is essential. Effective data science involves input from multiple stakeholders—IT teams manage the technical aspects of data storage and security, domain experts bring nuanced knowledge of FMCG operations, and data scientists orchestrate the analytical techniques. Regular communication, shared goals, and transparent processes help break down the dreaded data silos that impede progress.
Simultaneously, establishing the right infrastructure is critical. This often means modernizing legacy systems or migrating certain processes to the cloud to benefit from scalable storage and compute capabilities (Polestar Solutions). While the initial investment may sting, especially when CFOs see the price tag for enterprise-level platforms, the long-term payoff in agility and performance often justifies the cost. It also lays the groundwork for advanced analytics and AI, equipping the company to handle future data demands rather than merely playing catch-up. Once the infrastructure is in place, iterative experimentation becomes a cornerstone of success. Data science thrives on rapid prototyping, continuous feedback loops, and frequent model recalibrations to keep pace with shifting market realities. This is not just an IT exercise; it is a fundamental shift in how decisions are made across marketing, product development, operations, and beyond.
Of course, all these endeavors will crumble if the broader corporate culture is not ready. Data literacy programs can help bridge the knowledge gap. Executives might discover they enjoy deciphering the difference between a regression coefficient and a random forest once they see how these concepts link directly to cost savings or market expansion. Similarly, demystifying machine learning for non-technical teams builds trust and reduces the likelihood of sabotage by middle managers worried about job security. Organizations that fail to invest in cultural shifts risk having sophisticated analytics outputs gather dust—ignored by front-line teams who do not see the relevance or resent the perceived intrusion into their turf (Polestar Solutions).
Coca-Cola, renowned for its marketing prowess, has used data science to fine-tune product innovation, leveraging advanced analytics on consumer feedback and point-of-sale data to predict which new beverage flavors are likely to resonate. Unilever, another FMCG giant, has streamlined its supply chain with machine learning algorithms that optimize route planning and inventory management, reducing lead times and cutting transportation costs. Both cases exemplify how data science, implemented with strategic clarity, becomes a competitive weapon rather than an expensive experiment (Polestar Solutions). From a commercial standpoint, these initiatives do not merely boost efficiency; they can also inform brand positioning and direct investments that shape the company’s future direction.
Data science stands at the nexus of opportunity and risk for FMCG organizations. On one hand, the potential benefits—improved demand forecasting, targeted marketing, real-time analytics, and innovative product development—can propel a company to market leadership. On the other, a cavalier or disorganized approach can eat up budgets, frustrate employees, and alienate consumers who increasingly demand ethical data use. Navigating these challenges requires a holistic strategy that marries technical expertise with savvy leadership, cultural readiness, and a willingness to adapt. For executives looking to future-proof their FMCG business, there is really no alternative but to embrace the rigorous, sometimes unglamorous work of data collection, cleaning, analysis, and deployment. Do it properly, and you will unlock insights that keep your organization a step ahead of the next consumer fad—or at least prevent you from blindly chasing it. In an industry where trends can turn on a dime, such preparedness is not just a strategic advantage; it is a lifeline.
9.2. Real-Time Market Analysis and Predictive Intelligence
Staying ahead of market shifts in the FMCG industry can feel like chasing a hyperactive hummingbird: consumer preferences flutter about with dizzying speed, social media chatter rises and falls by the hour, and competitor pricing strategies shift almost as fast as you can say “dynamic discount.” This is where real-time market analysis swoops in to save the day. Rather than fumbling with spreadsheets full of stale, days-old data, FMCG firms can monitor a live stream of sales transactions, social media mentions, search trends, and even competitor price changes. The aim is to catch emerging patterns and respond while they are still relevant. After all, if you are only finding out about a viral product trend weeks later, you might as well send the “wish you were here” postcard from lost market-share island.
Real-time market analysis provides up-to-the-minute insights that can impact branding, distribution, and promotional decisions. Beverage companies, for example, track social platforms to see which new flavors are generating buzz, occasionally stumbling upon perplexingly popular concoctions that spark their next product launch. Coca-Cola discovered that its brand was mentioned online roughly once every two seconds—a statistic that would terrify some companies but presented Coca-Cola with a goldmine of consumer data (Digital Innovation and Transformation). By applying AI-driven image recognition, the company can identify when and where photos of its drinks appear, then adapt ads or adjust product supply accordingly. In practice, this can mean deploying extra inventory to a region where a single tweet from a popular influencer set off a chain reaction of thirst for a specific beverage. Yes, it is as adrenaline-filled as it sounds—and occasionally as exhausting.
Executives are often enamored with the notion of real-time analytics because it promises the superpower of instant awareness. But let us be clear: getting that live view of the market requires a robust data infrastructure capable of ingesting large volumes of streaming data, cleaning it, and then analyzing it at breakneck speeds. Tools such as Apache Kafka and Spark Streaming are commonly used to handle high-velocity data, while cloud-based platforms like AWS Kinesis or Google Cloud Dataflow provide scalable pipelines (InData Labs). FMCG players also invest in real-time dashboards—sometimes referred to as “control towers”—that integrate sales data, social sentiment, and supply chain updates into a single screen for executives. It may look like a slick video game, but it is more akin to air traffic control for your products. Mistakes can lead to chaos, wasted spend, or worst of all, an avalanche of social media backlash that is ready to bury your brand under a mountain of sarcasm-laced tweets.
Being able to track the market in the present moment is excellent, but real power lies in seeing the next wave of consumer demand and adjusting accordingly. Predictive intelligence involves analyzing historical data alongside real-time signals to forecast near-future scenarios. Traditional demand forecasting in FMCG, which typically relied on old sales averages and a bit of management “intuition,” can feel about as accurate as reading tea leaves during an earthquake. Modern machine learning techniques, sometimes called “demand sensing,” try to fix that by incorporating a wealth of live inputs, from weather forecasts (for that sudden heatwave driving up ice cream sales) to Google Trends data hinting at interest in new flavor profiles (Echo Blog).
One FMCG firm reported slashing stock-outs—and the dreaded overstock—by incorporating promotional calendars, social media buzz, and even store foot-traffic patterns into advanced machine learning forecasts (Leveraging Digital Analytics). The concept is straightforward: gather every relevant data point you can get your hands on, feed it into a model (often a regression ensemble or a time-series approach enhanced by machine learning), then generate a forecast that updates in near real time. If consumer sentiment shifts overnight because an influencer decides your product is “so last season,” you might spot that negative wave and dial down production before you are stuck with warehouses of unsellable goods. Conversely, if an unexpected frenzy for a new limited-edition flavor erupts, predictive intelligence helps your supply chain shift gears fast enough to avoid empty shelves—and disappointed customers.\\
Coca-Cola’s Freestyle beverage dispensers provide a great example of how real-time data can spark product development in ways that make old-school R&D look glacially slow (Digital Innovation and Transformation). These Freestyle machines allow consumers to create custom mixes from a palette of flavors. The data on which flavor combos people concoct flows back to Coca-Cola continuously, forming a real-time window into consumer taste preferences. Surprisingly—or maybe not—many users started mixing cherry syrup into Sprite, so Coca-Cola launched “Cherry Sprite” as a new bottled product. Thomas Stubbs, the company’s VP of Engineering & Innovation, acknowledged that this insight came directly from watching live consumer behavior on the Freestyle channel. Rather than waiting months for sales data and focus group results, Coca-Cola jumped on what it already knew was a popular combination. The moral of this story is that capturing consumer desires right at the point of consumption can lead to new products that have a significantly better chance of succeeding. If you are tired of rolling the dice on your next flavor release, maybe it is time to let actual customer behavior guide your innovation process.
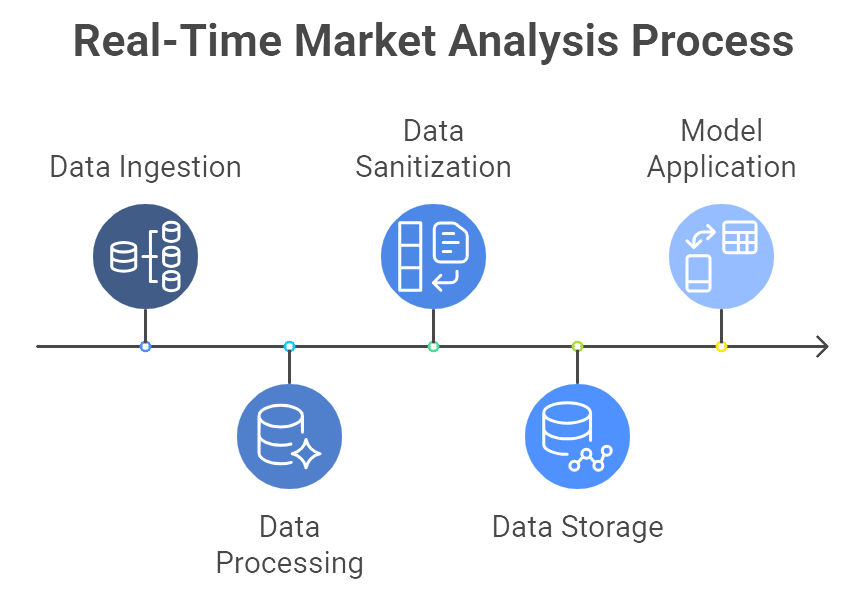
Figure 2: Illustration of the sequential stages of a real-time market analysis, starting with data ingestion and ending with model application. (Image by Napkin).
Behind the scenes of real-time market analysis and predictive intelligence lies an ecosystem of technology that might seem daunting at first glance. Data ingestion tools like Apache Kafka or AWS Kinesis gather massive streams of events—think millions of daily social media mentions or point-of-sale transactions. Platforms like Spark Streaming or Google Cloud Dataflow process and clean that data on the fly, removing duplicates, handling missing values, and standardizing formats (InData Labs). The data, once sanitized, typically flows into a high-performance database or a cloud data warehouse, where analytics software or machine learning models can do the heavier lifting. These models might be built using open-source libraries such as scikit-learn, TensorFlow, or PyTorch, depending on the complexity of the task (Polestar Solutions).
Organizations further enhance their real-time responsiveness with dynamic dashboards that automatically update key metrics as new data arrives. Some FMCG firms set up supply chain “control towers” that integrate IoT sensor information from trucks, warehouses, and retail shelves, so managers can see inventory levels, shipping times, and potential disruptions in real time. A single glitch—like a manufacturing delay or a regional weather event—triggers alerts across the network, prompting corrective action before the issue spirals into a full-blown crisis. If you think of this in pilot terms, the control tower is not just for show; it is a lifeline ensuring your planes (read: products) land safely at their destinations without colliding or running out of fuel along the way (Polestar Solutions).
Real-time market analysis and predictive intelligence can sound like the ultimate silver bullet, but executives should note a few realities. First, the shift from batch updates to continuous data monitoring is not a matter of flipping a switch. It requires investment in infrastructure, a cross-functional team prepared to handle data pipelines, and an organizational culture that values timely insights over hierarchical decision-making. Without the right leadership alignment, even the best technology can languish in partial deployments, delivering minimal real-world impact.
Second, the data streams themselves must be reliable. If you are building crucial forecasts off social media chatter, remember that social sentiment can be fickle, spammy, or influenced by factors you cannot control. Garbage in, garbage out—a cliché in data science for a reason (Davenport and Harris, 2017). That means continuous data validation, cleaning, and integration are essential for accurate insights. Waiting until an erroneous model recommendation has already triggered a fiasco is not the kind of drama you want in your quarterly review.
Finally, do not overlook the ethical dimensions of real-time analytics. Tracking consumers so closely that you know their favorite beverage mix before they do can quickly backfire if mishandled. Data privacy regulations are tightening, and consumers are becoming more discerning about how their data is used. Striking a balance between personalization and privacy is key to maintaining trust in your brand (Polestar Solutions). The last thing any executive wants is to watch their newly minted real-time analytics system become the subject of a scandal that sends customers—and stock prices—running in the opposite direction.
Real-time market analysis and predictive intelligence hold the promise of turning FMCG companies into agile powerhouses capable of reacting (and even preemptively acting) on consumer desires before competitors do. The payoffs can be staggering: fewer stock-outs, optimized promotions, better product innovation, and a level of consumer engagement that can border on clairvoyance. But these advantages do not come cheap or easy. They demand significant investments in technology, as well as an organization-wide willingness to adapt processes and behaviors to a constantly evolving data environment. Executives who embrace these changes stand to position their firms as forward-thinking, customer-centric leaders in a rapidly shifting landscape. Those who cling to the status quo, hoping monthly reports will cut it in an always-on world, might just find themselves marveling at how quickly the competition drank their milkshake.
9.3. Consumer Behavior Insights and Personalization
Understanding consumer behavior rests at the heart of FMCG success. It might sound obvious—selling more means knowing your customers—but the scale and speed at which this happens in modern markets often astonishes even the most seasoned executives. Data science has stepped into the limelight as the bridge between scattered consumer preferences and actionable strategies, providing a more immediate, precise, and often startlingly honest look into what drives buyer decisions. Gone are the days of relying solely on occasional focus groups or dusty sales reports. Today, every purchase, tweet, hashtag, online review, and even the images consumers share on social media form puzzle pieces that reveal why someone picks one product off the shelf and ignores another. These insights then propel businesses from guesswork toward genuine consumer-centricity, which is no small feat in a world bursting with choices and fleeting consumer loyalty (Polestar Solutions).
In earlier eras, FMCG players typically operated with a product-centric view: produce a good that appeals to a broad audience, push it through colossal marketing campaigns, then hope for the best. That approach can still work for a brand with a gargantuan advertising budget, but it is often akin to playing roulette with consumer preferences. Data science shifts the paradigm by offering real-time visibility into who is buying, why they are buying, and how their needs are evolving.
Unilever exemplifies this transition through its network of 30 People Data Centers spread across the globe (Unilever and Capgemini). These centers represent a deliberate, even forceful, institutional effort to make data-driven consumer insights the foundation of marketing, product development, and strategy. By aggregating sales data, survey responses, social media chatter, and other digital footprints, Unilever aims to maintain a “360-degree view” of its consumers. Instead of waiting for monthly or quarterly updates, executives access dashboards with nearly live data streams, fueling quicker pivots on campaign tactics or product lines. In an industry where consumer tastes can swing from kale chips to bacon-flavored chocolate in less than a week, such responsiveness is not just beneficial—it is vital.
The methods employed to dig up these insights run the gamut from old-school statistics to cutting-edge machine learning. For those new to data science, a few definitions might help:
Data Science: The multifaceted practice of extracting insights from vast amounts of data using statistics, computer programming, and domain knowledge.
Statistical Models: Mathematical frameworks (such as regression or time-series analysis) used to understand relationships in data and predict future outcomes.
Machine Learning: A subset of artificial intelligence that trains algorithms on historical data to identify patterns and make predictions or decisions without being explicitly programmed.
Natural Language Processing (NLP): Algorithms that help machines interpret human language, often used for sentiment analysis in social posts or product reviews.
Deep Learning: Advanced machine learning using neural networks with multiple layers, adept at tasks such as image recognition or language translation.
FMCG companies leverage these techniques to reveal consumption patterns, brand perceptions, and cross-category buying tendencies. A classic approach is market basket analysis, where algorithms scan transactional data for items frequently purchased together—information that can spur well-timed cross-promotions or strategic shelf placements. For instance, discovering that customers who buy baby diapers also tend to pick up air fresheners (because life with a newborn might necessitate both) can lead to a marketing synergy that boosts sales of both products.
Social media adds a different dimension, illustrating how consumers talk about brands when they are not being asked by a formal survey. Sentiment analysis, an NLP application, scours platforms like TikTok, Instagram, Twitter, and Facebook for mentions of a product or brand (Digital Innovation and Transformation). The algorithm classifies posts as positive, negative, or neutral, and also identifies the context behind that sentiment. A beverage company might find it is adored in one region because of its nostalgic marketing but criticized in another region for environmental concerns. Armed with this insight, executives can adapt marketing messages, update packaging, or even revise distribution plans with less guesswork and more data-driven confidence.
Image recognition pushes the envelope even further, as brands use it to detect logos in user-generated photos or track how their packaging is displayed in-store. If a snack brand notices that people frequently post pictures of its product at outdoor concerts, it can formulate new event-based marketing campaigns that capitalize on that connection. The technology peels back the curtain on how and where consumers actually engage with products, rather than relying on incomplete or biased self-reporting.
Blending survey data with observational data helps explain the “why” behind the “what.” A consumer panel might self-report that they are interested in health-conscious snacks, but the checkout data might reveal a contradictory surge in sugary treats. Data science can reconcile this discrepancy by segmenting consumers based on actual behaviors, leading to marketing or product recommendations that match how people act, not just what they claim in a survey (Polestar Solutions).
One might assume personalization is the domain of luxury goods or niche e-commerce. Not so. FMCG companies, known for mass production, are increasingly customizing marketing messages, product recommendations, and even product formulations to align with individual or micro-segment preferences. The irony is that we still call them “fast-moving consumer goods,” yet behind the scenes, sophisticated AI models are sifting through billions of data points to create a personal touch that feels almost artisanal.
Machine learning plays a crucial role here, orchestrating everything from targeted ad campaigns to automated product suggestions. AI-based recommender systems—popularized by streaming services and online retailers—are finding their way into FMCG’s direct-to-consumer platforms, offering suggestions like “You may also enjoy these organic chip flavors” based on a shopper’s browsing and purchase history. Deep learning and collaborative filtering enable these systems to learn over time, refining their recommendations as more data comes in (InData Labs).
Companies like Sephora have famously harnessed AI to personalize beauty product recommendations, matching customers’ unique skin tones and preferences to exact product lines. The result: higher conversions and more satisfied customers who appreciate a brand that “gets” them (InData Labs). Although this example hails from the beauty sector, the core principle holds for any FMCG category: harness AI to narrow product suggestions and marketing messages to reflect the consumer’s real needs and preferences, rather than bombarding them with bland, one-size-fits-all appeals.
Consider the example of a global FMCG enterprise that recognized the diminishing returns of broad-stroke marketing campaigns. The old approach—categorizing consumers into a few big buckets like “families,” “health-conscious,” or “on-the-go millennials”—was leaving money on the table. Determined to do better, the company implemented an AI-driven platform that could not only segment audiences into micro-groups but also tailor marketing assets automatically in near real time (Shelly Palmer).
The system analyzed individual consumer data from loyalty apps, e-commerce behaviors, and social media activity to identify subtle differences in preferences. It then generated customized messages for each micro-segment, using natural language generation (NLG) to personalize text and AI-driven image recognition to align visuals with the audience’s demographics and tastes. A/B testing happened on the fly; if a certain ad layout performed poorly for a specific micro-segment, the algorithm automatically adjusted the creative for future impressions (Shelly Palmer).
The results were eye-opening. The company reported a 60% increase in consumer touchpoints—meaning they could engage far more prospects in a tailored way than before—and realized an 8% boost in overall campaign performance (Shelly Palmer). Although 8% might not sound spectacular in isolation, the extra revenue for a giant FMCG brand could amount to tens or even hundreds of millions. More importantly, the company solidified the perception that it “understands” its consumers, a priceless advantage in a market where shoppers are quick to switch brands if they feel overlooked or misunderstood.
The promise of consumer behavior analytics and personalization can seduce any executive, but integrating these capabilities into an existing commercial strategy is no small job. Success depends on building a data infrastructure that can handle large volumes of real-time or near-real-time data, implementing machine learning pipelines that handle everything from ingestion to deployment, and fostering a culture that trusts—and acts upon—data-driven insights.
Cross-functional collaboration proves crucial. Data scientists may build brilliant models, but without input from marketing, sales, supply chain, and product development, those models often gather dust, unused or misunderstood. Leaders who champion interdepartmental dialogue and align incentives around data-driven goals are the ones who typically see personalization efforts flourish. Conversely, organizations that keep analytics teams siloed off in the corner risk a scenario where the best consumer insights never leave a PowerPoint presentation.
The ethical dimension is another key consideration. Personalizing at scale means gathering and analyzing enormous amounts of consumer information, from location data to online browsing habits. Overstep or misuse this data, and the brand’s reputation can plunge faster than you can say “viral boycott.” Balancing personalization with privacy is no longer optional, especially as data-protection regulations tighten worldwide (Polestar Solutions).
Figure 3: Illustration of the importance of both consumer behavior insights and personalization strategies for effective data-driven consumer engagement. (Image by Napkin).
Consumer behavior insights and personalization have rapidly evolved into game-changing differentiators in FMCG. The days of hoping a big-budget TV spot will cover all consumer segments are fading into the background, replaced by agile, data-informed marketing strategies and product development cycles that align with real consumer needs. Data science is the engine that powers these shifts, distilling mountains of seemingly random data points into clear, actionable insights. The outcome can be remarkable: an uptick in sales, stronger brand loyalty, faster product innovation, and perhaps most importantly, a renewed sense among consumers that the brand truly “gets” them.
Yet, adopting these new capabilities requires more than investing in AI platforms or hiring a few data scientists. It demands leadership buy-in, a willingness to adapt legacy processes, and an unwavering commitment to ethical data use. Executives who are prepared to drive these changes stand to transform their organizations into consumer-centric powerhouses. Those who cling to outdated methods, all the while ignoring the consumer data accumulating outside their boardroom door, risk watching their once-leading brand sink into irrelevance. The choice might seem stark, but it is also an opportunity: data science finally allows FMCG firms to meet consumers where they truly are, and to do so at scale. Embrace it wholeheartedly, and you may just discover that your customers have been telling you exactly what they want all along.
9.4. Optimizing the Supply Chain with Data Science
The supply chain is the lifeline of any FMCG business. From raw materials entering factories to those familiar shelves in supermarkets, the journey is rife with opportunities for cost savings and efficiency gains—or, if managed poorly, for expensive blunders and delayed deliveries. As consumer expectations continue to rise, supply chain optimization has moved from a behind-the-scenes concern to a boardroom priority. And data science, with its arsenal of advanced analytics, machine learning, and real-time dashboards, is leading the charge to revolutionize how FMCG products reach end consumers (Polestar Solutions).
Executives know that in FMCG, even minor inefficiencies can add up to big losses when you are shipping millions of product units per month. Fortunately, the modern supply chain is awash with data, from electronic point-of-sale (EPOS) figures and warehouse logs to sensor readings on production equipment and GPS trackers on delivery trucks. The question is no longer whether you can gather this data; it is whether you can harness it quickly and intelligently enough to stay a step ahead of fickle demand shifts and potential disruptions. The following sections break down how data science powers the key components of the FMCG supply chain, from predicting demand before it materializes to mapping out the fastest, most cost-effective routes for last-mile delivery.
Most executives in FMCG have lived through the nightmare of a product going viral just when the warehouse runs out of stock—only to be left holding an embarrassing inventory surplus once the craze dies off. This is where advanced demand forecasting powered by data science can make all the difference. Predictive models incorporate real-time signals such as social media chatter, promotional calendars, and regional economic indicators, rather than relying on stale historical averages. Machine learning algorithms parse through these diverse data streams to find complex patterns that human planners would struggle to spot (DigitalDefynd).
When demand forecasts become more accurate, inventory optimization enters the spotlight. Managing inventory is a delicate balancing act: hold too much stock, and you are burning money on warehousing costs and risking obsolescence; hold too little, and you are dealing with missed sales and unhappy customers. Data-driven optimization algorithms can simulate different scenarios—predicting, for instance, how a sudden heatwave in one region might spike beverage sales and deplete local inventory. Companies use these algorithms to adjust replenishment schedules, reallocate stock across distribution centers, or schedule production shifts more precisely. The bullwhip effect—where minor fluctuations in downstream demand balloon into massive production swings upstream—shrinks considerably when planners have real-time data and robust machine learning forecasts. Nestlé, for example, reported higher visibility and faster response times by integrating advanced forecasting models, leading to less waste and fewer stock shortages (DigitalDefynd).
Beyond forecasting, data science also tackles the complexities of FMCG manufacturing, where unexpected machine breakdowns can lead to catastrophically long production delays. Predictive maintenance, fueled by IoT sensors and machine learning, offers a proactive solution. Sensors measuring temperature, vibration, and pressure continuously feed data into predictive models. These models look for early warning signs—like a gradual rise in a compressor’s vibration frequency—that indicate a part is on the brink of failure.
When the algorithm flags a high-risk component, maintenance teams can intervene before a catastrophic breakdown halts production. Compared to reactive or calendar-based maintenance, this data-driven approach saves both time and money. You only fix machines that actually need attention, while avoiding the enormous losses that would accompany an extended production line shutdown. Nestlé’s manufacturing plants, among others, have successfully reduced downtime by leveraging predictive maintenance, demonstrating the practical bottom-line impact of advanced analytics (DigitalDefynd).
After you have manufactured the product, the next challenge is getting it to retailers and, ultimately, to customers in the fastest, most cost-effective way. Enter the minefield of routing, fleet management, and delivery optimization. Data science again rises to the occasion. Routing algorithms—often tackling classic challenges like the traveling salesman or vehicle routing problem—help companies determine how to load trucks, sequence deliveries, and minimize total distance traveled. This is not a once-and-done exercise; real-time systems can reroute vehicles on the fly if a traffic jam is detected or if a sudden spike in demand warrants immediate replenishment at a specific location (Polestar Solutions).
Transport optimization does not end with the route itself. FMCG firms often operate multiple distribution centers, shipping lanes, and carrier partners. Logistics analytics can suggest which facilities to use for each order to keep shipping times short and costs in check. In some cases, merging distinct delivery networks yields surprising efficiencies. A company might discover that combining deliveries from two product lines onto the same trucks can maintain service levels but slash total miles traveled by a hefty margin (Polestar Solutions). Alongside these routing feats, real-time dashboards—sometimes referred to as “supply chain control towers”—track shipments, inventory positions, and potential disruptions such as extreme weather or political turmoil that could delay deliveries.
A multinational FMCG titan, illustrated by Nestlé’s recent transformation, offers a vivid example of how data science can overhaul the entire supply chain. The company adopted an AI-driven forecasting system that pulled in data from sales trends, social media signals, and regional economic indicators. Simultaneously, its factories were outfitted with IoT sensors streaming data to predictive maintenance algorithms. Meanwhile, advanced analytics monitored delivery fleets and distribution hubs to optimize routes and speed up fulfillment (DigitalDefynd).
The impact was swift and palpable: production lead times dropped, logistics costs sank, and overall waste—including spoilage of perishable goods—decreased. When a sudden demand spike appeared in a specific region, the system alerted supply chain managers, who rerouted stock from a nearby distribution center, ensuring shelves were replenished before customers could even notice a potential shortage. Procter & Gamble, another global FMCG heavyweight, reported similar gains by digitizing supply chain processes. The bottom-line lesson is clear: data science, when fully integrated into operations, can transform supply chain management from a reactive scramble to a well-choreographed dance (DigitalDefynd).
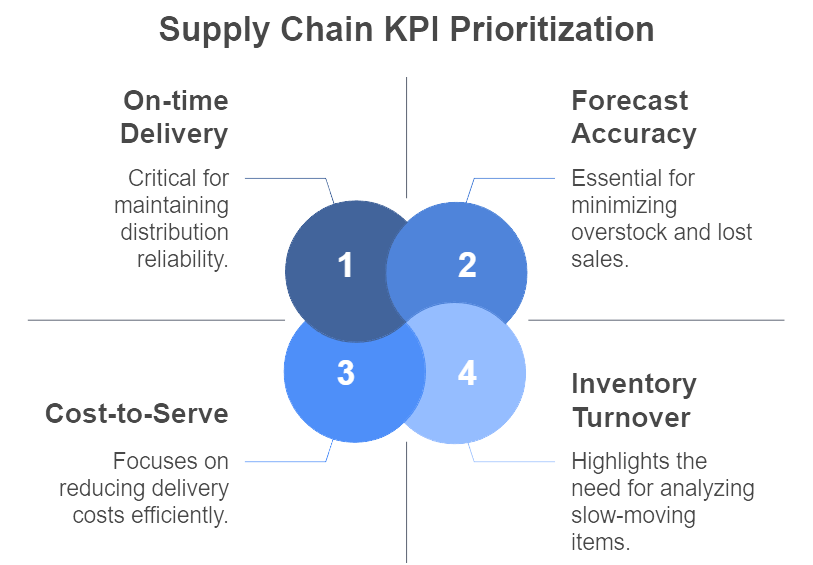
Figure 4: Illustration of the strategic prioritization of key performance indicators like on-time delivery and inventory turnover in supply chain management. (Image by Napkin).
Data science thrives on quantification and continuous feedback. Supply chain optimization is no exception, and many FMCG leaders track key performance indicators (KPIs) that serve as a scoreboard for their analytical initiatives (FMCG Analytics Case Study). Some of the most common metrics include:
Forecast Accuracy: Gauges how closely demand forecasts match actual sales. High accuracy reduces both overstock and lost sales.
Inventory Turnover: Measures how quickly stock moves. If your inventory is gathering dust, it might be time for deeper analytics or a revision of your product portfolio.
Fill Rate: Indicates what percentage of orders are fulfilled completely and on time. Improving this metric often correlates with higher customer satisfaction.
On-Time Delivery (OTD): Tracks the reliability of distribution. Data science can boost OTD by rerouting shipments away from delay-prone routes.
Order Accuracy: Reflects error-free deliveries. Analytics can identify frequent mishaps—like picking the wrong product—and help target process improvements.
Days of Inventory (DOI): Tallying how many days of stock you have on hand. The goal is to keep this number as low as possible without risking out-of-stocks. Data science guides this balancing act.
Supply Chain Cycle Time: Measures the total end-to-end duration from procuring raw materials to delivering finished goods. Shortening this time through analytics means faster reactions to market changes.
Cost-to-Serve: Calculates the total cost of delivering a product to the customer. By analyzing transportation and warehousing costs at a granular level, companies can identify opportunities for cost reduction without sacrificing service levels (InData Labs).
The magic lies in connecting these metrics to deeper data analysis. For instance, if On-Time Delivery starts trending downward in a particular region, advanced analytics can pinpoint the root cause—an understaffed distribution center, a pattern of traffic congestion, or poor forecasting for local demand—so managers can act quickly. A well-structured data pipeline, combined with real-time dashboards, transforms KPIs from static numbers into dynamic signals that spur continuous improvement (FMCG Analytics Case Study).
Achieving a data-driven supply chain is not just a matter of selecting the right software vendor or sprinkling a few data scientists into your operations. As with any significant organizational shift, leadership buy-in and cultural alignment are essential. Seamless collaboration between data scientists, IT staff, domain experts, and executives fosters an environment in which data-driven insights become part of daily decision-making. Skipping this cross-functional collaboration often leads to projects that stall at the pilot phase, never quite translating to enterprise-scale impact.
Leaders who champion data science also have to grapple with the ethical and security aspects of gathering vast amounts of operational and customer data. While less visible than consumer privacy concerns, supply chain intelligence can inadvertently expose proprietary details to third parties or malicious actors. Governance frameworks and robust cybersecurity measures are now table stakes for any serious data initiative.
Ultimately, an optimized supply chain guided by data science can be a source of competitive advantage in the FMCG sector. In an arena where margins are razor-thin and consumer demands change in an instant, faster reaction times, lower costs, and consistent product availability can be the deciding factors between winning and losing market share. Embrace data science wholeheartedly, invest in the right infrastructure and talent, and the payoff can be extraordinary. Ignore it, and do not be surprised when a competitor’s near-flawless supply chain starts capturing the loyalty of retailers and customers alike.
9.5. Data Science in Product Innovation and Marketing Strategy
Data science is not just about streamlining what your business already does; it can also spark the next wave of consumer products and orchestrate highly effective marketing campaigns. In the FMCG world—where shelf space is prized, consumer tastes change with the speed of a trending hashtag, and margins are forever under siege—using data as a crystal ball for product innovation and marketing strategy has quickly become essential. The days of simply trusting your gut and a few dusty market reports are gone. Modern executives are turning to analytics, AI, and machine learning to craft offerings that resonate with evolving consumer desires and to market them in ways that capture attention and loyalty faster than the competition can say, “Wait, what just happened?”
Developing new FMCG products has traditionally been equal parts art, science, and guesswork. Companies conducted consumer surveys, ran concept tests in a few cities, and hoped they had picked up on the right signals. This hit-or-miss approach might have worked when product cycles stretched for years and consumer preferences were slower to shift. Today, the game is different. Digitized supply chains and 24/7 consumer feedback loops have accelerated the pace of innovation. Data science allows FMCG firms to spot emerging trends almost as soon as they begin percolating on social media, search queries, or online forums. If a sudden surge of interest in “keto-friendly candy bars” starts popping up across various channels, a forward-thinking brand can accelerate R&D to meet the demand before dozens of me-too products flood the market.
In some cases, data even becomes the catalyst for ideas no one in-house had considered. Coca-Cola’s now-famous decision to launch Cherry Sprite sprang directly from usage data gathered via the Freestyle machine, which tracked how frequently people blended cherry syrup into their Sprite (Digital Innovation and Transformation). This is product development that practically writes itself: the analytics show that a new flavor already has enthusiastic fans, so the leap from concept to store shelves is relatively low-risk.
More advanced product innovation uses AI and machine learning in the actual design process. Procter & Gamble, for instance, integrated AI into its fragrance R&D, training models to suggest scent combinations that a human perfumer might overlook (Consumer Goods Technology). It is akin to having a digital co-creator that tests “what if” scenarios at lightning speed, drastically reducing the guesswork. Another P&G innovation in the Pampers line uses baby data (like weight or height) to recommend the right diaper size, blending product functionality with a data-driven recommendation engine. The result is an offering that not only solves a universal parenting headache—leaks—but also entrenches brand loyalty, since consumers often come to rely on this “smart” guidance.
Under the hood, these product-innovation breakthroughs rely on tried-and-true data science processes, starting with data collection and cleaning. Whenever you see a brand claim it “mined millions of consumer interactions,” you can bet an entire back-end pipeline handles the gritty work of consolidating messy spreadsheets, unstructured social media posts, and perhaps sensor readings from IoT devices. Data scientists then perform exploratory analysis—looking for anomalies, patterns, or relationships that might point to a new product angle or improvement in an existing formula.
Next, the modeling phase begins. Depending on the project, it could involve a range of techniques: regression models to estimate the impact of adding a new ingredient on consumer preferences, cluster analysis to group consumers by taste profiles, or even deep learning networks to parse textual feedback in multiple languages. Model evaluation follows suit, often requiring carefully curated validation sets to avoid overfitting. Finally, once a model seems robust, it is deployed—sometimes as an internal R&D tool used by product teams, other times as a direct consumer-facing component (like an online flavor-customization feature).
Proper maintenance ensures these models do not become stale. Consumer tastes evolve, supply chain constraints shift, and competitor actions can disrupt entire categories overnight. Continual monitoring and fine-tuning keep AI-powered product innovation aligned with reality. This cyclical process of data collection, cleaning, modeling, deployment, and maintenance might sound like a lot of work, but it is a game-changer in reducing time-to-market and boosting a product’s odds of success.
If data science can help birth your next bestseller, it can also ensure that your marketing dollars do not go up in smoke. The FMCG sector’s evolution in marketing is evident everywhere: from programmatic ads that follow potential customers around the internet (often creepily so) to dynamic in-store displays that change promotions in real time based on inventory levels. Underpinning this shift is a massive amount of data—both from online and offline channels—and the ability to analyze it almost instantly.
A brand might allocate its budget across television, social media, print, and trade promotions. Without data science, deciding which channel deserves which percentage of spend typically devolves into personal biases or old habits. By contrast, a marketing mix model uses machine learning to estimate the incremental sales lift from each channel, factoring in myriad variables like seasonality, competitor promotions, or macroeconomic conditions. The brand can then calibrate its spend accordingly, perhaps shifting an extra 5% of the budget to digital ads targeting health-conscious consumers if the model projects a strong ROI for that audience segment.
Advanced marketers take this a step further with personalization. Suppose a beverage giant wants to run a new energy drink campaign. Data on individual shoppers—from purchase histories to demographic profiles—flows into an AI engine that decides which version of the ad each user sees (InData Labs). A single campaign can spawn hundreds of ad variants, each tailored for a specific micro-segment. The results often speak for themselves: higher click-through rates, improved brand recall, and more robust sales lifts. Coca-Cola, for instance, leverages AI-based consumer insights to determine whether a given user is more likely to respond to a sports-oriented pitch for Powerade or a thirst-quenching narrative for Coke Zero (InData Labs). When done right, it is the digital equivalent of reading a shopper’s mind, albeit with fewer psychic powers and more data crunching behind the scenes.
One of the biggest mindset shifts triggered by data science in marketing is a relentless focus on experimentation. Previously, marketing teams would launch a campaign and run it for weeks, analyzing the outcomes once the dust settled. Now, continuous A/B testing (or multivariate testing) is standard protocol. Executives do not have to wait until the campaign ends to see if it is a hit or a flop; the performance data rolls in almost hourly. If one ad variant underperforms, it can be tweaked or replaced the next day. This iterative cycle tightens the feedback loop, enabling marketers to optimize campaigns on the fly (Shelly Palmer).
Data-driven marketing also illuminates which metrics truly matter. Many organizations still cling to “vanity metrics” like views or likes, which do not necessarily translate to purchases. More sophisticated teams delve into multi-touch attribution, trying to determine whether a consumer who eventually bought the product was swayed more by that ephemeral TikTok video, a store coupon, or a billboard near the office. Understanding these attribution insights can reveal that, for example, a flashy influencer campaign generates quick awareness but the final nudge often comes from an in-store promotion. Armed with that knowledge, marketers can adjust their spend and timing to ensure each channel works synergistically rather than redundantly.
One global FMCG brand recognized that its broad-brush campaigns were no longer delivering the punch they once had. Rather than guess which tactics might fare better, the company invested in a marketing analytics platform to sift through past campaign performance, demographic data, and even competitor activity (Shelly Palmer). The analytics revealed that a younger demographic responded better to online video and influencer tie-ins, while older consumers tended to favor TV spots or coupon inserts in newspapers. This was not exactly shocking, but the model revealed more nuanced segmentations, like a “health aficionado” cluster that spanned various age groups and responded exceptionally well to targeted ads emphasizing natural ingredients.
Leveraging these insights, the brand rebalanced its marketing spend, introduced micro-targeted ad creatives, and relentlessly ran A/B tests on email subject lines, product tagline options, and influencer partnerships. The result was a marked increase in campaign ROI with the same total spend. In one new product launch, AI-driven audience targeting yielded an 8% uplift in performance compared to a prior baseline (Shelly Palmer). While 8% might not sound earth-shattering, in the world of multi-million-dollar campaigns, that can translate to tens of millions in extra revenue—and a renewed confidence that marketing is actually reaching the right people with the right message.
Data-driven product innovation and marketing strategies do not magically materialize overnight. They require leadership that sees beyond vanity metrics and fosters cross-functional teamwork among data scientists, brand managers, product developers, and digital marketing agencies. A brilliant machine learning model is pointless if brand managers ignore its insights. Likewise, data scientists need domain expertise to design models that address real business challenges rather than constructing technically elegant but commercially irrelevant solutions. Executives who champion this culture of collaboration, experimentation, and data-driven decision-making are far more likely to see sustained success—and a tangible ROI on their data initiatives.
There are also ethical considerations. Gathering every shred of data on consumer behavior, from what they post on TikTok to how they navigate e-commerce sites, is undeniably powerful. Overstep your bounds, though, and you can easily alienate the very customers you are trying to court. Privacy regulations are tightening around the globe, and consumer backlash against perceived intrusions can be swift. The trick is to personalize without being creepy, to innovate without antagonizing the user base.
Data science has jolted FMCG product innovation and marketing out of complacency, forcing organizations to reevaluate everything from how they conceive new product ideas to how they deliver final messages to consumers. The shift from gut-feel to data-driven does not just produce incremental gains; it can fundamentally reshape an FMCG business’s approach to growth. Product development cycles become faster, better targeted, and less risky. Marketing campaigns generate higher returns and feel more relevant to consumers. When done right, the result is a virtuous cycle in which insights gleaned from consumer data inform future innovations, and each subsequent launch or campaign is smarter than the last.
Yet, none of this should be mistaken for an easy win. Data collection, cleaning, exploration, model building, deployment, and maintenance all demand sustained investment in technology, talent, and leadership alignment. Organizations must also adopt a healthy respect for experimentation—and for the possibility that some of the data might reveal uncomfortable truths or require big shifts in strategy. For executives who are ready to listen to those truths and act on them, data science can be a powerful catalyst for progress in both product development and marketing. Ignore it at your peril, because in the FMCG landscape, consumer preferences move quickly, and the competition is always eager to serve them better.
9.6. Challenges and Ethical Considerations in FMCG Data Science
As the FMCG industry ramps up its reliance on data science, it also confronts a host of ethical quandaries that cannot be dismissed as a mere “compliance issue.” Gathering vast amounts of consumer data comes with privacy obligations that can feel like navigating a legal labyrinth. Meanwhile, algorithms—ostensibly cold and objective—can inadvertently replicate old biases in new, high-tech ways. For executives, these are not abstract problems for the IT department. They are business-critical issues that can reshape consumer trust, brand reputation, and the bottom line. Done right, responsible data practices and ethical AI can provide a competitive edge, reinforcing consumers’ confidence that your brand is worthy of their loyalty. Done poorly—or ignored altogether—they can bring hefty fines, public scandals, and a not-so-friendly phone call from regulators.
In a data-driven world, personal information is the new currency, and FMCG brands handle plenty of it. From loyalty programs that track purchase histories to smartphone apps that reveal location data, these companies often hold detailed consumer insights that once belonged squarely to credit card companies or telecom providers. The goldmine of information fuels personalization, targeted marketing, and deeper consumer understanding. Unfortunately, it also attracts regulators keen on protecting consumer rights and punishing overreach. The European Union’s General Data Protection Regulation (GDPR) is a prime example, dictating rules on how companies may collect, store, and use personal data. Penalties for non-compliance can reach the eye-watering sum of 4% of annual global revenue or €20 million, whichever is higher (Adimo). That figure is enough to grab any CFO’s attention.
As many FMCG executives learned while preparing for GDPR’s 2018 implementation, data sprawl can be shockingly widespread. Multiple brand divisions, legacy systems, marketing agencies, and even promotional partners all collect bits and pieces of consumer data. Figuring out exactly where each data record resides—and whether there is valid user consent—is often the first major challenge (Adimo). Some companies discovered troves of old contact lists with obscure provenance or endless archives of consumer behavior data that nobody had looked at in years. Sweeping data audits suddenly became top priority, not only to avoid fines but also to avoid brand embarrassment. After all, no consumer wants to find out that brand X’s “friendly promotional emails” were spammy missives from a database no one had vetted since 2005.
Interestingly, many FMCG firms found a silver lining once they embraced these new privacy standards. In cleaning up their data, streamlining consent forms, and clarifying what consumer information was actually necessary, some discovered that their marketing campaigns became more efficient (Adimo). With fewer irrelevant contacts clogging the pipeline, open rates rose and engagement improved. In short, compliance forced companies to become more disciplined, which in turn often meant better results—and a reputational boost from consumers who saw the brand making a genuine effort to treat their data with respect.
Privacy compliance also goes hand in hand with cybersecurity. No matter how airtight your policies, data breaches can undermine years of trust-building in a single, mortifying headline. FMCG companies now appoint Data Protection Officers, invest heavily in threat monitoring, and build robust data governance structures to limit access to sensitive information. While these measures were once seen as bureaucratic overhead, many brands now tout their commitment to privacy and security as a selling point, capitalizing on consumer wariness about how corporations handle personal data.
Collecting data is one thing; using it to power AI models is another. On paper, algorithms are the perfect employees: they never take breaks, never complain, and can parse massive datasets to make predictions that dazzle your marketing department. But reality is messier. AI models are only as good as the data they learn from, and that data often carries human biases—some overt, some less obvious. If the training set skews toward certain demographics, your AI might develop patterns that systematically disadvantage or overlook specific consumer groups (Talkdesk).
One glaring example is an algorithm that disproportionately offers premium products to men and budget products to women, assuming the latter group is more “price-sensitive.” Another might push targeted ads primarily to neighborhoods of a certain ethnicity, effectively excluding others. These unconscious patterns can erode brand trust faster than you can say “Twitter backlash.” Recent surveys suggest consumers are already skeptical: a majority believe AI-based product recommendations may be biased or rooted in stereotypes (Talkdesk). In other words, more than half your potential audience might disregard those fancy recommendations on your website because they suspect the system is playing favorites.
The trouble is not limited to marketing. AI can guide which SKUs a retailer chooses to stock in certain areas, or it might influence promotions that only apply to people matching a narrow profile. The moral and commercial pitfalls are significant. If an AI inadvertently steers only certain ethnic or age groups toward a beneficial offer, that is not just a PR nightmare—it could draw regulatory scrutiny or lawsuits. Nearly 9 in 10 consumers insist that brands should develop internal policies to ensure ethical AI use (Agility PR Solutions). Moreover, 86% expect businesses to actively monitor and mitigate bias (Agility PR Solutions). These are not mild sentiments; they indicate a clear mandate from the market.
Facing these realities, many FMCG leaders recognize that “responsible AI” is not just a buzzword but a necessity. That starts with data minimization. If you do not truly need a piece of consumer information, do not collect it. Clear consent forms help ensure consumers understand what data they are sharing and why. This transparency fosters trust and lessens the fallout should something go wrong down the line.
Next comes robust data governance—complete with encryption, role-based access controls, and routine audits. The idea is to embed privacy, security, and fairness into the project from the ground up, rather than tacking them on at the end (Adimo). FMCG brands adopting “privacy-by-design” and “security-by-design” approaches may find that their data initiatives sail through compliance checks more smoothly and are less prone to causing consumer alarm.
To address bias, some companies conduct fairness audits on their AI models before rolling them out. Tools like IBM’s AI Fairness 360 or Google’s What-If Tool can detect when certain segments receive consistently worse (or better) outcomes. Adjustments might range from changing the training data mix to adding constraints that force the model to treat subgroups more equitably. Another tactic is to form an internal ethics board or partner with third-party experts. A diverse team of reviewers can catch implicit biases a homogenous group might overlook.
Equally important is communicating with consumers about AI usage. Many shoppers say they would trust product recommendations more if retailers were upfront about how algorithms make suggestions (Agility PR Solutions). Imagine a simple disclaimer on your e-commerce site: “These product recommendations are generated by an algorithm that analyzes your browsing and purchase history. We strive to ensure fairness for all users. Have feedback? Let us know.” That kind of transparency can diffuse suspicion and invite constructive input. In a world where consumers have grown jaded by hidden data practices, a little honesty can go a long way.
Consider an FMCG giant that discovered it had amassed an unruly hoard of consumer data across various brand promotions, e-commerce portals, and third-party partners. The company realized just how vulnerable it was with GDPR’s enforcement looming. Marketing and IT teams scrambled to locate, categorize, and secure personal information that had been collected under myriad pretexts over the years. In some instances, records dated back to offline contest entries stuffed into file cabinets.
This chaos triggered a massive compliance initiative. The firm mapped every data repository, identifying which consumer records it had legitimate consent for, and deleting or anonymizing the rest. It updated websites and apps to feature clearer privacy notices and added user-friendly preferences so consumers could customize what data they shared. The entire marketing function underwent training on GDPR and data ethics, shifting the mindset from “grab all the data you can” to “collect only what you genuinely need, with proper permissions” (Adimo).
Once the dust settled, the brand emerged with a cleaner, consolidated data environment. Campaign targeting improved because it no longer relied on outdated, uninterested user segments. Engagement rates climbed, and unsubscribes dropped as users felt more respected. The firm even leveraged this new stance as part of its brand identity, running a campaign that highlighted how consumer data was protected. The result? Not only did it dodge regulatory fines, but it gained a reputation for being privacy-friendly at a time when consumer data exploitation was making headlines almost daily.
Data science offers immense promise to FMCG companies hungry for deeper consumer insights and operational efficiencies. Yet as these capabilities expand, so do the responsibilities. Ignoring privacy laws or failing to address bias can quickly cancel out any short-term gains, replacing them with legal troubles or a tarnished brand. Meanwhile, the most forward-thinking companies see ethical data usage and responsible AI as an opportunity, not a burden. They leverage compliance to streamline their data processes, use transparency to foster trust, and continuously audit their AI models to ensure fair, inclusive outcomes.
Figure 5: Illustration of the building blocks of a data-driven strategy, showcasing the importance of ethical practices, trust, and privacy for long-term success. (Image by Napkin).
Executives who grasp these realities—who champion not just the technological possibilities but also the moral and cultural imperatives—are best positioned to thrive. After all, building a data-driven strategy on shaky ethical ground is like constructing a skyscraper on sand. It might look impressive for a while, but one regulatory quake or public backlash can bring the whole structure down. Conversely, a solid foundation of ethical, privacy-conscious data science does more than ward off worst-case scenarios. It builds consumer loyalty, enhances brand credibility, and enables more nuanced, genuinely useful insights. In the FMCG game, that is a long-term competitive advantage no company can afford to ignore.
9.7. The Future of Data Science in FMCG
As our hyper-digital world continues its steady march into the 2030s, the FMCG industry finds itself in a particularly dynamic phase of transformation. Data science, which has already catalyzed sweeping changes in how consumer products are manufactured, marketed, and distributed, shows no sign of slowing down. Instead, new technologies—from AI to blockchain, from IoT to advanced automation—promise to make data-driven strategies even more pervasive and indispensable. The firms best positioned to succeed will be those that harness these tools not simply as novelties but as integral elements of a consumer-centric, ethical, and highly efficient business model.
Within the next decade, expect AI to evolve from a mostly supportive role to one of greater autonomy in FMCG operations. Currently, machine learning models suggest optimal production levels or channel-specific marketing spend. In the future, advanced AI systems may adjust production schedules in real time based on live data feeds, freeing human planners to focus on strategic decisions rather than frantically recalibrating daily or weekly forecasts. By 2030, the notion of “AI-driven factories” may no longer sound futuristic; it could simply be how modern FMCG organizations operate (DigitalDefynd).
Generative AI stands out as a particularly promising frontier. Such models can produce new creative output—images, text, even product design ideas—based on patterns gleaned from huge datasets. Already, some companies experiment with AI-assisted flavor combinations or automated ad copy. Within a few years, generative AI might be commonplace for conceptualizing new product formulas, designing packaging, or creating endless permutations of marketing assets for micro-segmentation. Where marketing once demanded an army of copywriters or designers, an AI “creative director” could lighten the load by churning out draft ideas at scale, letting human experts refine the best options.
Deep learning models, proficient in analyzing video or audio, will also accelerate. Brands might interpret real-time in-store camera feeds—ensuring privacy protections are in place—to observe how consumers browse aisles and engage with displays. They might also sift through recorded customer service calls with natural language processing to pinpoint recurring frustration or confusion. The upshot is a holistic, almost real-time feedback loop that not only identifies problems quickly but also suggests data-backed solutions.
Envision a scenario in which a sensor in a retail store’s shampoo aisle notices low stock, automatically flags a distribution center’s AI system, which in turn dispatches an autonomous vehicle to deliver more product—no human oversight required (DigitalDefynd). While this precise scenario may still be a few years off, the technologies to enable it are already in development. FMCG companies increasingly invest in IoT sensors at every stage of the supply chain: factories, transport fleets, warehouses, and even end-user appliances (consider the rise of “smart” refrigerators or pantry monitors).
The promise of 24/7 operations, minimal error rates, and reduced labor costs has accelerated the push for warehouse automation and “lights-out” manufacturing. Procter & Gamble’s ongoing smart factory initiatives offer an early glimpse of what is possible—robotic systems handling everything from packaging to sorting, guided by real-time analytics that minimize downtime and recalibrate production on the fly (DigitalDefynd). As more companies adopt these methods, the gap between advanced data-driven supply chains and those clinging to manual processes will likely widen, with the winners enjoying lower costs, faster delivery, and more reliable service levels.
Consumers are demanding unprecedented levels of insight into product origins, ethical sourcing, and environmental impact. Blockchain technology stands poised to meet that demand by providing an immutable record of a product’s journey from farm or factory to store shelf (Blockchain in the food supply chain - What does the future look like?). Early pilot programs by Walmart, Unilever, Nestlé, and others demonstrate that blockchain can slash the time needed to trace products—like produce or baby formula—from a week to mere seconds (Blockchain in the food supply chain - What does the future look like?).
By 2030, it may become standard practice for every product in certain categories—especially food, cosmetics, and pharmaceuticals—to carry a unique identifier linked to a blockchain ledger. With a simple scan of a QR code, consumers might see exactly when and where a product was manufactured, which intermediaries handled it, and whether it meets specific sustainability criteria. This level of transparency could serve as both a marketing advantage and a protective measure against counterfeits, recalls, and fraudulent goods. For the data-savvy FMCG enterprise, blockchain-based traceability also provides granular insights that can further optimize sourcing strategies, manufacturing schedules, and inventory planning.
What if, instead of one-size-fits-all products, brands increasingly offered made-to-order foods, beauty items, or health supplements? AI models, fueled by data from wearables or user preference profiles, might recommend custom product formulations delivered directly to the consumer’s doorstep (Deliverect). While this level of personalization once seemed limited to niche sectors, it is making serious inroads into mainstream FMCG categories. Brands already dabble in personalized vitamin packs or snack assortments based on dietary preferences. The logical extension is a future where your wearable device tracks your micronutrient intake, flags your deficiency in, say, Vitamin D, and automatically orders a beverage mix that replenishes it—tied to your personal taste preferences to boot.
Executing such a vision requires not only advanced AI but also supply chains capable of small-batch or on-demand production. This again underscores the central role of automation, robotics, and robust data pipelines. Personalization at scale can also test the boundaries of privacy and data ethics, meaning those who get it right—offering truly tailor-made products without creeping out consumers—could secure substantial loyalty in a crowded marketplace.
The boundaries separating FMCGs, tech giants, and retailers are blurring. Amazon is both a distributor and a competitor; voice assistants like Alexa or Google Assistant have effectively become new storefronts. Brands now confront the reality that half the shopping journey could be completed via a simple voice command (“Alexa, reorder my favorite coffee pods”). Getting recommended in these AI-driven ecosystems demands specialized strategies that blend search engine optimization with voice-oriented brand cues.
Smart homes represent another horizon. If your refrigerator tracks every grocery item and automatically places orders before you run out, then “shelf presence” becomes digital rather than physical. FMCG companies may need to supply data—nutrition facts, brand descriptions, ethical sourcing credentials—to the fridge’s AI so it can make informed reordering decisions. Whether these systems will prioritize certain brands based on sponsorship, consumer preference learning, or a purely neutral approach remains to be seen. Either way, interfacing effectively with these digital gatekeepers will be crucial for brands that do not want to be left off the automated shopping list.
All these technological shifts hinge on one critical factor: organizational readiness. Becoming a data-driven enterprise is not a matter of flipping a switch or buying the latest analytics platform. It demands a top-down commitment to infuse analytics into decision-making, a workforce that grasps the basics of data interpretation, and cross-functional teams that integrate domain expertise with data science skill sets. Unilever’s approach—embedding data analysts directly into marketing and product teams—provides a glimpse of how silo walls can be broken down for faster iteration (Unilever and Capgemini).
In parallel, executives must foster an environment of continuous learning. Whether that involves partnering with universities, conducting in-house “data boot camps,” or sponsoring hackathons, the pace of change in analytics tools and methods is only accelerating. Data-savvy companies often discover that the biggest bottleneck to transformation is not technology but the culture of inertia—a reluctance to adopt new methods or a fear that AI will replace human roles. Leaders who address these concerns transparently and position data science as a complement to, not a replacement for, human creativity tend to see smoother adoption.
Looking forward, we can anticipate an FMCG landscape nearly unrecognizable to those still anchored in 1990s-style mass production and broad-brush marketing. Supply chains might become near-zero-waste systems, with predictive analytics aligning production and demand so precisely that surplus inventory or stock-outs become rare anomalies. Marketing could transform into a perpetually personalized conversation with each consumer, delivered across countless digital channels that range from social platforms to VR shopping experiences.
Environmental sustainability goals—backed by advanced analytics—will likely be the next big driver, as climate change concerns spur regulators and consumers to demand more responsible production and distribution. Data science will help track carbon footprints, optimize route planning for fewer emissions, and design packaging with minimal environmental impact. On the consumer-facing side, augmented reality and “metaverse” retail may become practical channels, letting prospective buyers virtually test home goods or envision how a hair color product looks under different lighting—generating yet another data stream for brands to analyze.
Ultimately, the common thread is that data is shifting from a supportive role to a core strategic asset. By 2030, AI will not be a standalone project for which you occasionally hire a consultant or run a pilot. It will be woven into the very fabric of how FMCG companies conceive products, manage supply chains, execute marketing, and maintain consumer relationships. Those that get it right—balancing innovation with ethics, personalization with privacy, and automation with a human touch—will stand to dominate the marketplace of the future.
9.8. Conclusion and Further Learning
In conclusion, the FMCG industry is firmly on a data-driven trajectory – those companies that harness data science effectively are reaping significant rewards in agility, efficiency, and customer connection. By embedding analytics into everything from market analysis to supply chain operations, FMCG businesses can respond dynamically to ever-shifting consumer demands and market conditions. The case studies in this chapter demonstrate that data-driven decision-making is not just theory but a real source of competitive advantage, whether it’s reducing stockouts with predictive forecasts or boosting campaign ROI with AI personalization. At the same time, firms must navigate challenges around data privacy and ethical AI usage, ensuring that the drive for insights does not compromise consumer trust. The evolving landscape suggests a future where advanced technologies – AI, IoT, automation, and more – will become standard tools in an FMCG company’s arsenal. Ultimately, FMCG players that build a culture of data, invest in the right tools, and remain vigilant about responsible use of data will be best positioned to thrive in the next decade. They will be the ones who not only leverage market trends and supply chain intelligence to their benefit but also deliver superior value and experiences to consumers, creating a virtuous cycle of growth in the data-driven age of consumer goods.
The following prompts present a range of hands-on scenarios that illustrate how data science and AI can transform core processes within FMCG organizations. Readers can engage their favorite AI assistant to brainstorm system designs for real-time analytics that catch sudden sentiment shifts, propose advanced predictive models (like LSTM or gradient boosting) for seasonal demand forecasting, or create strategies for analyzing social media posts to inform product innovation. Other prompts dive into how FMCGs might structure deep learning approaches to segmentation, build recommender systems that nudge shoppers towards complementary items, or orchestrate “segment of one” marketing that personalizes every aspect of a brand’s customer interaction. There are also operational challenges—like using digital twins for supply chains, deep learning for predictive maintenance, and computer vision for cashier-less retail experiences. Readers can confront ethical dilemmas around AI-driven dynamic pricing or facial recognition in advertising, and even envision the blockchain’s role in creating transparent, trustworthy product traceability. Finally, they can look to a futuristic organizational structure where data science permeates every department, shaping strategy and day-to-day tasks in a 2030 FMCG enterprise.
Real-time Analytics Brainstorm: How would you design a real-time analytics system for a global beverage company to detect and react to sudden changes in consumer sentiment about its products? Discuss data sources and response actions.
Demand Forecasting Experiment: Consider an FMCG with highly seasonal products. What advanced predictive modeling techniques (e.g., LSTM neural networks, gradient boosting) could improve their seasonal demand forecasts, and how would you train and evaluate these models?
Social Media Sentiment Project: Develop a plan for an AI model that analyzes social media posts to not only gauge sentiment for a snack brand but also recommend actionable insights (like product tweaks or new flavors). What challenges in language or context might you face?
Consumer Segmentation Deep Dive: Imagine you have a rich dataset of an FMCG’s e-commerce customers (demographics, browsing behavior, purchase history). Propose a deep learning approach to segment these customers into meaningful groups for personalized marketing.
Recommender System Design: How could a grocery retailer implement a recommendation engine that suggests complementary products in a shopper’s cart? Outline the use of collaborative filtering or deep learning in making relevant recommendations without being intrusive.
Hyper-Personalization Scenario: Envision a “segment of one” marketing strategy for a cosmetics brand. What data would you gather on each customer and how would a deep learning model use it to tailor everything from product recommendations to marketing emails uniquely for each person?
Supply Chain Digital Twin: Discuss how you would create a digital twin of an FMCG supply chain using machine learning simulation. What data would feed the twin, and how could it be used to test scenarios like demand spikes or supplier disruptions?
Predictive Maintenance Analysis: For an FMCG manufacturing plant, design a deep learning model to predict equipment failures. Consider what sensor data is needed and how you would handle imbalanced data (since failures are rare compared to normal operation).
Autonomous Retail Stores: With concepts like Amazon Go, how might FMCG companies adjust their data strategy? Explore the deep learning models behind cashier-less stores (computer vision for item recognition, tracking) and the kind of insights FMCG manufacturers could gain from them.
AI Ethics in Marketing: Debate the ethical implications of using AI to analyze and possibly manipulate consumer behavior (for example, dynamic pricing that offers different prices to different customers). How can companies ensure fair practices while maximizing marketing effectiveness?
Blockchain for Traceability: Formulate how a blockchain solution, combined with IoT, would work for an FMCG company to provide end-to-end traceability of a food product. What data gets written to the blockchain at each step, and how could AI use this data for quality control?
Augmented Reality (AR) in FMCG: Imagine an AR app that helps consumers shop (e.g., showing product info or recommendations when they scan an item with their phone). What data would support this app, and how could machine learning tailor the AR experience to individual user preferences?
Churn Prediction Challenge: For a subscription-based FMCG service (say, monthly snack box deliveries), design a model to predict customer churn. What features might be most predictive (e.g., engagement metrics, usage patterns), and how would you prevent the model from being biased?
Marketing Mix Modeling with AI: Describe how a deep learning model could improve marketing mix modeling by capturing non-linear interactions between channels. How would you ensure the model remains interpretable enough to guide budget decisions across TV, digital, and in-store promotions?
Voice Commerce Strategy: With the rise of voice assistants, outline how an FMCG brand can optimize for voice search and ordering. How can natural language processing (NLP) be used to ensure the brand is recommended by voice assistants when consumers ask for a product category (like “buy milk”)?
Image Recognition in Retail: Propose a computer vision system that scans shelf images in retail stores to audit product placement and out-of-stock situations automatically. What training data would you need and what challenges might occlusion or lighting pose to your model?
Causal Inference in Promotions: Discuss how you might determine the true causal impact of a promotion on sales using machine learning. What methods (like uplift modeling or causal inference frameworks) could separate correlation from causation in FMCG promotions data?
Healthy Consumption Analytics: Many FMCGs are focusing on healthier products. How could data science analyze consumer consumption patterns to identify opportunities for healthier product development? Consider integrating data from fitness apps or public health databases in your prompt.
Emotion AI in Advertising: Explore the idea of using emotion recognition (from facial expressions or voice tone) to evaluate how consumers respond to ads or products. How feasible is this for FMCG brands in live environments (like testing ads via webcam)? What are the ethical boundaries?
Future Org Structure: Envision the organizational structure of a 2030 FMCG company where data science is fully integrated. What roles exist (chief AI officer? algorithm auditors?), and how do different departments collaborate with AI systems as part of daily work? Use this prompt to imagine the human-AI synergy in future FMCG teams.
In tackling these prompts, you stand at the intersection of cutting-edge AI technology and tangible business impact. The ideas and solutions you generate can catalyze new revenue streams, streamline operations, and redefine consumer experiences. More importantly, they can guide you toward a deeper understanding of how data science can be wielded responsibly and innovatively to build trust, deliver personalized value, and future-proof your organization in the fast-moving world of FMCG.
Here is a concise overview of the your assignments and how they integrate hands-on data science skills into real-world FMCG contexts. Each assignment guides you through the entire workflow of data collection, analysis, and business strategy—helping them build both technical expertise and managerial insight. By working through these projects, you can sharpen their ability to translate raw data into informed actions while also reflecting on ethical considerations in AI-driven campaigns.
By engaging with these assignments, you embark on a robust journey through data science in an FMCG setting—tackling marketing dashboards, forecasting complexities, consumer analytics, and supply chain puzzles while never losing sight of ethical responsibilities. Each project offers a stepping stone toward mastering the art and science of turning raw data into actionable insights that resonate with both internal decision-makers and the broader consumer audience.
🛠️ Assignments
📝 Assignment 1: Market Trends Dashboard
🎯 Objective:
This assignment aims to develop proficiency in real-time data visualization and rapid trend analysis within an FMCG context. You will learn how to ingest, clean, and present time-sensitive sales and social media data so that decision-makers can instantly spot emerging product trends and take immediate action.
📋 Task:
You receive a dataset combining daily sales figures for multiple products with social media engagement metrics (mentions, likes, sentiment scores) spanning several months. After performing initial data cleaning and normalization (for example, converting social media engagement into an indexed “buzz” score), design a dynamic dashboard that updates regularly to reflect the latest data. Highlight any abrupt spikes or drops in product interest using alerts or color-coded signals. Upon identifying a significant shift, write a concise report discussing why the shift might have occurred—perhaps a viral social media post or a new competitor release—and propose one or two operational responses. For instance, if a spike suggests demand will exceed current production, recommend scaling up manufacturing or expediting distribution to high-demand regions.
💡 Guidance:
Choose visualization tools that allow for real-time or near-real-time data refreshing. Demonstrate how different data filters (by region or product line) can help FMCG managers isolate the cause of a trend. Provide a thorough overview of potential outliers or anomalies (like an influencer-driven mention). Where possible, incorporate rudimentary forecasting features or short-term predictive signals so managers have a glimpse into how a spike or decline could evolve over the next few days. The final deliverable should include the dashboard itself, instructions on how it’s maintained or updated, and a brief analysis that underscores the power of immediate insight for operational decisions.
📝 Assignment 2: Predictive Demand Modeling
🎯 Objective:
This project focuses on enhancing your ability to handle forecasting problems with both classical and cutting-edge methods. It trains you to address seasonality, promotional events, and random externalities, simulating how real-world FMCG products often experience unpredictable fluctuations in demand.
📋 Task:
You receive historical sales data for a single product, including monthly or weekly sales volumes, promotional calendars, competitor actions (if applicable), and indicators of seasonality. Construct at least two forecasting models: one using a classical time-series approach (such as ARIMA, SARIMA, or exponential smoothing) and another using a more contemporary machine learning method (like gradient boosting or an LSTM-based neural network). Using a held-out sample, compare forecast accuracy (mean absolute error, RMSE, or MAPE). Then simulate a shock scenario where demand suddenly doubles for one month—perhaps due to an unexpected viral campaign. Demonstrate how each model adapts to this spike: does it quickly learn from the new data, or does it overreact? Finally, present a recommendation on which model the company should trust most under normal conditions versus high volatility, justifying the choice with metrics and observations.
💡 Guidance:
Discuss your feature engineering and data preprocessing steps, especially how you handle cyclical patterns like monthly seasonality or holiday effects. Include a debate on the interpretability of each model—executives in FMCG often require clarity on how a forecast is generated. The final report should outline strengths and limitations for each approach, with practical advice about how an FMCG supply chain or marketing team might deploy the chosen model for real-time or near-real-time forecasting.
📝 Assignment 3: Consumer Segmentation Project
🎯 Objective:
This project immerses you in the world of customer analytics by having you identify meaningful segments within a synthetic dataset of FMCG e-commerce transactions. The goal is to practice not only cluster analysis but also the strategic thinking required to craft targeted marketing initiatives.
📋 Task:
Using a dataset that includes customer demographics (age, location, household size), Browse behavior (pages visited, time on site), and past purchase data (SKUs purchased, frequency, spend), conduct a multi-step analysis. First, perform data cleaning, removing incomplete or erroneous records and standardizing scales. Second, apply at least one clustering algorithm (K-means, hierarchical clustering, or DBSCAN) to unearth distinct customer groups. After naming and describing each segment—perhaps “Healthy Living Enthusiasts” or “Budget-Oriented Families”—propose a targeted marketing strategy for each cluster. This could involve loyalty program perks, email campaign themes, product recommendations, or even specialized social media content.
💡 Guidance:
Be transparent about how you determined the optimal number of clusters, possibly referencing the elbow method or silhouette scores. Clearly profile each segment by highlighting average spend, product category preferences, or times of day they tend to shop. A strong assignment deliverable includes a short white paper explaining how an FMCG marketing team could implement the recommendations, linking each segment strategy to measurable KPIs (like increased basket size or reduced churn).
📝 Assignment 4: Supply Chain Optimization Case
🎯 Objective:
This assignment brings inventory management concepts into real-world FMCG decision-making. You will hone skills in balancing cost, risk, and service levels, learning to manipulate reorder points and safety stock based on data-driven insights.
📋 Task:
You receive simplified yet realistic supply chain details for one FMCG product: production lead times, current warehouse stock, historical demand patterns, target service levels, and per-unit storage costs. Calculate the optimal reorder point and safety stock, using formulas or algorithms that account for demand variability and lead time uncertainties. Then conduct a what-if scenario by increasing the standard deviation of demand by 20%, determining how this shift affects optimal safety stock and reorder points. Finally, deliver a recommendation on whether the company should invest in extra safety stock or adopt a just-in-time strategy. Consider additional complexities such as dynamic lead times or volume discounts where applicable.
💡 Guidance:
Articulate assumptions about demand distributions or carrying costs, referencing standard operations research equations (like the Newsvendor model) or simulation approaches. A robust solution includes sensitivity analyses—showing how changes in cost or service-level requirements might alter final inventory policies. The assignment deliverable is often a briefing document or presentation that persuades an “executive committee” of the feasibility and benefits of the recommended policy.
📝 Assignment 5: Ethical AI Review
🎯 Objective:
This assignment confronts the ethical implications of deploying AI in FMCG contexts, honing your ability to anticipate public reaction, navigate biases, and enforce transparency. It fosters both critical thinking and policy-writing skills.
📋 Task:
You are given a fictional case study where a brand uses AI-driven microtargeting in a marketing campaign. The campaign misfires when consumers discover that the AI segments them by sensitive personal attributes (possibly inferring socio-economic status), causing backlash on social media. Your job is to analyze the root causes—did the training data incorporate biased features? Were privacy consents overlooked? Did the brand fail to explain its AI usage sufficiently? Then draft a concise redesign of the campaign’s data strategy, proposing specific remedies: removing sensitive attributes from the model, implementing an opt-out mechanism, or mandating human review of automated recommendations. The final output includes practical guidelines for marketing teams, including references to relevant regulations and best practices.
💡 Guidance:
Draw on real-world ethics frameworks or compliance guidelines (like GDPR or consumer privacy regulations), demonstrating how these apply to data-driven campaigns. Weigh potential trade-offs: restricting data collection might reduce personalization accuracy, but it also mitigates reputational risk. A strong submission references fairness concepts (such as ensuring the model does not systematically exclude or disadvantage certain groups) and outlines a process for continuous monitoring to catch bias or privacy issues early.
Working through these assignments presents a robust tour of data science in an FMCG setting—tackling marketing dashboards, forecasting complexities, consumer analytics, and supply chain puzzles while never losing sight of ethical responsibilities. By exploring both technical and managerial dimensions, students gain a well-rounded view of how real-world analytics can accelerate business performance. Each project offers a stepping stone toward mastering the art and science of turning raw data into actionable insights that resonate with both internal decision-makers and the broader consumer audience.
Comments